 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAANI: Capturing the language landscape for an inclusive digital India
Mar 31, 2026Project VAANI is an initiative to create an India-representative multi-modal dataset that comprehensively maps India's linguistic diversity, starting with 165 districts across the country in its first two phases. Speech data is collected through a carefully structured process that uses image-based prompts to encourage spontaneous responses. Images are captured through a separate process that encompasses a broad range of topics, gathered from both within and across districts. The collected data undergoes a rigorous multi-stage quality evaluation, including both automated and manual checks to ensure highest possible standards in audio quality and transcription accuracy. Following this thorough validation, we have open-sourced around 289K images, approximately 31,270 hours of audio recordings, and around 2,067 hours of transcribed speech, encompassing 112 languages from 165 districts from 31 States and Union territories. Notably, significant of these languages are being represented for the first time in a dataset of this scale, making the VAANI project a groundbreaking effort in preserving and promoting linguistic inclusivity. This data can be instrumental in building inclusive speech models for India, and in advancing research and development across speech, image, and multimodal applications.
Streaming Endpointer for Spoken Dialogue using Neural Audio Codecs and Label-Delayed Training
Jun 08, 2025Accurate, low-latency endpointing is crucial for effective spoken dialogue systems. While traditional endpointers often rely on spectrum-based audio features, this work proposes real-time speech endpointing for multi-turn dialogues using streaming, low-bitrate Neural Audio Codec (NAC) features, building upon recent advancements in neural audio codecs. To further reduce cutoff errors, we introduce a novel label delay training scheme. At a fixed median latency of 160 ms, our combined NAC and label delay approach achieves significant relative cutoff error reductions: 42.7% for a single-stream endpointer and 37.5% for a two-stream configuration, compared to baseline methods. Finally, we demonstrate efficient integration with a codec-based pretrained speech large language model, improving its median response time by 1200 ms and reducing its cutoff error by 35%.
Discovering phoneme-specific critical articulators through a data-driven approach
Apr 15, 2025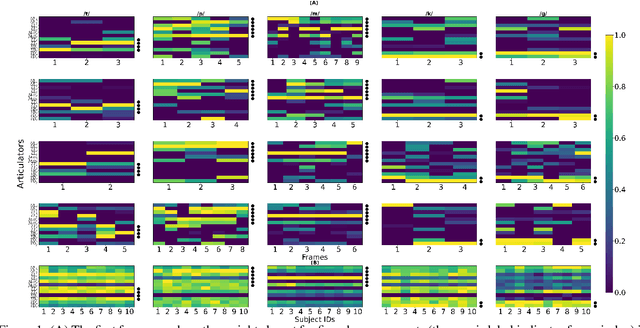
We propose an approach for learning critical articulators for phonemes through a machine learning approach. We formulate the learning with three models trained end to end. First, we use Acoustic to Articulatory Inversion (AAI) to predict time-varying speech articulators EMA. We also predict the phoneme-specific weights across articulators for each frame. To avoid overfitting, we also add a dropout layer before the weights prediction layer. Next, we normalize the predicted weights across articulators using min-max normalization for each frame. The normalized weights are multiplied by the ground truth $EMA$ and then we try to predict the phones at each frame. We train this whole setup end to end and use two losses. One loss is for the phone prediction which is the cross entropy loss and the other is for the AAI prediction which is the mean squared error loss. To maintain gradient flow between the phone prediction block and the $EMA$ prediction block, we use straight-through estimation. The goal here is to predict the weights of the articulator at each frame while training the model end to end.
Speaking rate attention-based duration prediction for speed control TTS
Oct 13, 2023With the advent of high-quality speech synthesis, there is a lot of interest in controlling various prosodic attributes of speech. Speaking rate is an essential attribute towards modelling the expressivity of speech. In this work, we propose a novel approach to control the speaking rate for non-autoregressive TTS. We achieve this by conditioning the speaking rate inside the duration predictor, allowing implicit speaking rate control. We show the benefits of this approach by synthesising audio at various speaking rate factors and measuring the quality of speaking rate-controlled synthesised speech. Further, we study the effect of the speaking rate distribution of the training data towards effective rate control. Finally, we fine-tune a baseline pretrained TTS model to obtain speaking rate control TTS. We provide various analyses to showcase the benefits of using this proposed approach, along with objective as well as subjective metrics. We find that the proposed methods have higher subjective scores and lower speaker rate errors across many speaking rate factors over the baseline.
