 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALSA: Speedy ASR-LLM Synchronous Aggregation
Aug 29, 2024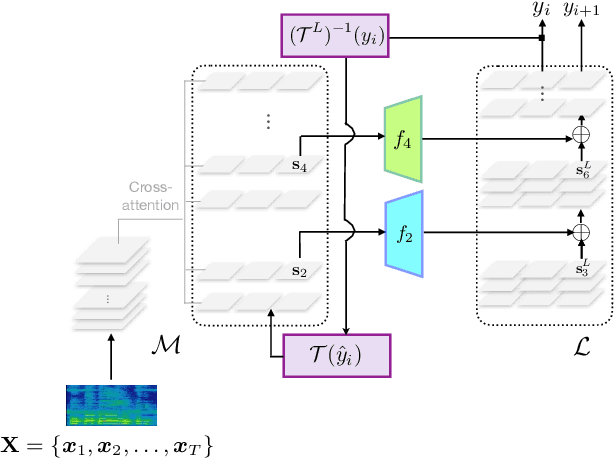

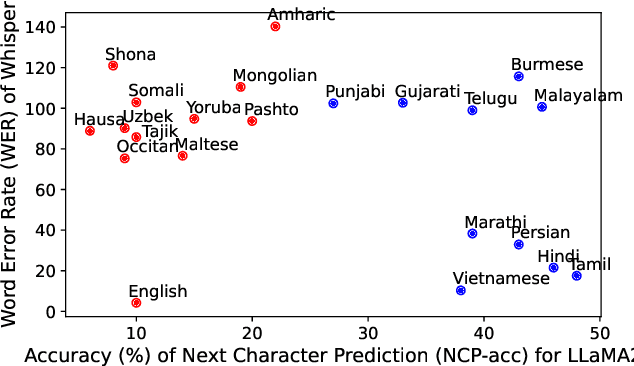

Harnessing pre-trained LLMs to improve ASR systems, particularly for low-resource languages, is now an emerging area of research. Existing methods range from using LLMs for ASR error correction to tightly coupled systems that replace the ASR decoder with the LLM. These approaches either increase decoding time or require expensive training of the cross-attention layers. We propose SALSA, which couples the decoder layers of the ASR to the LLM decoder, while synchronously advancing both decoders. Such coupling is performed with a simple projection of the last decoder state, and is thus significantly more training efficient than earlier approaches. A challenge of our proposed coupling is handling the mismatch between the tokenizers of the LLM and ASR systems. We handle this mismatch using cascading tokenization with respect to the LLM and ASR vocabularies. We evaluate SALSA on 8 low-resource languages in the FLEURS benchmark, yielding substantial WER reductions of up to 38%.
Improving Self-supervised Pre-training using Accent-Specific Codebooks
Jul 04, 2024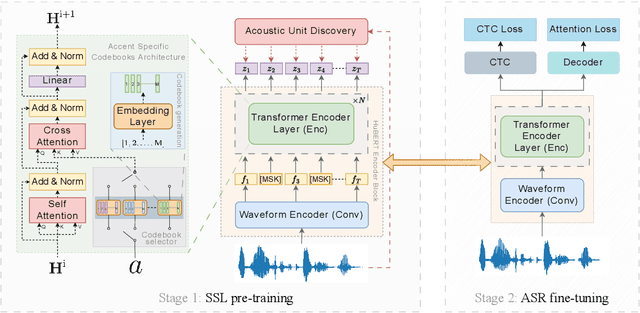


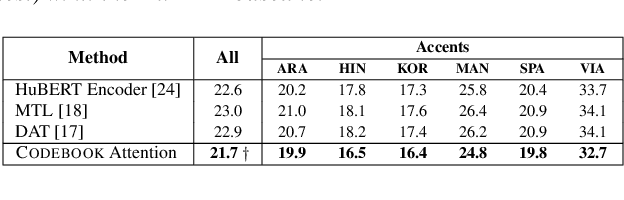
Speech accents present a serious challenge to the performance of state-of-the-art end-to-end Automatic Speech Recognition (ASR) systems. Even with self-supervised learning and pre-training of ASR models, accent invariance is seldom achieved. In this work, we propose an accent-aware adaptation technique for self-supervised learning that introduces a trainable set of accent-specific codebooks to the self-supervised architecture. These learnable codebooks enable the model to capture accent specific information during pre-training, that is further refined during ASR finetuning. On the Mozilla Common Voice dataset, our proposed approach outperforms all other accent-adaptation approaches on both seen and unseen English accents, with up to 9% relative reduction in word error rate (WER).
Multi-Convformer: Extending Conformer with Multiple Convolution Kernels
Jul 04, 2024



Convolutions have become essential in state-of-the-art end-to-end Automatic Speech Recognition~(ASR) systems due to their efficient modelling of local context. Notably, its use in Conformers has led to superior performance compared to vanilla Transformer-based ASR systems. While components other than the convolution module in the Conformer have been reexamined, altering the convolution module itself has been far less explored. Towards this, we introduce Multi-Convformer that uses multiple convolution kernels within the convolution module of the Conformer in conjunction with gating. This helps in improved modeling of local dependencies at varying granularities. Our model rivals existing Conformer variants such as CgMLP and E-Branchformer in performance, while being more parameter efficient. We empirically compare our approach with Conformer and its variants across four different datasets and three different modelling paradigms and show up to 8% relative word error rate~(WER) improvements.
Efficient infusion of self-supervised representations in Automatic Speech Recognition
Apr 19, 2024



Self-supervised learned (SSL) models such as Wav2vec and HuBERT yield state-of-the-art results on speech-related tasks. Given the effectiveness of such models, it is advantageous to use them in conventional ASR systems. While some approaches suggest incorporating these models as a trainable encoder or a learnable frontend, training such systems is extremely slow and requires a lot of computation cycles. In this work, we propose two simple approaches that use (1) framewise addition and (2) cross-attention mechanisms to efficiently incorporate the representations from the SSL model(s) into the ASR architecture, resulting in models that are comparable in size with standard encoder-decoder conformer systems while also avoiding the usage of SSL models during training. Our approach results in faster training and yields significant performance gains on the Librispeech and Tedlium datasets compared to baselines. We further provide detailed analysis and ablation studies that demonstrate the effectiveness of our approach.
Accented Speech Recognition With Accent-specific Codebooks
Oct 27, 2023



Speech accents pose a significant challenge to state-of-the-art automatic speech recognition (ASR) systems. Degradation in performance across underrepresented accents is a severe deterrent to the inclusive adoption of ASR. In this work, we propose a novel accent adaptation approach for end-to-end ASR systems using cross-attention with a trainable set of codebooks. These learnable codebooks capture accent-specific information and are integrated within the ASR encoder layers. The model is trained on accented English speech, while the test data also contained accents which were not seen during training. On the Mozilla Common Voice multi-accented dataset, we show that our proposed approach yields significant performance gains not only on the seen English accents (up to $37\%$ relative improvement in word error rate) but also on the unseen accents (up to $5\%$ relative improvement in WER). Further, we illustrate benefits for a zero-shot transfer setup on the L2Artic dataset. We also compare the performance with other approaches based on accent adversarial training.