 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccented Speech Recognition With Accent-specific Codebooks
Oct 27, 2023



Speech accents pose a significant challenge to state-of-the-art automatic speech recognition (ASR) systems. Degradation in performance across underrepresented accents is a severe deterrent to the inclusive adoption of ASR. In this work, we propose a novel accent adaptation approach for end-to-end ASR systems using cross-attention with a trainable set of codebooks. These learnable codebooks capture accent-specific information and are integrated within the ASR encoder layers. The model is trained on accented English speech, while the test data also contained accents which were not seen during training. On the Mozilla Common Voice multi-accented dataset, we show that our proposed approach yields significant performance gains not only on the seen English accents (up to $37\%$ relative improvement in word error rate) but also on the unseen accents (up to $5\%$ relative improvement in WER). Further, we illustrate benefits for a zero-shot transfer setup on the L2Artic dataset. We also compare the performance with other approaches based on accent adversarial training.
Adaptive Discounting of Implicit Language Models in RNN-Transducers
Feb 21, 2022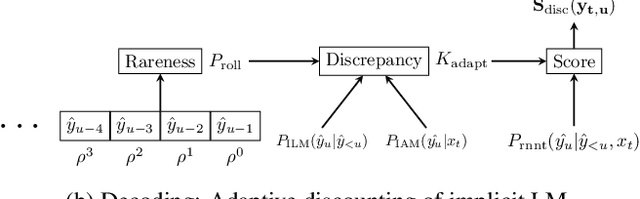
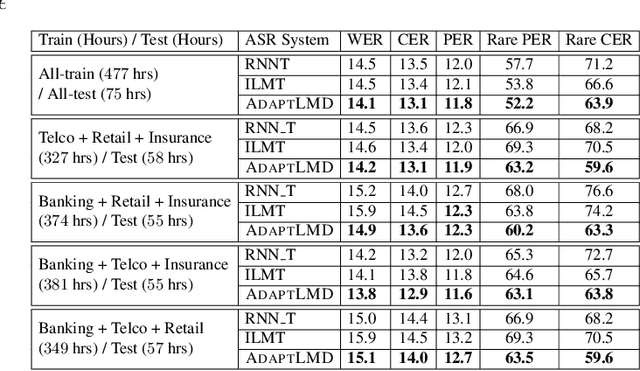
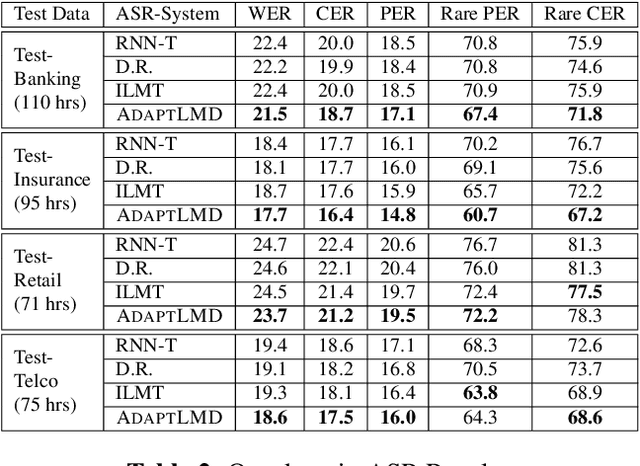
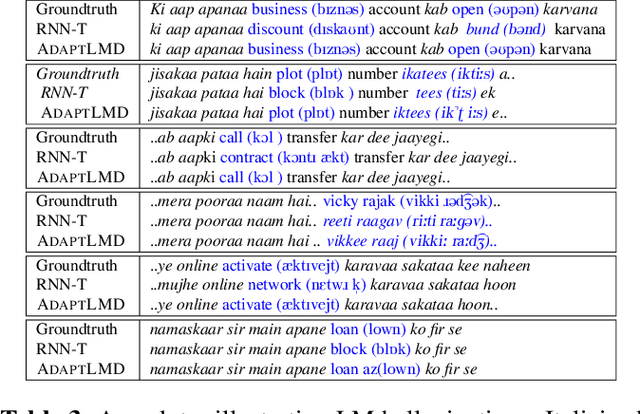
RNN-Transducer (RNN-T) models have become synonymous with streaming end-to-end ASR systems. While they perform competitively on a number of evaluation categories, rare words pose a serious challenge to RNN-T models. One main reason for the degradation in performance on rare words is that the language model (LM) internal to RNN-Ts can become overconfident and lead to hallucinated predictions that are acoustically inconsistent with the underlying speech. To address this issue, we propose a lightweight adaptive LM discounting technique AdaptLMD, that can be used with any RNN-T architecture without requiring any external resources or additional parameters. AdaptLMD uses a two-pronged approach: 1) Randomly mask the prediction network output to encourage the RNN-T to not be overly reliant on it's outputs. 2) Dynamically choose when to discount the implicit LM (ILM) based on rarity of recently predicted tokens and divergence between ILM and implicit acoustic model (IAM) scores. Comparing AdaptLMD to a competitive RNN-T baseline, we obtain up to 4% and 14% relative reductions in overall WER and rare word PER, respectively, on a conversational, code-mixed Hindi-English ASR task.
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021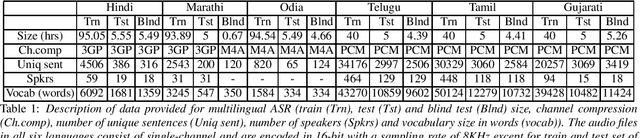
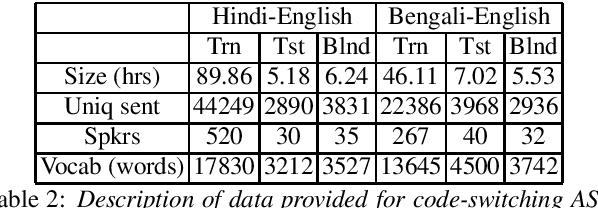
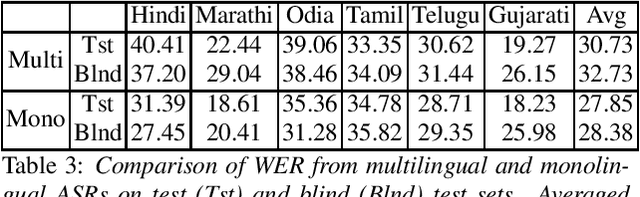
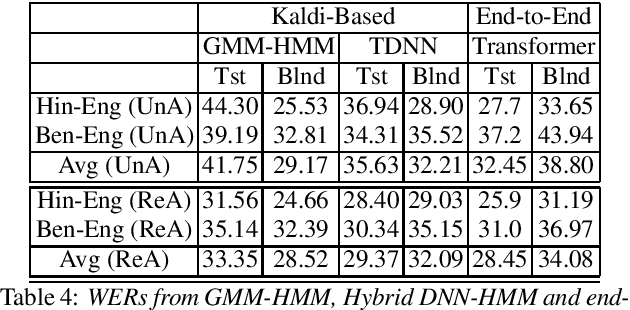
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.