 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diffusion-Driven Fine-Grained Nodule Synthesis Framework for Enhanced Lung Nodule Detection from Chest Radiographs
Mar 02, 2026Early detection of lung cancer in chest radiographs (CXRs) is crucial for improving patient outcomes, yet nodule detection remains challenging due to their subtle appearance and variability in radiological characteristics like size, texture, and boundary. For robust analysis, this diversity must be well represented in training datasets for deep learning based Computer-Assisted Diagnosis (CAD) systems. However, assembling such datasets is costly and often impractical, motivating the need for realistic synthetic data generation. Existing methods lack fine-grained control over synthetic nodule generation, limiting their utility in addressing data scarcity. This paper proposes a novel diffusion-based framework with low-rank adaptation (LoRA) adapters for characteristic controlled nodule synthesis on CXRs. We begin by addressing size and shape control through nodule mask conditioned training of the base diffusion model. To achieve individual characteristic control, we train separate LoRA modules, each dedicated to a specific radiological feature. However, since nodules rarely exhibit isolated characteristics, effective multi-characteristic control requires a balanced integration of features. We address this by leveraging the dynamic composability of LoRAs and revisiting existing merging strategies. Building on this, we identify two key issues, overlapping attention regions and non-orthogonal parameter spaces. To overcome these limitations, we introduce a novel orthogonality loss term during LoRA composition training. Extensive experiments on both in-house and public datasets demonstrate improved downstream nodule detection. Radiologist evaluations confirm the fine-grained controllability of our generated nodules, and across multiple quantitative metrics, our method surpasses existing nodule generation approaches for CXRs.
DiffusionXRay: A Diffusion and GAN-Based Approach for Enhancing Digitally Reconstructed Chest Radiographs
Mar 02, 2026Deep learning-based automated diagnosis of lung cancer has emerged as a crucial advancement that enables healthcare professionals to detect and initiate treatment earlier. However, these models require extensive training datasets with diverse case-specific properties. High-quality annotated data is particularly challenging to obtain, especially for cases with subtle pulmonary nodules that are difficult to detect even for experienced radiologists. This scarcity of well-labeled datasets can limit model performance and generalization across different patient populations. Digitally reconstructed radiographs (DRR) using CT-Scan to generate synthetic frontal chest X-rays with artificially inserted lung nodules offers one potential solution. However, this approach suffers from significant image quality degradation, particularly in the form of blurred anatomical features and loss of fine lung field structures. To overcome this, we introduce DiffusionXRay, a novel image restoration pipeline for Chest X-ray images that synergistically leverages denoising diffusion probabilistic models (DDPMs) and generative adversarial networks (GANs). DiffusionXRay incorporates a unique two-stage training process: First, we investigate two independent approaches, DDPM-LQ and GAN-based MUNIT-LQ, to generate low-quality CXRs, addressing the challenge of training data scarcity, posing this as a style transfer problem. Subsequently, we train a DDPM-based model on paired low-quality and high-quality images, enabling it to learn the nuances of X-ray image restoration. Our method demonstrates promising results in enhancing image clarity, contrast, and overall diagnostic value of chest X-rays while preserving subtle yet clinically significant artifacts, validated by both quantitative metrics and expert radiological assessment.
