 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn approach to measuring the performance of Automatic Speech Recognition (ASR) models in the context of Large Language Model (LLM) powered applications
Jul 22, 2025Automatic Speech Recognition (ASR) plays a crucial role in human-machine interaction and serves as an interface for a wide range of applications. Traditionally, ASR performance has been evaluated using Word Error Rate (WER), a metric that quantifies the number of insertions, deletions, and substitutions in the generated transcriptions. However, with the increasing adoption of large and powerful Large Language Models (LLMs) as the core processing component in various applications, the significance of different types of ASR errors in downstream tasks warrants further exploration. In this work, we analyze the capabilities of LLMs to correct errors introduced by ASRs and propose a new measure to evaluate ASR performance for LLM-powered applications.
Discovering phoneme-specific critical articulators through a data-driven approach
Apr 15, 2025We propose an approach for learning critical articulators for phonemes through a machine learning approach. We formulate the learning with three models trained end to end. First, we use Acoustic to Articulatory Inversion (AAI) to predict time-varying speech articulators EMA. We also predict the phoneme-specific weights across articulators for each frame. To avoid overfitting, we also add a dropout layer before the weights prediction layer. Next, we normalize the predicted weights across articulators using min-max normalization for each frame. The normalized weights are multiplied by the ground truth $EMA$ and then we try to predict the phones at each frame. We train this whole setup end to end and use two losses. One loss is for the phone prediction which is the cross entropy loss and the other is for the AAI prediction which is the mean squared error loss. To maintain gradient flow between the phone prediction block and the $EMA$ prediction block, we use straight-through estimation. The goal here is to predict the weights of the articulator at each frame while training the model end to end.
Role of the Pretraining and the Adaptation data sizes for low-resource real-time MRI video segmentation
Feb 20, 2025



Real-time Magnetic Resonance Imaging (rtMRI) is frequently used in speech production studies as it provides a complete view of the vocal tract during articulation. This study investigates the effectiveness of rtMRI in analyzing vocal tract movements by employing the SegNet and UNet models for Air-Tissue Boundary (ATB)segmentation tasks. We conducted pretraining of a few base models using increasing numbers of subjects and videos, to assess performance on two datasets. First, consisting of unseen subjects with unseen videos from the same data source, achieving 0.33% and 0.91% (Pixel-wise Classification Accuracy (PCA) and Dice Coefficient respectively) better than its matched condition. Second, comprising unseen videos from a new data source, where we obtained an accuracy of 99.63% and 98.09% (PCA and Dice Coefficient respectively) of its matched condition performance. Here, matched condition performance refers to the performance of a model trained only on the test subjects which was set as a benchmark for the other models. Our findings highlight the significance of fine-tuning and adapting models with limited data. Notably, we demonstrated that effective model adaptation can be achieved with as few as 15 rtMRI frames from any new dataset.
SPIRE-SIES: A Spontaneous Indian English Speech Corpus
Dec 01, 2023


