 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention and Encoder-Decoder based models for transforming articulatory movements at different speaking rates
Paper and Code
Jun 04, 2020
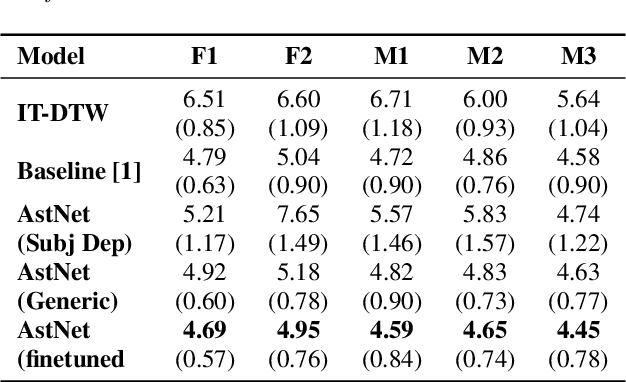
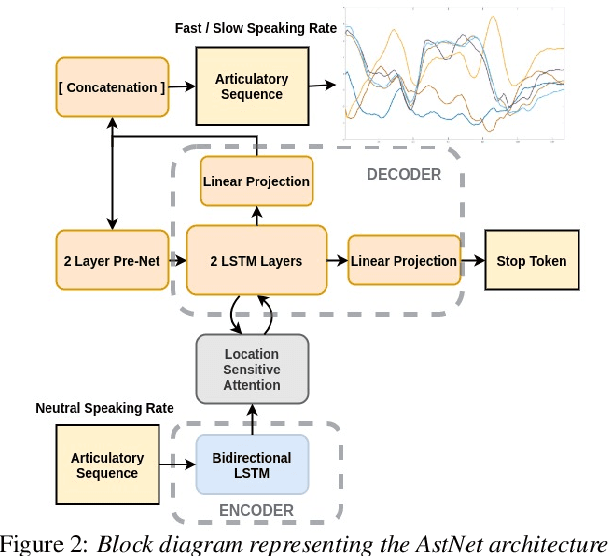
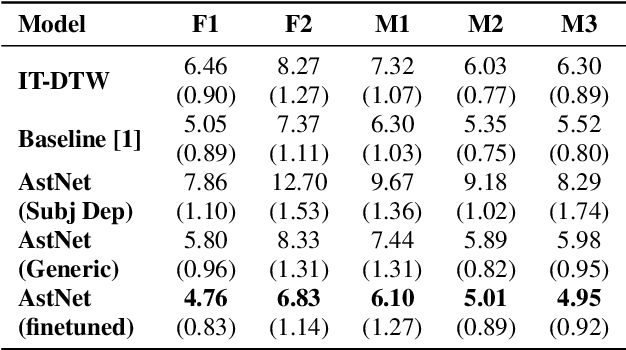
While speaking at different rates, articulators (like tongue, lips) tend to move differently and the enunciations are also of different durations. In the past, affine transformation and DNN have been used to transform articulatory movements from neutral to fast(N2F) and neutral to slow(N2S) speaking rates [1]. In this work, we improve over the existing transformation techniques by modeling rate specific durations and their transformation using AstNet, an encoder-decoder framework with attention. In the current work, we propose an encoder-decoder architecture using LSTMs which generates smoother predicted articulatory trajectories. For modeling duration variations across speaking rates, we deploy attention network, which eliminates the needto align trajectories in different rates using DTW. We performa phoneme specific duration analysis to examine how well duration is transformed using the proposed AstNet. As the range of articulatory motions is correlated with speaking rate, we also analyze amplitude of the transformed articulatory movements at different rates compared to their original counterparts, to examine how well the proposed AstNet predicts the extent of articulatory movements in N2F and N2S. We observe that AstNet could model both duration and extent of articulatory movements better than the existing transformation techniques resulting in more accurate transformed articulatory trajectories.