* Published at MICCAI 2025
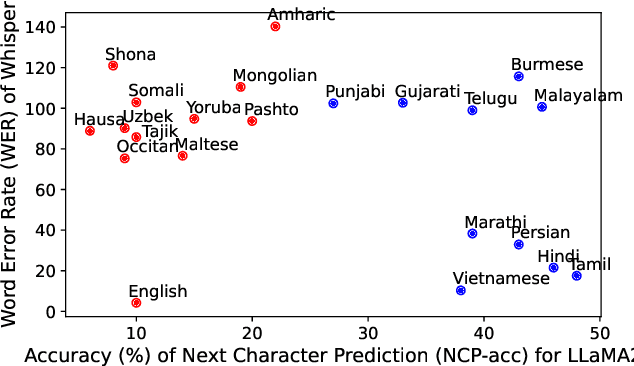
Dynamic Multi-Expert Projectors with Stabilized Routing for Multilingual Speech Recognition
Jan 27, 2026Recent advances in LLM-based ASR connect frozen speech encoders with Large Language Models (LLMs) via lightweight projectors. While effective in monolingual settings, a single projector struggles to capture the diverse acoustic-to-semantic mappings required for multilingual ASR. To address this, we propose SMEAR-MoE, a stabilized Mixture-of-Experts projector that ensures dense gradient flow to all experts, preventing expert collapse while enabling cross-lingual sharing. We systematically compare monolithic, static multi-projector, and dynamic MoE designs across four Indic languages (Hindi, Marathi, Tamil, Telugu). Our SMEAR-MoE achieves strong performance, delivering upto a 7.6% relative WER reduction over the single-projector baseline, while maintaining comparable runtime efficiency. Analysis of expert routing further shows linguistically meaningful specialization, with related languages sharing experts. These results demonstrate that stable multi-expert projectors are key to scalable and robust multilingual ASR.
Lost in Transcription: How Speech-to-Text Errors Derail Code Understanding
Jan 20, 2026Code understanding is a foundational capability in software engineering tools and developer workflows. However, most existing systems are designed for English-speaking users interacting via keyboards, which limits accessibility in multilingual and voice-first settings, particularly in regions like India. Voice-based interfaces offer a more inclusive modality, but spoken queries involving code present unique challenges due to the presence of non-standard English usage, domain-specific vocabulary, and custom identifiers such as variable and function names, often combined with code-mixed expressions. In this work, we develop a multilingual speech-driven framework for code understanding that accepts spoken queries in a user native language, transcribes them using Automatic Speech Recognition (ASR), applies code-aware ASR output refinement using Large Language Models (LLMs), and interfaces with code models to perform tasks such as code question answering and code retrieval through benchmarks such as CodeSearchNet, CoRNStack, and CodeQA. Focusing on four widely spoken Indic languages and English, we systematically characterize how transcription errors impact downstream task performance. We also identified key failure modes in ASR for code and demonstrated that LLM-guided refinement significantly improves performance across both transcription and code understanding stages. Our findings underscore the need for code-sensitive adaptations in speech interfaces and offer a practical solution for building robust, multilingual voice-driven programming tools.
Mathematics Isn't Culture-Free: Probing Cultural Gaps via Entity and Scenario Perturbations
Jul 01, 2025



Although mathematics is often considered culturally neutral, the way mathematical problems are presented can carry implicit cultural context. Existing benchmarks like GSM8K are predominantly rooted in Western norms, including names, currencies, and everyday scenarios. In this work, we create culturally adapted variants of the GSM8K test set for five regions Africa, India, China, Korea, and Japan using prompt-based transformations followed by manual verification. We evaluate six large language models (LLMs), ranging from 8B to 72B parameters, across five prompting strategies to assess their robustness to cultural variation in math problem presentation. Our findings reveal a consistent performance gap: models perform best on the original US-centric dataset and comparatively worse on culturally adapted versions. However, models with reasoning capabilities are more resilient to these shifts, suggesting that deeper reasoning helps bridge cultural presentation gaps in mathematical tasks