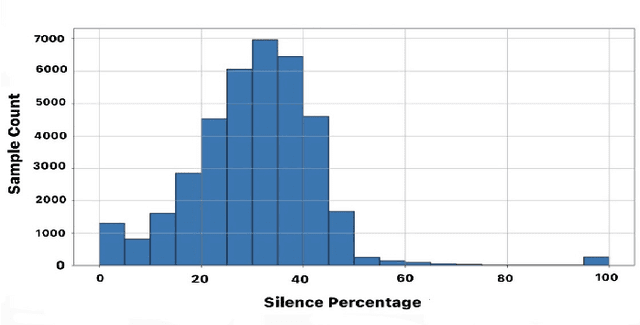
In this paper, we present a 170.83 hour Indian English spontaneous speech dataset. Lack of Indian English speech data is one of the major hindrances in developing robust speech systems which are adapted to the Indian speech style. Moreover this scarcity is even more for spontaneous speech. This corpus is crowd sourced over varied Indian nativities, genders and age groups. Traditional spontaneous speech collection strategies involve capturing of speech during interviewing or conversations. In this study, we use images as stimuli to induce spontaneity in speech. Transcripts for 23 hours is generated and validated which can serve as a spontaneous speech ASR benchmark. Quality of the corpus is validated with voice activity detection based segmentation, gender verification and image semantic correlation. Which determines a relationship between image stimulus and recorded speech using caption keywords derived from Image2Text model and high occurring words derived from whisper ASR generated transcripts.
Speaking rate attention-based duration prediction for speed control TTS
Oct 13, 2023With the advent of high-quality speech synthesis, there is a lot of interest in controlling various prosodic attributes of speech. Speaking rate is an essential attribute towards modelling the expressivity of speech. In this work, we propose a novel approach to control the speaking rate for non-autoregressive TTS. We achieve this by conditioning the speaking rate inside the duration predictor, allowing implicit speaking rate control. We show the benefits of this approach by synthesising audio at various speaking rate factors and measuring the quality of speaking rate-controlled synthesised speech. Further, we study the effect of the speaking rate distribution of the training data towards effective rate control. Finally, we fine-tune a baseline pretrained TTS model to obtain speaking rate control TTS. We provide various analyses to showcase the benefits of using this proposed approach, along with objective as well as subjective metrics. We find that the proposed methods have higher subjective scores and lower speaker rate errors across many speaking rate factors over the baseline.
Model Adaptation for ASR in low-resource Indian Languages
Jul 16, 2023Automatic speech recognition (ASR) performance has improved drastically in recent years, mainly enabled by self-supervised learning (SSL) based acoustic models such as wav2vec2 and large-scale multi-lingual training like Whisper. A huge challenge still exists for low-resource languages where the availability of both audio and text is limited. This is further complicated by the presence of multiple dialects like in Indian languages. However, many Indian languages can be grouped into the same families and share the same script and grammatical structure. This is where a lot of adaptation and fine-tuning techniques can be applied to overcome the low-resource nature of the data by utilising well-resourced similar languages. In such scenarios, it is important to understand the extent to which each modality, like acoustics and text, is important in building a reliable ASR. It could be the case that an abundance of acoustic data in a language reduces the need for large text-only corpora. Or, due to the availability of various pretrained acoustic models, the vice-versa could also be true. In this proposed special session, we encourage the community to explore these ideas with the data in two low-resource Indian languages of Bengali and Bhojpuri. These approaches are not limited to Indian languages, the solutions are potentially applicable to various languages spoken around the world.
Analysis of vocal breath sounds before and after administering Bronchodilator in Asthmatic patients
Apr 29, 2023Asthma is one of the chronic inflammatory diseases of the airways, which causes chest tightness, wheezing, breathlessness, and cough. Spirometry is an effort-dependent test used to monitor and diagnose lung conditions like Asthma. Vocal breath sound (VBS) based analysis can be an alternative to spirometry as VBS characteristics change depending on the lung condition. VBS test consumes less time, and it also requires less effort, unlike spirometry. In this work, VBS characteristics are analyzed before and after administering bronchodilator in a subject-dependent manner using linear discriminant analysis (LDA). We find that features learned through LDA show a significant difference between VBS recorded before and after administering bronchodilator in all 30 subjects considered in this work, whereas the baseline features could achieve a significant difference between VBS only for 26 subjects. We also observe that all frequency ranges do not contribute equally to the discrimination between pre and post bronchodilator conditions. From experiments, we find that two frequency ranges, namely 400-500Hz and 1480-1900Hz, maximally contribute to the discrimination of all the subjects. The study presented in this paper analyzes the pre and post-bronchodilator effect on the inhalation sound recorded at the mouth in a subject-dependent manner. The findings of this work suggest that, inhalation sound recorded at mouth can be a good stimulus to discriminate pre and post-bronchodilator conditions in asthmatic subjects. Inhale sound-based pre and post-bronchodilator discrimination can be of potential use in clinical settings.
An unsupervised segmentation of vocal breath sounds
Apr 07, 2023Breathing is an essential part of human survival, which carries information about a person's physiological and psychological state. Generally, breath boundaries are marked by experts before using for any task. An unsupervised algorithm for breath boundary detection has been proposed for breath sounds recorded at the mouth also referred as vocal breath sounds (VBS) in this work. Breath sounds recorded at the mouth are used in this work because they are easy and contactless to record than tracheal breath sounds and lung breath sounds. The periodic nature of breath signal energy is used to segment the breath boundaries. Dynamic programming with the prior information of the number of breath phases($P$) and breath phase duration($d$) is used to find the boundaries. In this work, 367 breath boundaries from 60 subjects (31 healthy, 29 patients) having 307 breaths are predicted. With the proposed method, M ($89\%$), I ($13\%$), D ($11\%$) and S ($79\%$) is found. The proposed method shows better performance than the baselines used in this work. Even the classification performance between asthmatic and healthy subjects using estimated boundaries by the proposed method is comparable with the ground truth boundaries.
Vocal Breath Sound Based Gender Classification
Nov 11, 2022Voiced speech signals such as continuous speech are known to have acoustic features such as pitch(F0), and formant frequencies(F1, F2, F3) which can be used for gender classification. However, gender classification studies using non-speech signals such as vocal breath sounds have not been explored as they lack typical gender-specific acoustic features. In this work, we explore whether vocal breath sounds encode gender information and if so, to what extent it can be used for automatic gender classification. In this study, we explore the use of data-driven and knowledge-based features from vocal breath sounds as well as the classifier complexity for gender classification. We also explore the importance of the location and duration of breath signal segments to be used for automatic classification. Experiments with 54.23 minutes of male and 51.83 minutes of female breath sounds reveal that knowledge-based features, namely MFCC statistics, with low-complexity classifier perform comparably to the data-driven features with classifiers of higher complexity. Breath segments with an average duration of 3 seconds are found to be the best choice irrespective of the location which avoids the need for breath cycle boundary annotation.
Improved acoustic-to-articulatory inversion using representations from pretrained self-supervised learning models
Oct 30, 2022



In this work, we investigate the effectiveness of pretrained Self-Supervised Learning (SSL) features for learning the mapping for acoustic to articulatory inversion (AAI). Signal processing-based acoustic features such as MFCCs have been predominantly used for the AAI task with deep neural networks. With SSL features working well for various other speech tasks such as speech recognition, emotion classification, etc., we experiment with its efficacy for AAI. We train on SSL features with transformer neural networks-based AAI models of 3 different model complexities and compare its performance with MFCCs in subject-specific (SS), pooled and fine-tuned (FT) configurations with data from 10 subjects, and evaluate with correlation coefficient (CC) score on the unseen sentence test set. We find that acoustic feature reconstruction objective-based SSL features such as TERA and DeCoAR work well for AAI, with SS CCs of these SSL features reaching close to the best FT CCs of MFCC. We also find the results consistent across different model sizes.