 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAANI: Capturing the language landscape for an inclusive digital India
Mar 31, 2026Project VAANI is an initiative to create an India-representative multi-modal dataset that comprehensively maps India's linguistic diversity, starting with 165 districts across the country in its first two phases. Speech data is collected through a carefully structured process that uses image-based prompts to encourage spontaneous responses. Images are captured through a separate process that encompasses a broad range of topics, gathered from both within and across districts. The collected data undergoes a rigorous multi-stage quality evaluation, including both automated and manual checks to ensure highest possible standards in audio quality and transcription accuracy. Following this thorough validation, we have open-sourced around 289K images, approximately 31,270 hours of audio recordings, and around 2,067 hours of transcribed speech, encompassing 112 languages from 165 districts from 31 States and Union territories. Notably, significant of these languages are being represented for the first time in a dataset of this scale, making the VAANI project a groundbreaking effort in preserving and promoting linguistic inclusivity. This data can be instrumental in building inclusive speech models for India, and in advancing research and development across speech, image, and multimodal applications.
SPIRE-SIES: A Spontaneous Indian English Speech Corpus
Dec 01, 2023


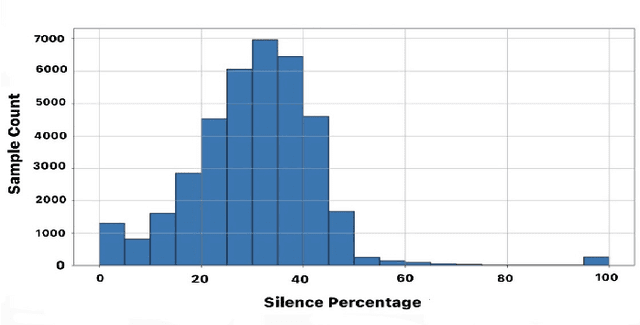
In this paper, we present a 170.83 hour Indian English spontaneous speech dataset. Lack of Indian English speech data is one of the major hindrances in developing robust speech systems which are adapted to the Indian speech style. Moreover this scarcity is even more for spontaneous speech. This corpus is crowd sourced over varied Indian nativities, genders and age groups. Traditional spontaneous speech collection strategies involve capturing of speech during interviewing or conversations. In this study, we use images as stimuli to induce spontaneity in speech. Transcripts for 23 hours is generated and validated which can serve as a spontaneous speech ASR benchmark. Quality of the corpus is validated with voice activity detection based segmentation, gender verification and image semantic correlation. Which determines a relationship between image stimulus and recorded speech using caption keywords derived from Image2Text model and high occurring words derived from whisper ASR generated transcripts.
Speaking rate attention-based duration prediction for speed control TTS
Oct 13, 2023With the advent of high-quality speech synthesis, there is a lot of interest in controlling various prosodic attributes of speech. Speaking rate is an essential attribute towards modelling the expressivity of speech. In this work, we propose a novel approach to control the speaking rate for non-autoregressive TTS. We achieve this by conditioning the speaking rate inside the duration predictor, allowing implicit speaking rate control. We show the benefits of this approach by synthesising audio at various speaking rate factors and measuring the quality of speaking rate-controlled synthesised speech. Further, we study the effect of the speaking rate distribution of the training data towards effective rate control. Finally, we fine-tune a baseline pretrained TTS model to obtain speaking rate control TTS. We provide various analyses to showcase the benefits of using this proposed approach, along with objective as well as subjective metrics. We find that the proposed methods have higher subjective scores and lower speaker rate errors across many speaking rate factors over the baseline.