Model Adaptation for ASR in low-resource Indian Languages
Jul 16, 2023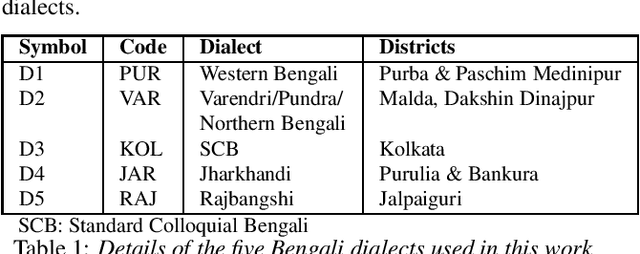

Automatic speech recognition (ASR) performance has improved drastically in recent years, mainly enabled by self-supervised learning (SSL) based acoustic models such as wav2vec2 and large-scale multi-lingual training like Whisper. A huge challenge still exists for low-resource languages where the availability of both audio and text is limited. This is further complicated by the presence of multiple dialects like in Indian languages. However, many Indian languages can be grouped into the same families and share the same script and grammatical structure. This is where a lot of adaptation and fine-tuning techniques can be applied to overcome the low-resource nature of the data by utilising well-resourced similar languages. In such scenarios, it is important to understand the extent to which each modality, like acoustics and text, is important in building a reliable ASR. It could be the case that an abundance of acoustic data in a language reduces the need for large text-only corpora. Or, due to the availability of various pretrained acoustic models, the vice-versa could also be true. In this proposed special session, we encourage the community to explore these ideas with the data in two low-resource Indian languages of Bengali and Bhojpuri. These approaches are not limited to Indian languages, the solutions are potentially applicable to various languages spoken around the world.
Real-Time MRI Video synthesis from time aligned phonemes with sequence-to-sequence networks
Oct 30, 2022Real-Time Magnetic resonance imaging (rtMRI) of the midsagittal plane of the mouth is of interest for speech production research. In this work, we focus on estimating utterance level rtMRI video from the spoken phoneme sequence. We obtain time-aligned phonemes from forced alignment, to obtain frame-level phoneme sequences which are aligned with rtMRI frames. We propose a sequence-to-sequence learning model with a transformer phoneme encoder and convolutional frame decoder. We then modify the learning by using intermediary features obtained from sampling from a pretrained phoneme-conditioned variational autoencoder (CVAE). We train on 8 subjects in a subject-specific manner and demonstrate the performance with a subjective test. We also use an auxiliary task of air tissue boundary (ATB) segmentation to obtain the objective scores on the proposed models. We show that the proposed method is able to generate realistic rtMRI video for unseen utterances, and adding CVAE is beneficial for learning the sequence-to-sequence mapping for subjects where the mapping is hard to learn.
Improved acoustic-to-articulatory inversion using representations from pretrained self-supervised learning models
Oct 30, 2022



In this work, we investigate the effectiveness of pretrained Self-Supervised Learning (SSL) features for learning the mapping for acoustic to articulatory inversion (AAI). Signal processing-based acoustic features such as MFCCs have been predominantly used for the AAI task with deep neural networks. With SSL features working well for various other speech tasks such as speech recognition, emotion classification, etc., we experiment with its efficacy for AAI. We train on SSL features with transformer neural networks-based AAI models of 3 different model complexities and compare its performance with MFCCs in subject-specific (SS), pooled and fine-tuned (FT) configurations with data from 10 subjects, and evaluate with correlation coefficient (CC) score on the unseen sentence test set. We find that acoustic feature reconstruction objective-based SSL features such as TERA and DeCoAR work well for AAI, with SS CCs of these SSL features reaching close to the best FT CCs of MFCC. We also find the results consistent across different model sizes.
