 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparative study of estimating articulatory movements from phoneme sequences and acoustic features
Paper and Code
Oct 31, 2019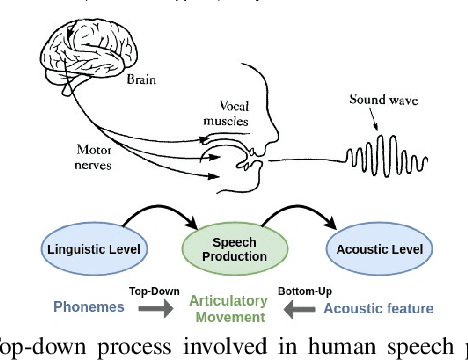
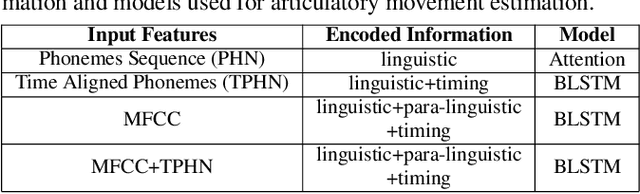
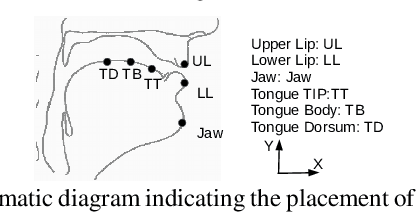
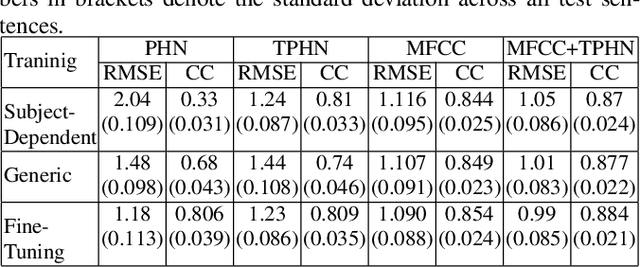
Unlike phoneme sequences, movements of speech articulators (lips, tongue, jaw, velum) and the resultant acoustic signal are known to encode not only the linguistic message but also carry para-linguistic information. While several works exist for estimating articulatory movement from acoustic signals, little is known to what extent articulatory movements can be predicted only from linguistic information, i.e., phoneme sequence. In this work, we estimate articulatory movements from three different input representations: R1) acoustic signal, R2) phoneme sequence, R3) phoneme sequence with timing information. While an attention network is used for estimating articulatory movement in the case of R2, BLSTM network is used for R1 and R3. Experiments with ten subjects' acoustic-articulatory data reveal that the estimation techniques achieve an average correlation coefficient of 0.85, 0.81, and 0.81 in the case of R1, R2, and R3 respectively. This indicates that attention network, although uses only phoneme sequence (R2) without any timing information, results in an estimation performance similar to that using rich acoustic signal (R1), suggesting that articulatory motion is primarily driven by the linguistic message. The correlation coefficient is further improved to 0.88 when R1 and R3 are used together for estimating articulatory movements.