 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinically Inspired Symptom-Guided Depression Detection from Emotion-Aware Speech Representations
Feb 17, 2026Depression manifests through a diverse set of symptoms such as sleep disturbance, loss of interest, and concentration difficulties. However, most existing works treat depression prediction either as a binary label or an overall severity score without explicitly modeling symptom-specific information. This limits their ability to provide symptom-level analysis relevant to clinical screening. To address this, we propose a symptom-specific and clinically inspired framework for depression severity estimation from speech. Our approach uses a symptom-guided cross-attention mechanism that aligns PHQ-8 questionnaire items with emotion-aware speech representations to identify which segments of a participant's speech are more important to each symptom. To account for differences in how symptoms are expressed over time, we introduce a learnable symptom-specific parameter that adaptively controls the sharpness of attention distributions. Our results on EDAIC, a standard clinical-style dataset, demonstrate improved performance outperforming prior works. Further, analyzing the attention distributions showed that higher attention is assigned to utterances containing cues related to multiple depressive symptoms, highlighting the interpretability of our approach. These findings outline the importance of symptom-guided and emotion-aware modeling for speech-based depression screening.
Decoding Emotion: Speech Perception Patterns in Individuals with Self-reported Depression
Dec 28, 2024
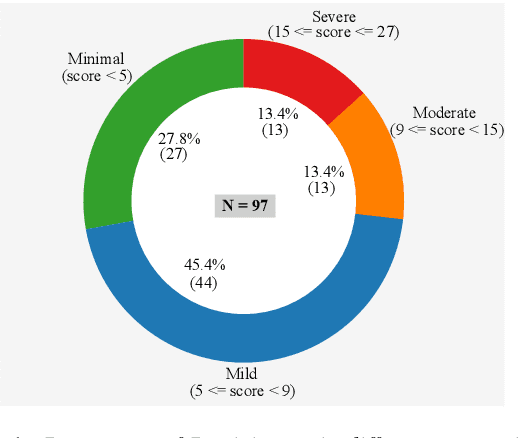
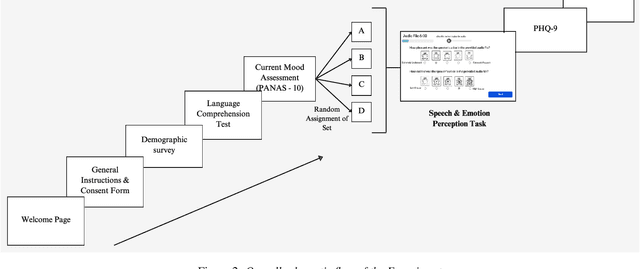

The current study examines the relationship between self-reported depression and the perception of affective speech within the Indian population. PANAS and PHQ-9 were used to assess current mood and depression, respectively. Participants' emotional reactivity was recorded on a valence and arousal scale against the affective speech audio presented in a sequence. No significant differences between the depression and no-depression groups were observed for any of the emotional stimuli, except the audio file depicting neutral emotion. Significantly higher PANAS scores by the depression than the no-depression group indicate the impact of pre-disposed mood on the current mood status. Contrary to previous findings, this study did not observe reduced positive emotional reactivity by the depression group. However, the results demonstrated consistency in emotional reactivity for speech stimuli depicting sadness and anger across all measures of emotion perception.
A Preliminary Analysis of Automatic Word and Syllable Prominence Detection in Non-Native Speech With Text-to-Speech Prosody Embeddings
Dec 11, 2024Automatic detection of prominence at the word and syllable-levels is critical for building computer-assisted language learning systems. It has been shown that prosody embeddings learned by the current state-of-the-art (SOTA) text-to-speech (TTS) systems could generate word- and syllable-level prominence in the synthesized speech as natural as in native speech. To understand the effectiveness of prosody embeddings from TTS for prominence detection under nonnative context, a comparative analysis is conducted on the embeddings extracted from native and non-native speech considering the prominence-related embeddings: duration, energy, and pitch from a SOTA TTS named FastSpeech2. These embeddings are extracted under two conditions considering: 1) only text, 2) both speech and text. For the first condition, the embeddings are extracted directly from the TTS inference mode, whereas for the second condition, we propose to extract from the TTS under training mode. Experiments are conducted on native speech corpus: Tatoeba, and non-native speech corpus: ISLE. For experimentation, word-level prominence locations are manually annotated for both corpora. The highest relative improvement on word \& syllable-level prominence detection accuracies with the TTS embeddings are found to be 13.7% & 5.9% and 16.2% & 6.9% compared to those with the heuristic-based features and self-supervised Wav2Vec-2.0 representations, respectively.
