 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTICON: A Slide-Level Tile Contextualizer for Histopathology Representation Learning
Dec 24, 2025The interpretation of small tiles in large whole slide images (WSI) often needs a larger image context. We introduce TICON, a transformer-based tile representation contextualizer that produces rich, contextualized embeddings for ''any'' application in computational pathology. Standard tile encoder-based pipelines, which extract embeddings of tiles stripped from their context, fail to model the rich slide-level information essential for both local and global tasks. Furthermore, different tile-encoders excel at different downstream tasks. Therefore, a unified model is needed to contextualize embeddings derived from ''any'' tile-level foundation model. TICON addresses this need with a single, shared encoder, pretrained using a masked modeling objective to simultaneously unify and contextualize representations from diverse tile-level pathology foundation models. Our experiments demonstrate that TICON-contextualized embeddings significantly improve performance across many different tasks, establishing new state-of-the-art results on tile-level benchmarks (i.e., HEST-Bench, THUNDER, CATCH) and slide-level benchmarks (i.e., Patho-Bench). Finally, we pretrain an aggregator on TICON to form a slide-level foundation model, using only 11K WSIs, outperforming SoTA slide-level foundation models pretrained with up to 350K WSIs.
PixCell: A generative foundation model for digital histopathology images
Jun 05, 2025The digitization of histology slides has revolutionized pathology, providing massive datasets for cancer diagnosis and research. Contrastive self-supervised and vision-language models have been shown to effectively mine large pathology datasets to learn discriminative representations. On the other hand, generative models, capable of synthesizing realistic and diverse images, present a compelling solution to address unique problems in pathology that involve synthesizing images; overcoming annotated data scarcity, enabling privacy-preserving data sharing, and performing inherently generative tasks, such as virtual staining. We introduce PixCell, the first diffusion-based generative foundation model for histopathology. We train PixCell on PanCan-30M, a vast, diverse dataset derived from 69,184 H\&E-stained whole slide images covering various cancer types. We employ a progressive training strategy and a self-supervision-based conditioning that allows us to scale up training without any annotated data. PixCell generates diverse and high-quality images across multiple cancer types, which we find can be used in place of real data to train a self-supervised discriminative model. Synthetic images shared between institutions are subject to fewer regulatory barriers than would be the case with real clinical images. Furthermore, we showcase the ability to precisely control image generation using a small set of annotated images, which can be used for both data augmentation and educational purposes. Testing on a cell segmentation task, a mask-guided PixCell enables targeted data augmentation, improving downstream performance. Finally, we demonstrate PixCell's ability to use H\&E structural staining to infer results from molecular marker studies; we use this capability to infer IHC staining from H\&E images. Our trained models are publicly released to accelerate research in computational pathology.
Gen-SIS: Generative Self-augmentation Improves Self-supervised Learning
Dec 02, 2024



Self-supervised learning (SSL) methods have emerged as strong visual representation learners by training an image encoder to maximize similarity between features of different views of the same image. To perform this view-invariance task, current SSL algorithms rely on hand-crafted augmentations such as random cropping and color jittering to create multiple views of an image. Recently, generative diffusion models have been shown to improve SSL by providing a wider range of data augmentations. However, these diffusion models require pre-training on large-scale image-text datasets, which might not be available for many specialized domains like histopathology. In this work, we introduce Gen-SIS, a diffusion-based augmentation technique trained exclusively on unlabeled image data, eliminating any reliance on external sources of supervision such as text captions. We first train an initial SSL encoder on a dataset using only hand-crafted augmentations. We then train a diffusion model conditioned on embeddings from that SSL encoder. Following training, given an embedding of the source image, this diffusion model can synthesize its diverse views. We show that these `self-augmentations', i.e. generative augmentations based on the vanilla SSL encoder embeddings, facilitate the training of a stronger SSL encoder. Furthermore, based on the ability to interpolate between images in the encoder latent space, we introduce the novel pretext task of disentangling the two source images of an interpolated synthetic image. We validate Gen-SIS's effectiveness by demonstrating performance improvements across various downstream tasks in both natural images, which are generally object-centric, as well as digital histopathology images, which are typically context-based.
Crossway Diffusion: Improving Diffusion-based Visuomotor Policy via Self-supervised Learning
Jul 04, 2023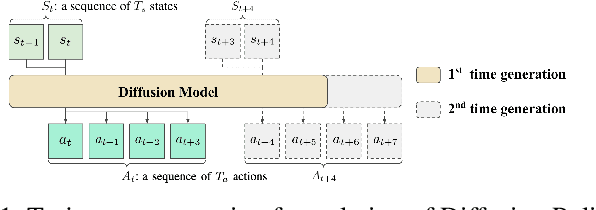