Model Adaptation for ASR in low-resource Indian Languages
Jul 16, 2023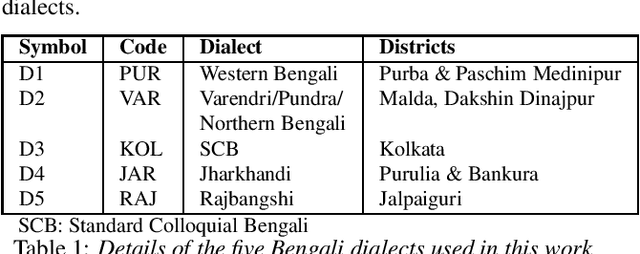

Automatic speech recognition (ASR) performance has improved drastically in recent years, mainly enabled by self-supervised learning (SSL) based acoustic models such as wav2vec2 and large-scale multi-lingual training like Whisper. A huge challenge still exists for low-resource languages where the availability of both audio and text is limited. This is further complicated by the presence of multiple dialects like in Indian languages. However, many Indian languages can be grouped into the same families and share the same script and grammatical structure. This is where a lot of adaptation and fine-tuning techniques can be applied to overcome the low-resource nature of the data by utilising well-resourced similar languages. In such scenarios, it is important to understand the extent to which each modality, like acoustics and text, is important in building a reliable ASR. It could be the case that an abundance of acoustic data in a language reduces the need for large text-only corpora. Or, due to the availability of various pretrained acoustic models, the vice-versa could also be true. In this proposed special session, we encourage the community to explore these ideas with the data in two low-resource Indian languages of Bengali and Bhojpuri. These approaches are not limited to Indian languages, the solutions are potentially applicable to various languages spoken around the world.
A study on native American English speech recognition by Indian listeners with varying word familiarity level
Dec 08, 2021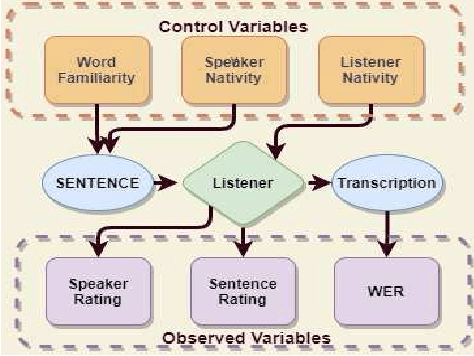
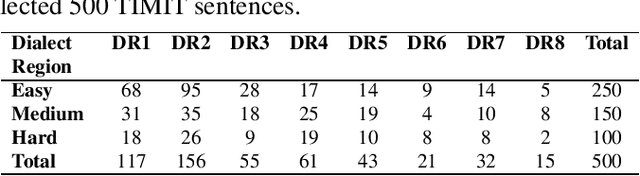
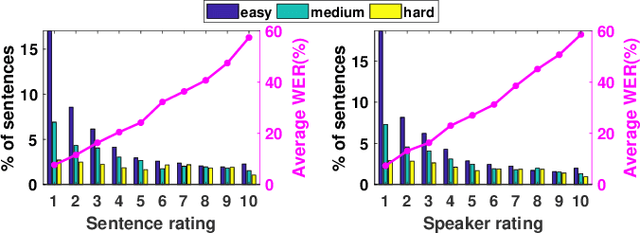
In this study, listeners of varied Indian nativities are asked to listen and recognize TIMIT utterances spoken by American speakers. We have three kinds of responses from each listener while they recognize an utterance: 1. Sentence difficulty ratings, 2. Speaker difficulty ratings, and 3. Transcription of the utterance. From these transcriptions, word error rate (WER) is calculated and used as a metric to evaluate the similarity between the recognized and the original sentences.The sentences selected in this study are categorized into three groups: