 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTypical vs. Atypical Disfluency Classification: Introducing the IIITH-TISA Corpus and Temporal Context-Based Feature Representations
Nov 26, 2024



Speech disfluencies in spontaneous communication can be categorized as either typical or atypical. Typical disfluencies, such as hesitations and repetitions, are natural occurrences in everyday speech, while atypical disfluencies are indicative of pathological disorders like stuttering. Distinguishing between these categories is crucial for improving voice assistants (VAs) for Persons Who Stutter (PWS), who often face premature cutoffs due to misidentification of speech termination. Accurate classification also aids in detecting stuttering early in children, preventing misdiagnosis as language development disfluency. This research introduces the IIITH-TISA dataset, the first Indian English stammer corpus, capturing atypical disfluencies. Additionally, we extend the IIITH-IED dataset with detailed annotations for typical disfluencies. We propose Perceptually Enhanced Zero-Time Windowed Cepstral Coefficients (PE-ZTWCC) combined with Shifted Delta Cepstra (SDC) as input features to a shallow Time Delay Neural Network (TDNN) classifier, capturing both local and wider temporal contexts. Our method achieves an average F1 score of 85.01% for disfluency classification, outperforming traditional features.
Attempt Towards Stress Transfer in Speech-to-Speech Machine Translation
Mar 07, 2024
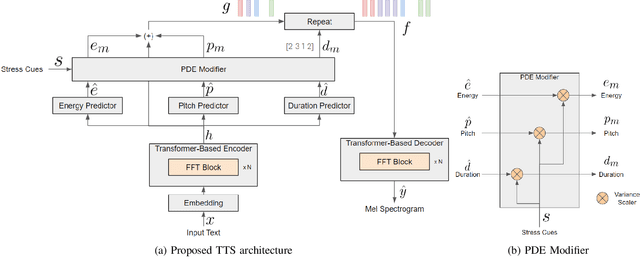
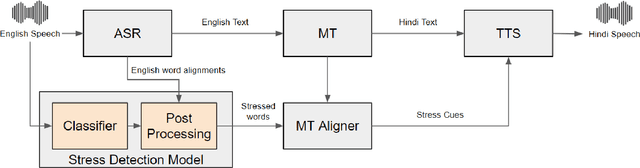

The language diversity in India's education sector poses a significant challenge, hindering inclusivity. Despite the democratization of knowledge through online educational content, the dominance of English, as the internet's lingua franca, limits accessibility, emphasizing the crucial need for translation into Indian languages. Despite existing Speech-to-Speech Machine Translation (SSMT) technologies, the lack of intonation in these systems gives monotonous translations, leading to a loss of audience interest and disengagement from the content. To address this, our paper introduces a dataset with stress annotations in Indian English and also a Text-to-Speech (TTS) architecture capable of incorporating stress into synthesized speech. This dataset is used for training a stress detection model, which is then used in the SSMT system for detecting stress in the source speech and transferring it into the target language speech. The TTS architecture is based on FastPitch and can modify the variances based on stressed words given. We present an Indian English-to-Hindi SSMT system that can transfer stress and aim to enhance the overall quality and engagement of educational content.
An Investigation of Indian Native Language Phonemic Influences on L2 English Pronunciations
Dec 19, 2022



Speech systems are sensitive to accent variations. This is especially challenging in the Indian context, with an abundance of languages but a dearth of linguistic studies characterising pronunciation variations. The growing number of L2 English speakers in India reinforces the need to study accents and L1-L2 interactions. We investigate the accents of Indian English (IE) speakers and report in detail our observations, both specific and common to all regions. In particular, we observe the phonemic variations and phonotactics occurring in the speakers' native languages and apply this to their English pronunciations. We demonstrate the influence of 18 Indian languages on IE by comparing the native language pronunciations with IE pronunciations obtained jointly from existing literature studies and phonetically annotated speech of 80 speakers. Consequently, we are able to validate the intuitions of Indian language influences on IE pronunciations by justifying pronunciation rules from the perspective of Indian language phonology. We obtain a comprehensive description in terms of universal and region-specific characteristics of IE, which facilitates accent conversion and adaptation of existing ASR and TTS systems to different Indian accents.
Study of Indian English Pronunciation Variabilities relative to Received Pronunciation
Apr 13, 2022


In contrast to British or American English, labeled pronunciation data on the phonetic level is scarce for Indian English (IE). This has made it challenging to study pronunciations of Indian English. Moreover, IE has many varieties, resulting from various native language influences on L2 English. Indian English has been studied in the past, by a few linguistic works. They report phonetic rules for such characterisation, however, the extent to which they can be applied to a diverse large-scale Indian pronunciation data remains under-examined. We consider a corpus, IndicTIMIT, which is rich in the diversity of IE varieties and is curated in a nativity balanced manner. It contains data from 80 speakers corresponding to various regions of India. We present an approach to validate the phonetic rules of IE along with reporting unexplored rules derived using a data-driven manner, on this corpus. We also provide quantitative information regarding which rules are more prominently observed than the others, attributing to their relevance in IE accordingly.