 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating articulatory movements in speech production with transformer networks
Apr 11, 2021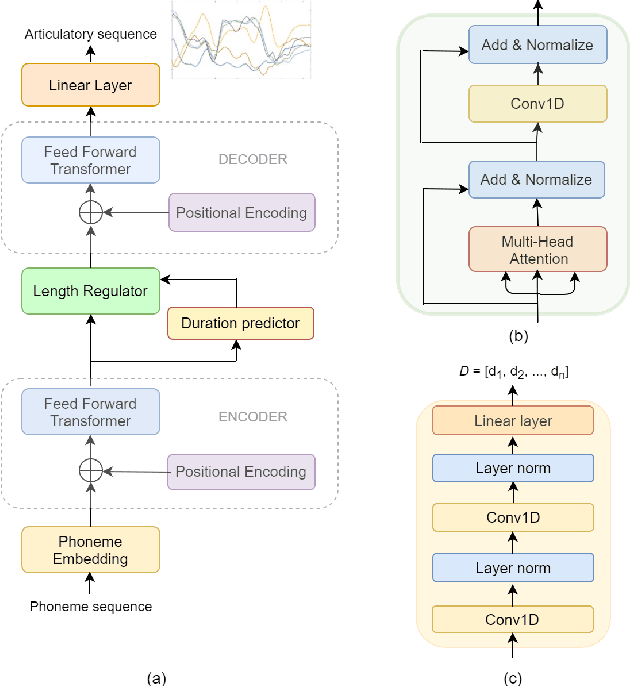
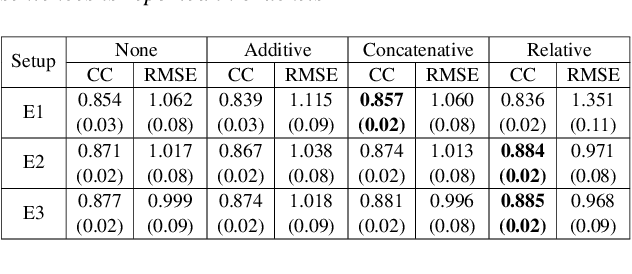
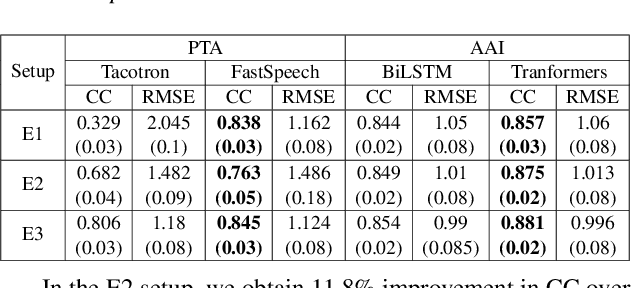
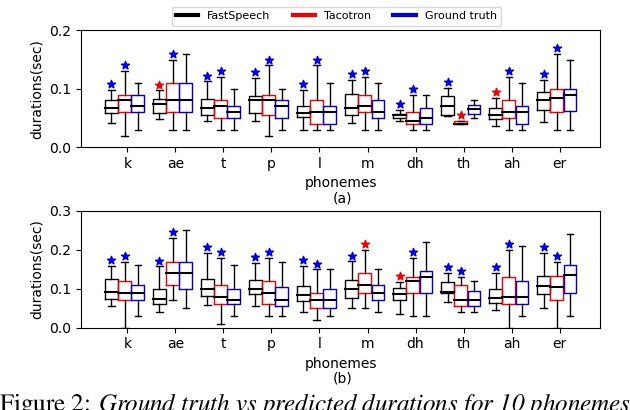
We estimate articulatory movements in speech production from different modalities - acoustics and phonemes. Acoustic-to articulatory inversion (AAI) is a sequence-to-sequence task. On the other hand, phoneme to articulatory (PTA) motion estimation faces a key challenge in reliably aligning the text and the articulatory movements. To address this challenge, we explore the use of a transformer architecture - FastSpeech, with explicit duration modelling to learn hard alignments between the phonemes and articulatory movements. We also train a transformer model on AAI. We use correlation coefficient (CC) and root mean squared error (rMSE) to assess the estimation performance in comparison to existing methods on both tasks. We observe 154%, 11.8% & 4.8% relative improvement in CC with subject-dependent, pooled and fine-tuning strategies, respectively, for PTA estimation. Additionally, on the AAI task, we obtain 1.5%, 3% and 3.1% relative gain in CC on the same setups compared to the state-of-the-art baseline. We further present the computational benefits of having transformer architecture as representation blocks.