Easy, Medium and Hard, based on the frequency ofoccurrence of the words in them. We observe that the sentence, speaker difficulty ratings and the WERs increase from easy to hard categories of sentences. We also compare the human speech recognition performance with that using three automatic speech recognition (ASR) under following three combinations of acoustic model (AM) and language model(LM): ASR1) AM trained with recordings from speakers of Indian origin and LM built on TIMIT text, ASR2) AM using recordings from native American speakers and LM built ontext from LIBRI speech corpus, and ASR3) AM using recordings from native American speakers and LM build on LIBRI speech and TIMIT text. We observe that HSR performance is similar to that of ASR1 whereas ASR3 achieves the best performance. Speaker nativity wise analysis shows that utterances from speakers of some nativity are more difficult to recognize by Indian listeners compared to few other nativities
Estimating articulatory movements in speech production with transformer networks
Apr 11, 2021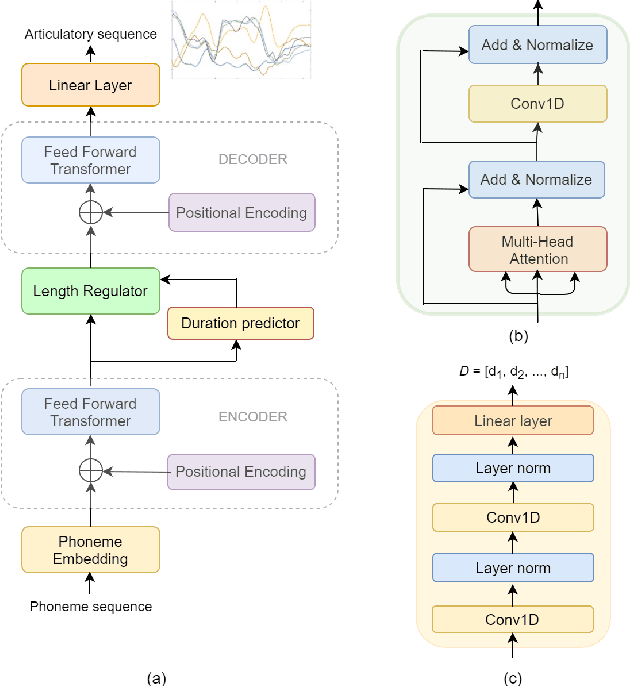
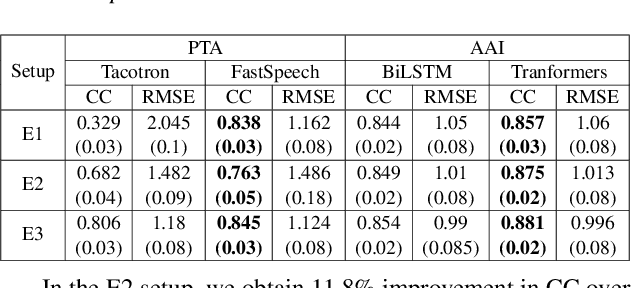
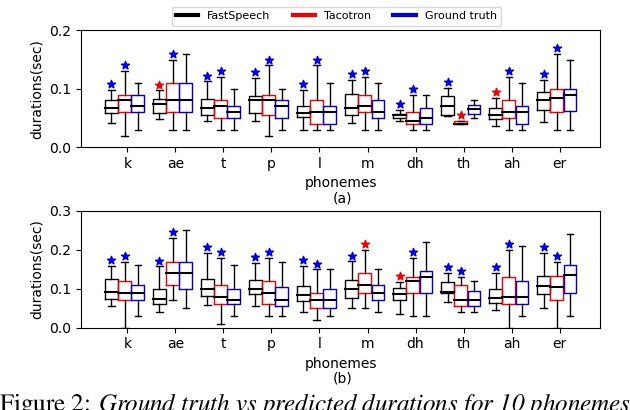
We estimate articulatory movements in speech production from different modalities - acoustics and phonemes. Acoustic-to articulatory inversion (AAI) is a sequence-to-sequence task. On the other hand, phoneme to articulatory (PTA) motion estimation faces a key challenge in reliably aligning the text and the articulatory movements. To address this challenge, we explore the use of a transformer architecture - FastSpeech, with explicit duration modelling to learn hard alignments between the phonemes and articulatory movements. We also train a transformer model on AAI. We use correlation coefficient (CC) and root mean squared error (rMSE) to assess the estimation performance in comparison to existing methods on both tasks. We observe 154%, 11.8% & 4.8% relative improvement in CC with subject-dependent, pooled and fine-tuning strategies, respectively, for PTA estimation. Additionally, on the AAI task, we obtain 1.5%, 3% and 3.1% relative gain in CC on the same setups compared to the state-of-the-art baseline. We further present the computational benefits of having transformer architecture as representation blocks.