Evaluating the Impact of Discriminative and Generative E2E Speech Enhancement Models on Syllable Stress Preservation
Dec 11, 2024Automatic syllable stress detection is a crucial component in Computer-Assisted Language Learning (CALL) systems for language learners. Current stress detection models are typically trained on clean speech, which may not be robust in real-world scenarios where background noise is prevalent. To address this, speech enhancement (SE) models, designed to enhance speech by removing noise, might be employed, but their impact on preserving syllable stress patterns is not well studied. This study examines how different SE models, representing discriminative and generative modeling approaches, affect syllable stress detection under noisy conditions. We assess these models by applying them to speech data with varying signal-to-noise ratios (SNRs) from 0 to 20 dB, and evaluating their effectiveness in maintaining stress patterns. Additionally, we explore different feature sets to determine which ones are most effective for capturing stress patterns amidst noise. To further understand the impact of SE models, a human-based perceptual study is conducted to compare the perceived stress patterns in SE-enhanced speech with those in clean speech, providing insights into how well these models preserve syllable stress as perceived by listeners. Experiments are performed on English speech data from non-native speakers of German and Italian. And the results reveal that the stress detection performance is robust with the generative SE models when heuristic features are used. Also, the observations from the perceptual study are consistent with the stress detection outcomes under all SE models.
Unsupervised speech intelligibility assessment with utterance level alignment distance between teacher and learner Wav2Vec-2.0 representations
Jun 15, 2023



Speech intelligibility is crucial in language learning for effective communication. Thus, to develop computer-assisted language learning systems, automatic speech intelligibility detection (SID) is necessary. Most of the works have assessed the intelligibility in a supervised manner considering manual annotations, which requires cost and time; hence scalability is limited. To overcome these, this work proposes an unsupervised approach for SID. The proposed approach considers alignment distance computed with dynamic-time warping (DTW) between teacher and learner representation sequence as a measure to separate intelligible versus non-intelligible speech. We obtain the feature sequence using current state-of-the-art self-supervised representations from Wav2Vec-2.0. We found the detection accuracies as 90.37\%, 92.57\% and 96.58\%, respectively, with three alignment distance measures -- mean absolute error, mean squared error and cosine distance (equal to one minus cosine similarity).
An Investigation of Indian Native Language Phonemic Influences on L2 English Pronunciations
Dec 19, 2022



Speech systems are sensitive to accent variations. This is especially challenging in the Indian context, with an abundance of languages but a dearth of linguistic studies characterising pronunciation variations. The growing number of L2 English speakers in India reinforces the need to study accents and L1-L2 interactions. We investigate the accents of Indian English (IE) speakers and report in detail our observations, both specific and common to all regions. In particular, we observe the phonemic variations and phonotactics occurring in the speakers' native languages and apply this to their English pronunciations. We demonstrate the influence of 18 Indian languages on IE by comparing the native language pronunciations with IE pronunciations obtained jointly from existing literature studies and phonetically annotated speech of 80 speakers. Consequently, we are able to validate the intuitions of Indian language influences on IE pronunciations by justifying pronunciation rules from the perspective of Indian language phonology. We obtain a comprehensive description in terms of universal and region-specific characteristics of IE, which facilitates accent conversion and adaptation of existing ASR and TTS systems to different Indian accents.