Attention and Encoder-Decoder based models for transforming articulatory movements at different speaking rates
Jun 04, 2020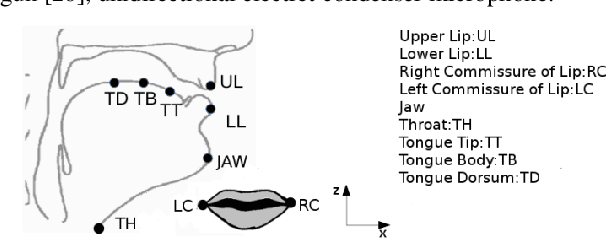
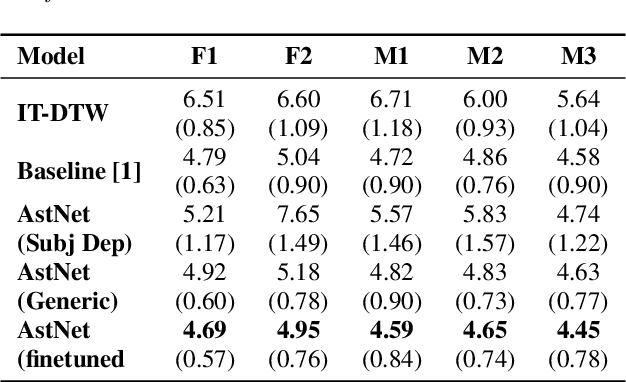
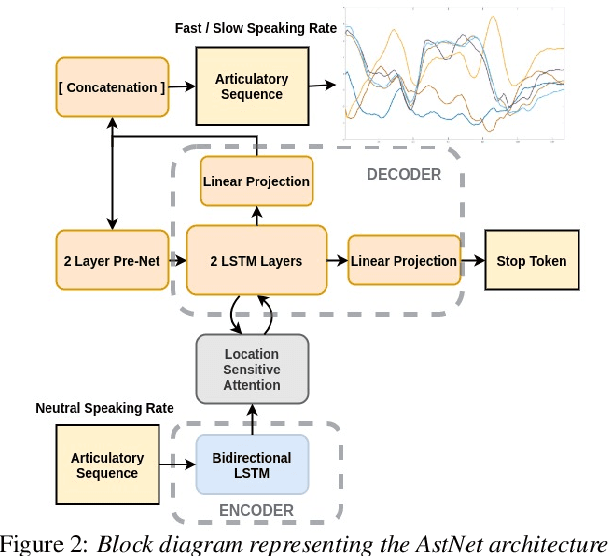
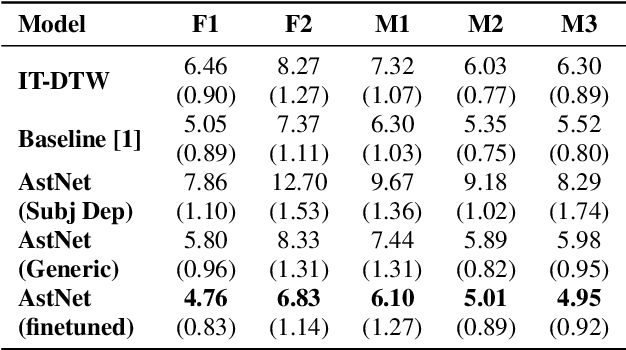
While speaking at different rates, articulators (like tongue, lips) tend to move differently and the enunciations are also of different durations. In the past, affine transformation and DNN have been used to transform articulatory movements from neutral to fast(N2F) and neutral to slow(N2S) speaking rates [1]. In this work, we improve over the existing transformation techniques by modeling rate specific durations and their transformation using AstNet, an encoder-decoder framework with attention. In the current work, we propose an encoder-decoder architecture using LSTMs which generates smoother predicted articulatory trajectories. For modeling duration variations across speaking rates, we deploy attention network, which eliminates the needto align trajectories in different rates using DTW. We performa phoneme specific duration analysis to examine how well duration is transformed using the proposed AstNet. As the range of articulatory motions is correlated with speaking rate, we also analyze amplitude of the transformed articulatory movements at different rates compared to their original counterparts, to examine how well the proposed AstNet predicts the extent of articulatory movements in N2F and N2S. We observe that AstNet could model both duration and extent of articulatory movements better than the existing transformation techniques resulting in more accurate transformed articulatory trajectories.