Attention and Encoder-Decoder based models for transforming articulatory movements at different speaking rates
Jun 04, 2020
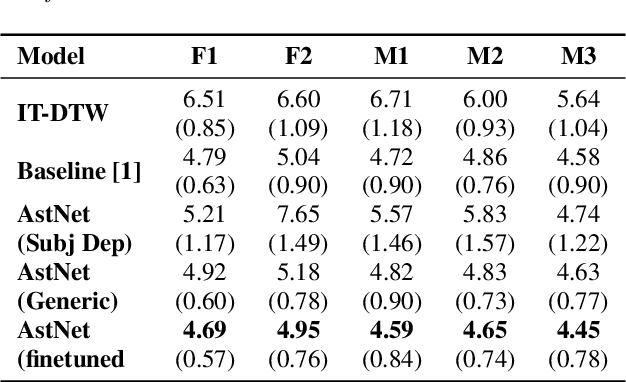
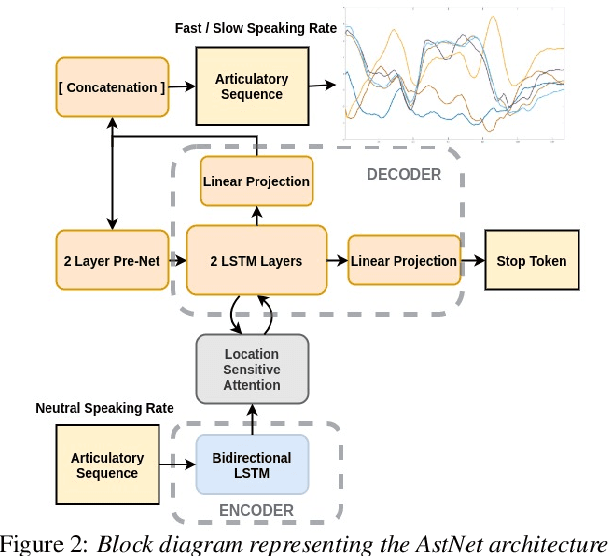
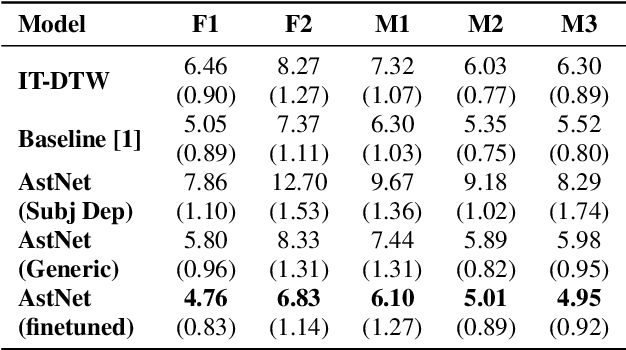
While speaking at different rates, articulators (like tongue, lips) tend to move differently and the enunciations are also of different durations. In the past, affine transformation and DNN have been used to transform articulatory movements from neutral to fast(N2F) and neutral to slow(N2S) speaking rates [1]. In this work, we improve over the existing transformation techniques by modeling rate specific durations and their transformation using AstNet, an encoder-decoder framework with attention. In the current work, we propose an encoder-decoder architecture using LSTMs which generates smoother predicted articulatory trajectories. For modeling duration variations across speaking rates, we deploy attention network, which eliminates the needto align trajectories in different rates using DTW. We performa phoneme specific duration analysis to examine how well duration is transformed using the proposed AstNet. As the range of articulatory motions is correlated with speaking rate, we also analyze amplitude of the transformed articulatory movements at different rates compared to their original counterparts, to examine how well the proposed AstNet predicts the extent of articulatory movements in N2F and N2S. We observe that AstNet could model both duration and extent of articulatory movements better than the existing transformation techniques resulting in more accurate transformed articulatory trajectories.
