 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn error correction scheme for improved air-tissue boundary in real-time MRI video for speech production
Mar 09, 2022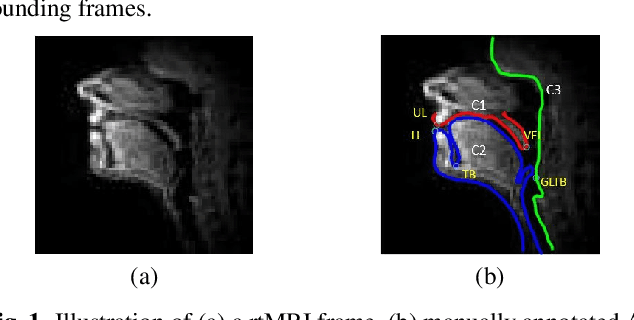

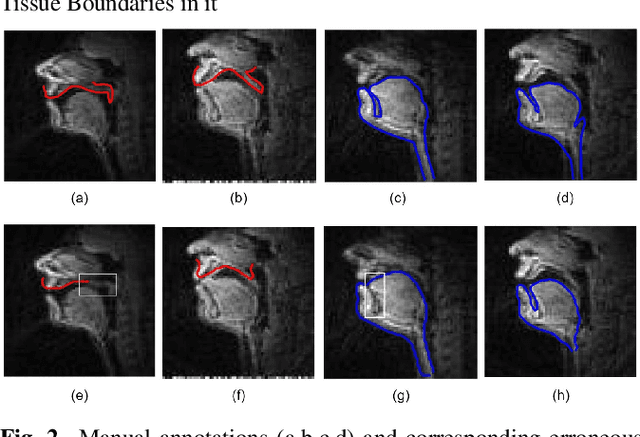
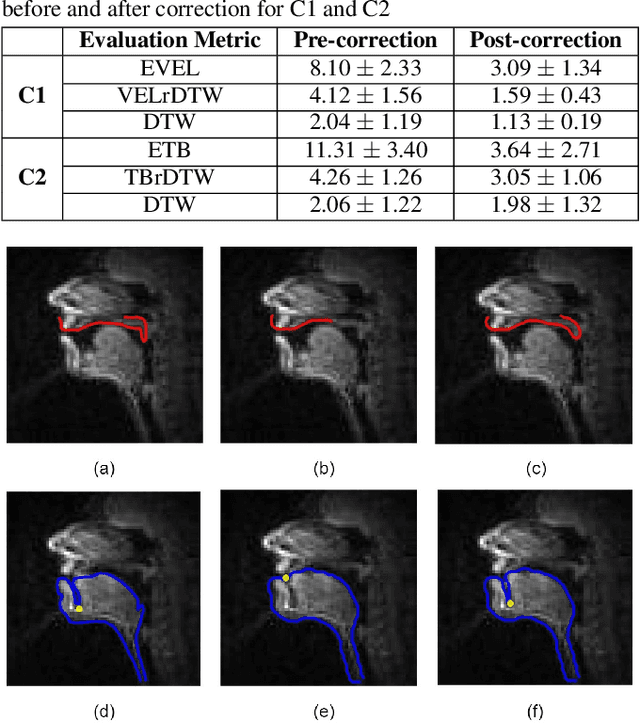
The best performance in Air-tissue boundary (ATB) segmentation of real-time Magnetic Resonance Imaging (rtMRI) videos in speech production is known to be achieved by a 3-dimensional convolutional neural network (3D-CNN) model. However, the evaluation of this model, as well as other ATB segmentation techniques reported in the literature, is done using Dynamic Time Warping (DTW) distance between the entire original and predicted contours. Such an evaluation measure may not capture local errors in the predicted contour. Careful analysis of predicted contours reveals errors in regions like the velum part of contour1 (ATB comprising of upper lip, hard palate, and velum) and tongue base section of contour2 (ATB covering jawline, lower lip, tongue base, and epiglottis), which are not captured in a global evaluation metric like DTW distance. In this work, we automatically detect such errors and propose a correction scheme for the same. We also propose two new evaluation metrics for ATB segmentation separately in contour1 and contour2 to explicitly capture two types of errors in these contours. The proposed detection and correction strategies result in an improvement of these two evaluation metrics by 61.8% and 61.4% for contour1 and by 67.8% and 28.4% for contour2. Traditional DTW distance, on the other hand, improves by 44.6% for contour1 and 4.0% for contour2.
