 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Preliminary Analysis of Automatic Word and Syllable Prominence Detection in Non-Native Speech With Text-to-Speech Prosody Embeddings
Dec 11, 2024Automatic detection of prominence at the word and syllable-levels is critical for building computer-assisted language learning systems. It has been shown that prosody embeddings learned by the current state-of-the-art (SOTA) text-to-speech (TTS) systems could generate word- and syllable-level prominence in the synthesized speech as natural as in native speech. To understand the effectiveness of prosody embeddings from TTS for prominence detection under nonnative context, a comparative analysis is conducted on the embeddings extracted from native and non-native speech considering the prominence-related embeddings: duration, energy, and pitch from a SOTA TTS named FastSpeech2. These embeddings are extracted under two conditions considering: 1) only text, 2) both speech and text. For the first condition, the embeddings are extracted directly from the TTS inference mode, whereas for the second condition, we propose to extract from the TTS under training mode. Experiments are conducted on native speech corpus: Tatoeba, and non-native speech corpus: ISLE. For experimentation, word-level prominence locations are manually annotated for both corpora. The highest relative improvement on word \& syllable-level prominence detection accuracies with the TTS embeddings are found to be 13.7% & 5.9% and 16.2% & 6.9% compared to those with the heuristic-based features and self-supervised Wav2Vec-2.0 representations, respectively.
Attempt Towards Stress Transfer in Speech-to-Speech Machine Translation
Mar 07, 2024
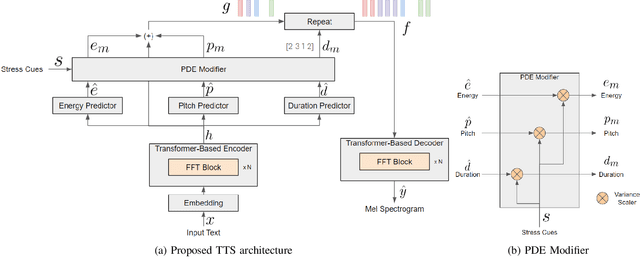
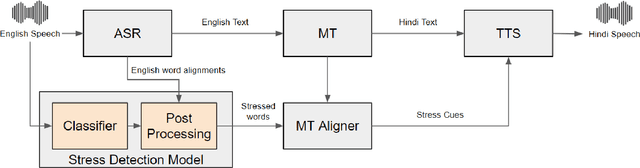

The language diversity in India's education sector poses a significant challenge, hindering inclusivity. Despite the democratization of knowledge through online educational content, the dominance of English, as the internet's lingua franca, limits accessibility, emphasizing the crucial need for translation into Indian languages. Despite existing Speech-to-Speech Machine Translation (SSMT) technologies, the lack of intonation in these systems gives monotonous translations, leading to a loss of audience interest and disengagement from the content. To address this, our paper introduces a dataset with stress annotations in Indian English and also a Text-to-Speech (TTS) architecture capable of incorporating stress into synthesized speech. This dataset is used for training a stress detection model, which is then used in the SSMT system for detecting stress in the source speech and transferring it into the target language speech. The TTS architecture is based on FastPitch and can modify the variances based on stressed words given. We present an Indian English-to-Hindi SSMT system that can transfer stress and aim to enhance the overall quality and engagement of educational content.