Study of Indian English Pronunciation Variabilities relative to Received Pronunciation
Apr 13, 2022


In contrast to British or American English, labeled pronunciation data on the phonetic level is scarce for Indian English (IE). This has made it challenging to study pronunciations of Indian English. Moreover, IE has many varieties, resulting from various native language influences on L2 English. Indian English has been studied in the past, by a few linguistic works. They report phonetic rules for such characterisation, however, the extent to which they can be applied to a diverse large-scale Indian pronunciation data remains under-examined. We consider a corpus, IndicTIMIT, which is rich in the diversity of IE varieties and is curated in a nativity balanced manner. It contains data from 80 speakers corresponding to various regions of India. We present an approach to validate the phonetic rules of IE along with reporting unexplored rules derived using a data-driven manner, on this corpus. We also provide quantitative information regarding which rules are more prominently observed than the others, attributing to their relevance in IE accordingly.
mulEEG: A Multi-View Representation Learning on EEG Signals
Apr 07, 2022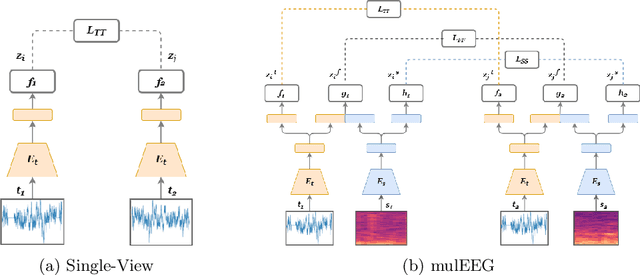
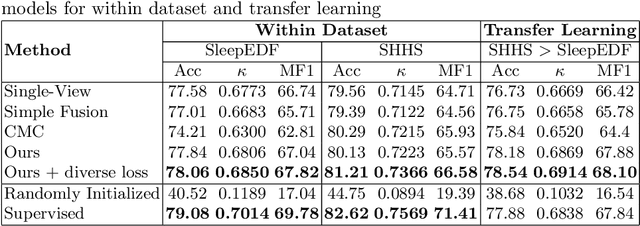
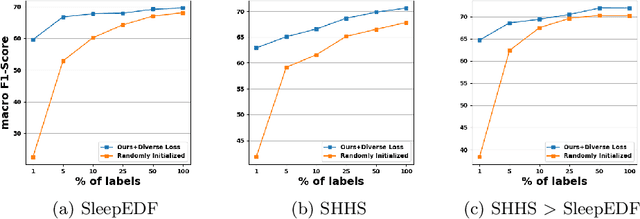
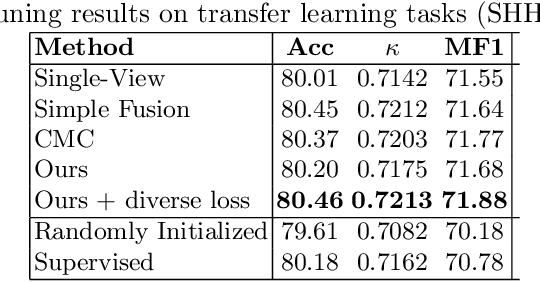
Modeling effective representations using multiple views that positively influence each other is challenging, and the existing methods perform poorly on Electroencephalogram (EEG) signals for sleep-staging tasks. In this paper, we propose a novel multi-view self-supervised method (mulEEG) for unsupervised EEG representation learning. Our method attempts to effectively utilize the complementary information available in multiple views to learn better representations. We introduce diverse loss that further encourages complementary information across multiple views. Our method with no access to labels beats the supervised training while outperforming multi-view baseline methods on transfer learning experiments carried out on sleep-staging tasks. We posit that our method was able to learn better representations by using complementary multi-views.