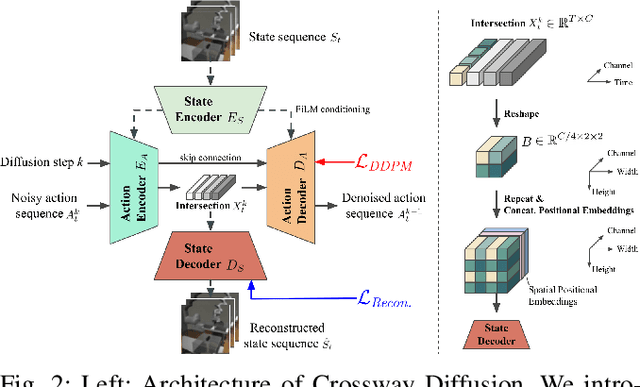

Sequence modeling approaches have shown promising results in robot imitation learning. Recently, diffusion models have been adopted for behavioral cloning, benefiting from their exceptional capabilities in modeling complex data distribution. In this work, we propose Crossway Diffusion, a method to enhance diffusion-based visuomotor policy learning by using an extra self-supervised learning (SSL) objective. The standard diffusion-based policy generates action sequences from random noise conditioned on visual observations and other low-dimensional states. We further extend this by introducing a new decoder that reconstructs raw image pixels (and other state information) from the intermediate representations of the reverse diffusion process, and train the model jointly using the SSL loss. Our experiments demonstrate the effectiveness of Crossway Diffusion in various simulated and real-world robot tasks, confirming its advantages over the standard diffusion-based policy. We demonstrate that such self-supervised reconstruction enables better representation for policy learning, especially when the demonstrations have different proficiencies.
An error correction scheme for improved air-tissue boundary in real-time MRI video for speech production
Mar 09, 2022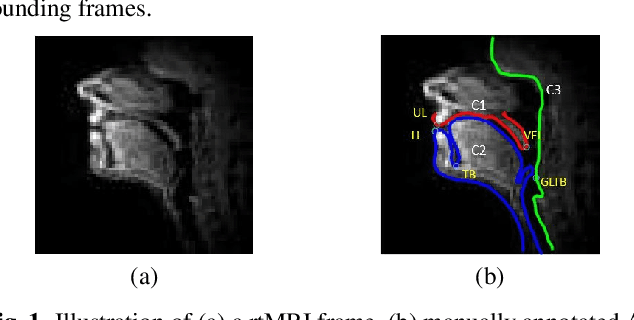

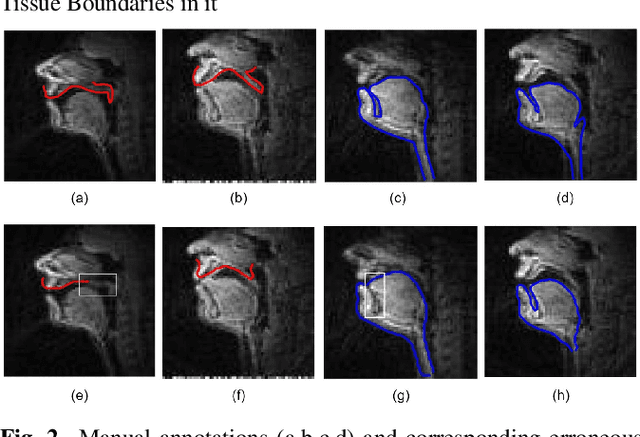
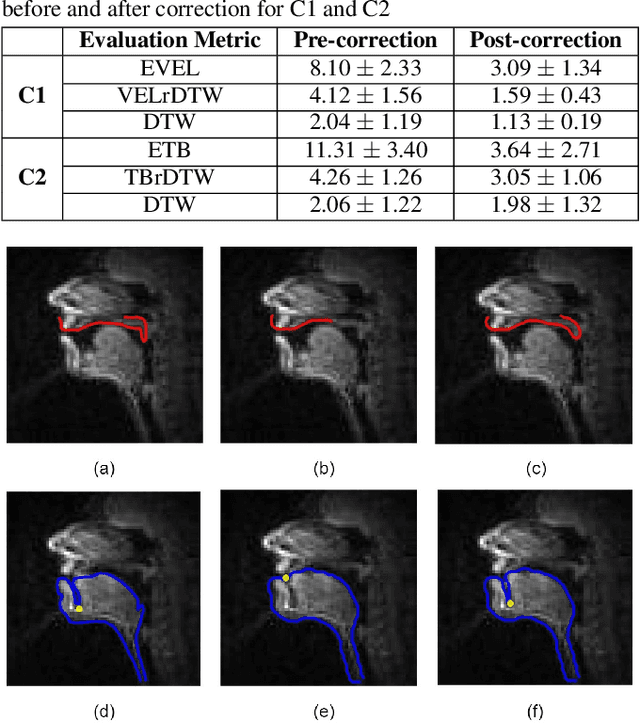
The best performance in Air-tissue boundary (ATB) segmentation of real-time Magnetic Resonance Imaging (rtMRI) videos in speech production is known to be achieved by a 3-dimensional convolutional neural network (3D-CNN) model. However, the evaluation of this model, as well as other ATB segmentation techniques reported in the literature, is done using Dynamic Time Warping (DTW) distance between the entire original and predicted contours. Such an evaluation measure may not capture local errors in the predicted contour. Careful analysis of predicted contours reveals errors in regions like the velum part of contour1 (ATB comprising of upper lip, hard palate, and velum) and tongue base section of contour2 (ATB covering jawline, lower lip, tongue base, and epiglottis), which are not captured in a global evaluation metric like DTW distance. In this work, we automatically detect such errors and propose a correction scheme for the same. We also propose two new evaluation metrics for ATB segmentation separately in contour1 and contour2 to explicitly capture two types of errors in these contours. The proposed detection and correction strategies result in an improvement of these two evaluation metrics by 61.8% and 61.4% for contour1 and by 67.8% and 28.4% for contour2. Traditional DTW distance, on the other hand, improves by 44.6% for contour1 and 4.0% for contour2.