Estimating articulatory movements in speech production with transformer networks
Apr 11, 2021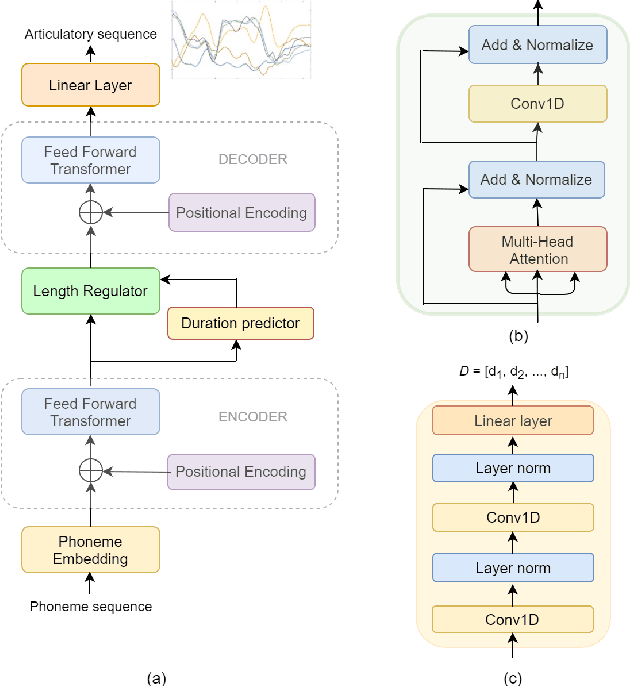
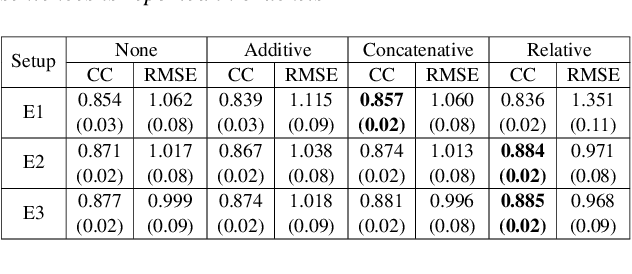
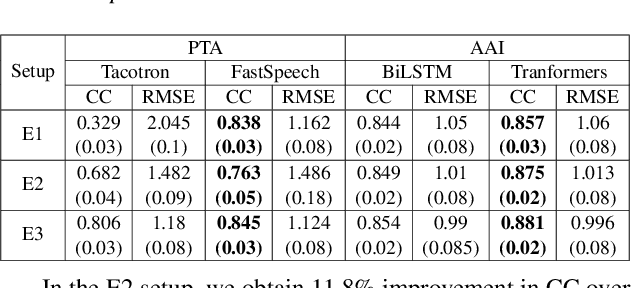
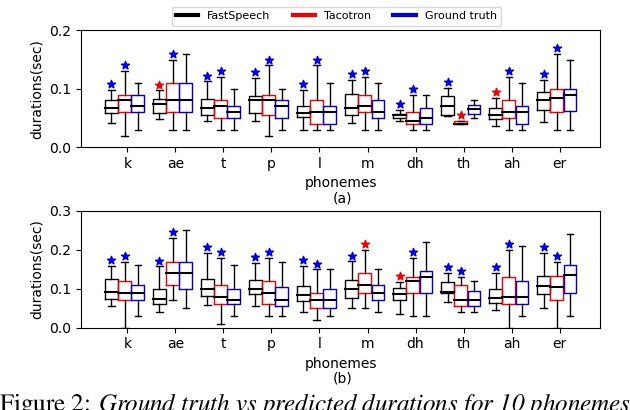
We estimate articulatory movements in speech production from different modalities - acoustics and phonemes. Acoustic-to articulatory inversion (AAI) is a sequence-to-sequence task. On the other hand, phoneme to articulatory (PTA) motion estimation faces a key challenge in reliably aligning the text and the articulatory movements. To address this challenge, we explore the use of a transformer architecture - FastSpeech, with explicit duration modelling to learn hard alignments between the phonemes and articulatory movements. We also train a transformer model on AAI. We use correlation coefficient (CC) and root mean squared error (rMSE) to assess the estimation performance in comparison to existing methods on both tasks. We observe 154%, 11.8% & 4.8% relative improvement in CC with subject-dependent, pooled and fine-tuning strategies, respectively, for PTA estimation. Additionally, on the AAI task, we obtain 1.5%, 3% and 3.1% relative gain in CC on the same setups compared to the state-of-the-art baseline. We further present the computational benefits of having transformer architecture as representation blocks.