Estimating articulatory movements in speech production with transformer networks
Apr 11, 2021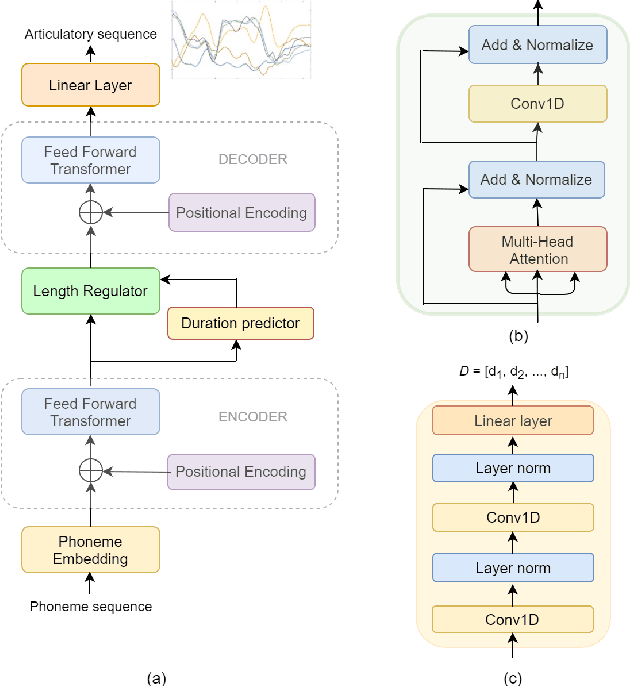
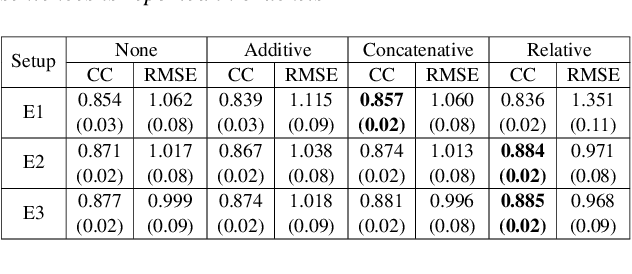
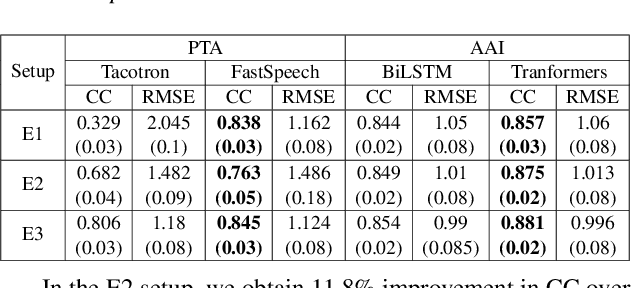
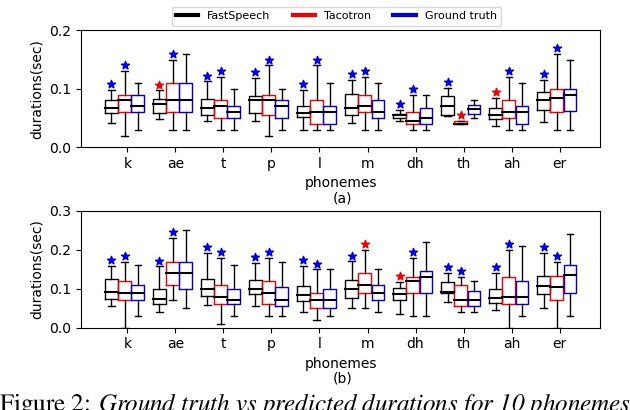
We estimate articulatory movements in speech production from different modalities - acoustics and phonemes. Acoustic-to articulatory inversion (AAI) is a sequence-to-sequence task. On the other hand, phoneme to articulatory (PTA) motion estimation faces a key challenge in reliably aligning the text and the articulatory movements. To address this challenge, we explore the use of a transformer architecture - FastSpeech, with explicit duration modelling to learn hard alignments between the phonemes and articulatory movements. We also train a transformer model on AAI. We use correlation coefficient (CC) and root mean squared error (rMSE) to assess the estimation performance in comparison to existing methods on both tasks. We observe 154%, 11.8% & 4.8% relative improvement in CC with subject-dependent, pooled and fine-tuning strategies, respectively, for PTA estimation. Additionally, on the AAI task, we obtain 1.5%, 3% and 3.1% relative gain in CC on the same setups compared to the state-of-the-art baseline. We further present the computational benefits of having transformer architecture as representation blocks.