 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRE-SIES: A Spontaneous Indian English Speech Corpus
Paper and Code



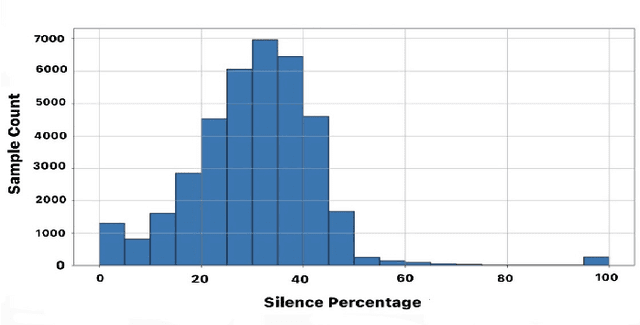
In this paper, we present a 170.83 hour Indian English spontaneous speech dataset. Lack of Indian English speech data is one of the major hindrances in developing robust speech systems which are adapted to the Indian speech style. Moreover this scarcity is even more for spontaneous speech. This corpus is crowd sourced over varied Indian nativities, genders and age groups. Traditional spontaneous speech collection strategies involve capturing of speech during interviewing or conversations. In this study, we use images as stimuli to induce spontaneity in speech. Transcripts for 23 hours is generated and validated which can serve as a spontaneous speech ASR benchmark. Quality of the corpus is validated with voice activity detection based segmentation, gender verification and image semantic correlation. Which determines a relationship between image stimulus and recorded speech using caption keywords derived from Image2Text model and high occurring words derived from whisper ASR generated transcripts.