A comparative study of estimating articulatory movements from phoneme sequences and acoustic features
Oct 31, 2019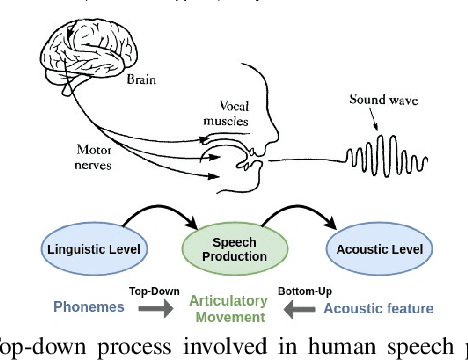
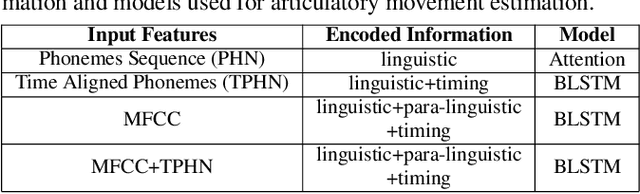
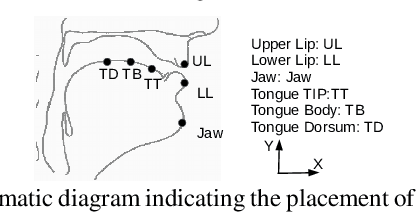
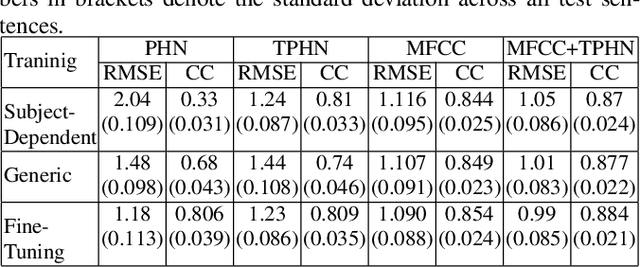
Unlike phoneme sequences, movements of speech articulators (lips, tongue, jaw, velum) and the resultant acoustic signal are known to encode not only the linguistic message but also carry para-linguistic information. While several works exist for estimating articulatory movement from acoustic signals, little is known to what extent articulatory movements can be predicted only from linguistic information, i.e., phoneme sequence. In this work, we estimate articulatory movements from three different input representations: R1) acoustic signal, R2) phoneme sequence, R3) phoneme sequence with timing information. While an attention network is used for estimating articulatory movement in the case of R2, BLSTM network is used for R1 and R3. Experiments with ten subjects' acoustic-articulatory data reveal that the estimation techniques achieve an average correlation coefficient of 0.85, 0.81, and 0.81 in the case of R1, R2, and R3 respectively. This indicates that attention network, although uses only phoneme sequence (R2) without any timing information, results in an estimation performance similar to that using rich acoustic signal (R1), suggesting that articulatory motion is primarily driven by the linguistic message. The correlation coefficient is further improved to 0.88 when R1 and R3 are used together for estimating articulatory movements.