A comparative study of estimating articulatory movements from phoneme sequences and acoustic features
Oct 31, 2019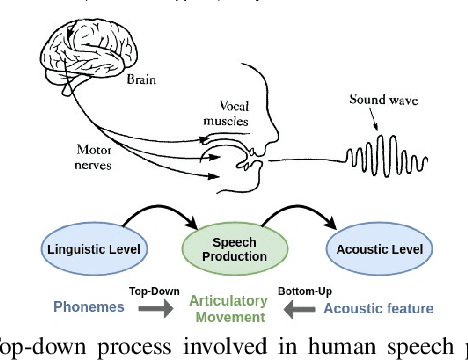
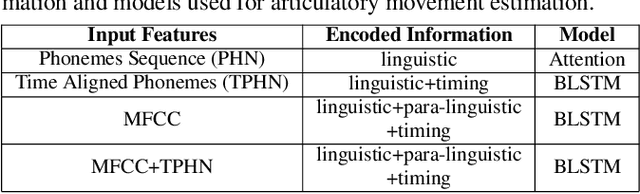
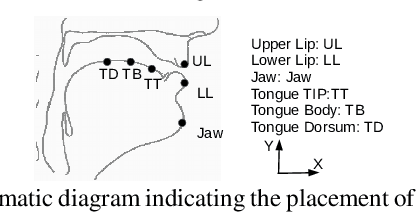
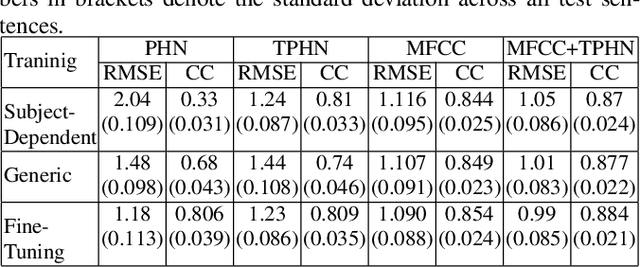
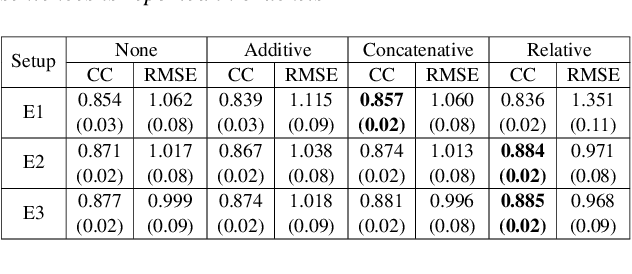
Unlike phoneme sequences, movements of speech articulators (lips, tongue, jaw, velum) and the resultant acoustic signal are known to encode not only the linguistic message but also carry para-linguistic information. While several works exist for estimating articulatory movement from acoustic signals, little is known to what extent articulatory movements can be predicted only from linguistic information, i.e., phoneme sequence. In this work, we estimate articulatory movements from three different input representations: R1) acoustic signal, R2) phoneme sequence, R3) phoneme sequence with timing information. While an attention network is used for estimating articulatory movement in the case of R2, BLSTM network is used for R1 and R3. Experiments with ten subjects' acoustic-articulatory data reveal that the estimation techniques achieve an average correlation coefficient of 0.85, 0.81, and 0.81 in the case of R1, R2, and R3 respectively. This indicates that attention network, although uses only phoneme sequence (R2) without any timing information, results in an estimation performance similar to that using rich acoustic signal (R1), suggesting that articulatory motion is primarily driven by the linguistic message. The correlation coefficient is further improved to 0.88 when R1 and R3 are used together for estimating articulatory movements.