A study on native American English speech recognition by Indian listeners with varying word familiarity level
Dec 08, 2021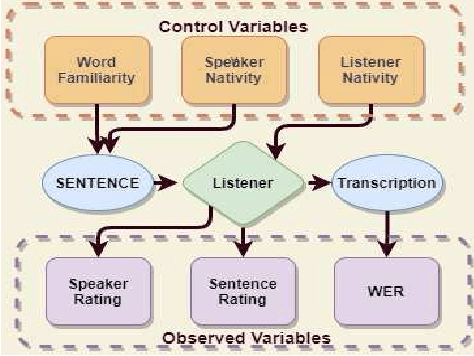
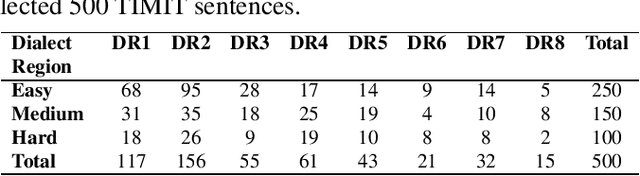
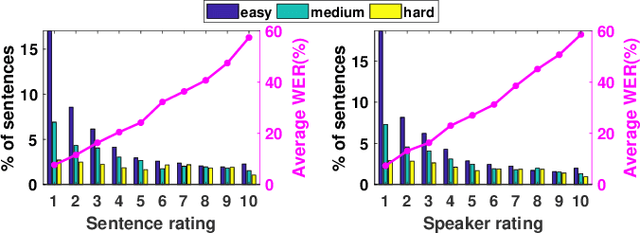
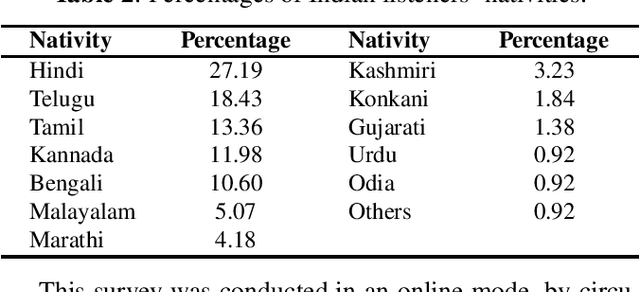
In this study, listeners of varied Indian nativities are asked to listen and recognize TIMIT utterances spoken by American speakers. We have three kinds of responses from each listener while they recognize an utterance: 1. Sentence difficulty ratings, 2. Speaker difficulty ratings, and 3. Transcription of the utterance. From these transcriptions, word error rate (WER) is calculated and used as a metric to evaluate the similarity between the recognized and the original sentences.The sentences selected in this study are categorized into three groups: Easy, Medium and Hard, based on the frequency ofoccurrence of the words in them. We observe that the sentence, speaker difficulty ratings and the WERs increase from easy to hard categories of sentences. We also compare the human speech recognition performance with that using three automatic speech recognition (ASR) under following three combinations of acoustic model (AM) and language model(LM): ASR1) AM trained with recordings from speakers of Indian origin and LM built on TIMIT text, ASR2) AM using recordings from native American speakers and LM built ontext from LIBRI speech corpus, and ASR3) AM using recordings from native American speakers and LM build on LIBRI speech and TIMIT text. We observe that HSR performance is similar to that of ASR1 whereas ASR3 achieves the best performance. Speaker nativity wise analysis shows that utterances from speakers of some nativity are more difficult to recognize by Indian listeners compared to few other nativities
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021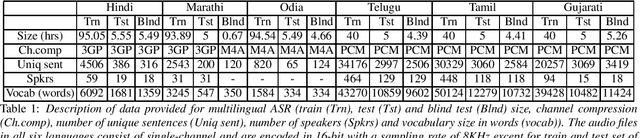
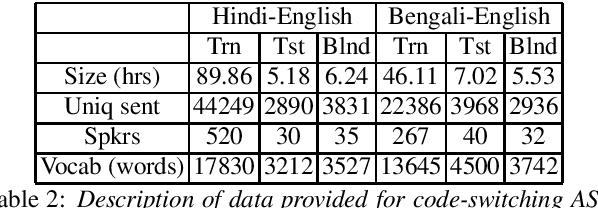
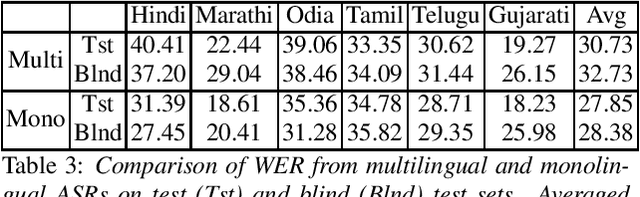
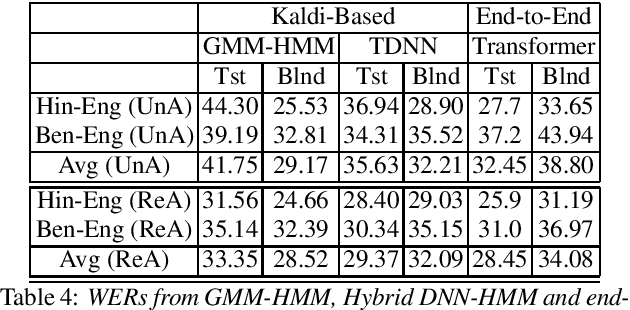
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.