 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating articulatory movements in speech production with transformer networks
Paper and Code
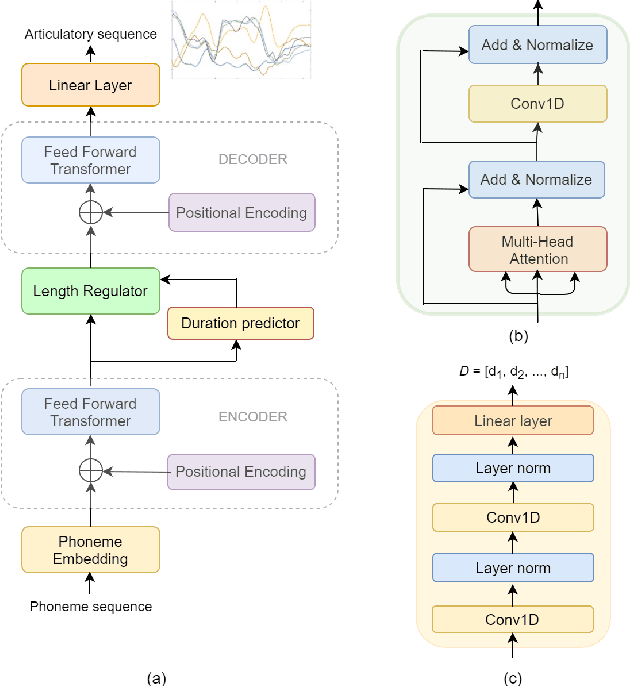
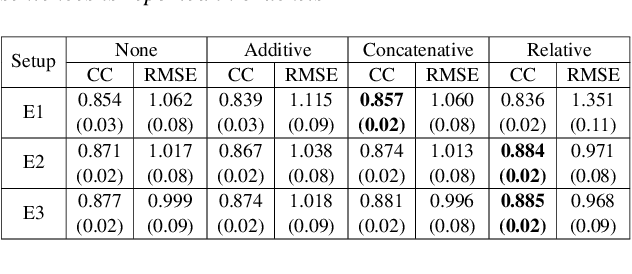
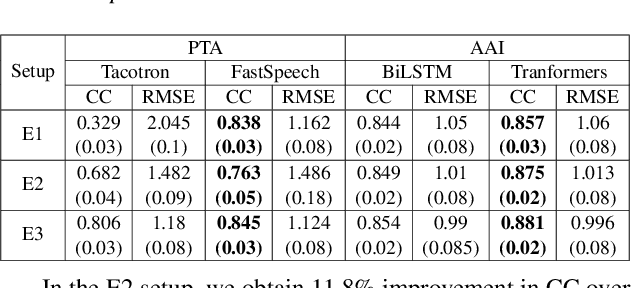
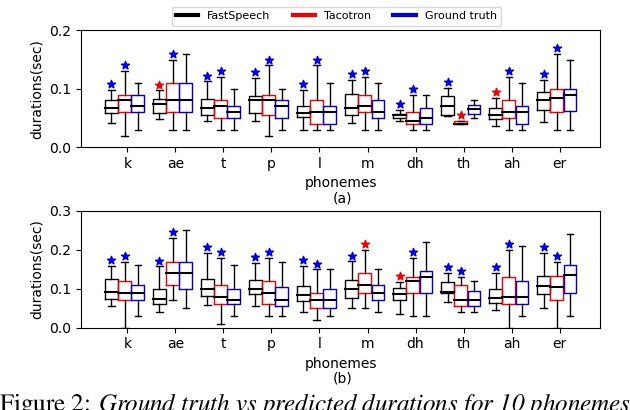
We estimate articulatory movements in speech production from different modalities - acoustics and phonemes. Acoustic-to articulatory inversion (AAI) is a sequence-to-sequence task. On the other hand, phoneme to articulatory (PTA) motion estimation faces a key challenge in reliably aligning the text and the articulatory movements. To address this challenge, we explore the use of a transformer architecture - FastSpeech, with explicit duration modelling to learn hard alignments between the phonemes and articulatory movements. We also train a transformer model on AAI. We use correlation coefficient (CC) and root mean squared error (rMSE) to assess the estimation performance in comparison to existing methods on both tasks. We observe 154%, 11.8% & 4.8% relative improvement in CC with subject-dependent, pooled and fine-tuning strategies, respectively, for PTA estimation. Additionally, on the AAI task, we obtain 1.5%, 3% and 3.1% relative gain in CC on the same setups compared to the state-of-the-art baseline. We further present the computational benefits of having transformer architecture as representation blocks.