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
SALSA: Speedy ASR-LLM Synchronous Aggregation
Aug 29, 2024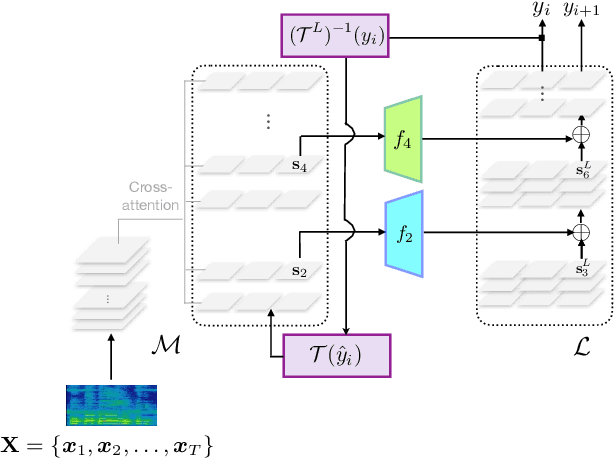


Harnessing pre-trained LLMs to improve ASR systems, particularly for low-resource languages, is now an emerging area of research. Existing methods range from using LLMs for ASR error correction to tightly coupled systems that replace the ASR decoder with the LLM. These approaches either increase decoding time or require expensive training of the cross-attention layers. We propose SALSA, which couples the decoder layers of the ASR to the LLM decoder, while synchronously advancing both decoders. Such coupling is performed with a simple projection of the last decoder state, and is thus significantly more training efficient than earlier approaches. A challenge of our proposed coupling is handling the mismatch between the tokenizers of the LLM and ASR systems. We handle this mismatch using cascading tokenization with respect to the LLM and ASR vocabularies. We evaluate SALSA on 8 low-resource languages in the FLEURS benchmark, yielding substantial WER reductions of up to 38%.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 24, 2023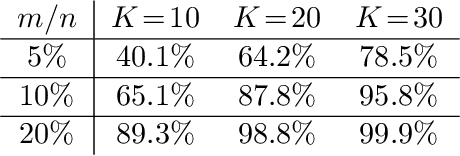
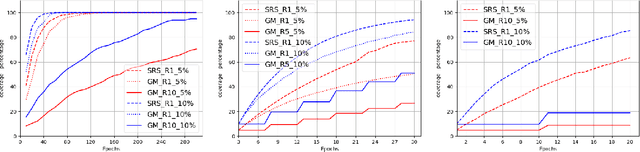
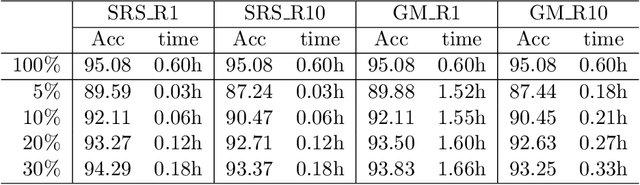
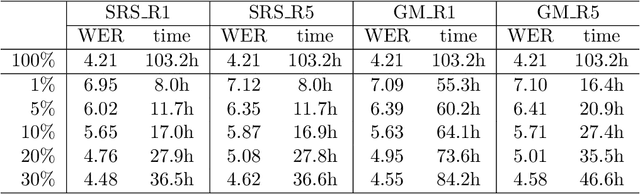
Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
Improving RNN-Transducers with Acoustic LookAhead
Jul 11, 2023



RNN-Transducers (RNN-Ts) have gained widespread acceptance as an end-to-end model for speech to text conversion because of their high accuracy and streaming capabilities. A typical RNN-T independently encodes the input audio and the text context, and combines the two encodings by a thin joint network. While this architecture provides SOTA streaming accuracy, it also makes the model vulnerable to strong LM biasing which manifests as multi-step hallucination of text without acoustic evidence. In this paper we propose LookAhead that makes text representations more acoustically grounded by looking ahead into the future within the audio input. This technique yields a significant 5%-20% relative reduction in word error rate on both in-domain and out-of-domain evaluation sets.
Partitioned Gradient Matching-based Data Subset Selection for Compute-Efficient Robust ASR Training
Oct 30, 2022



Training state-of-the-art ASR systems such as RNN-T often has a high associated financial and environmental cost. Training with a subset of training data could mitigate this problem if the subset selected could achieve on-par performance with training with the entire dataset. Although there are many data subset selection(DSS) algorithms, direct application to the RNN-T is difficult, especially the DSS algorithms that are adaptive and use learning dynamics such as gradients, as RNN-T tend to have gradients with a significantly larger memory footprint. In this paper, we propose Partitioned Gradient Matching (PGM) a novel distributable DSS algorithm, suitable for massive datasets like those used to train RNN-T. Through extensive experiments on Librispeech 100H and Librispeech 960H, we show that PGM achieves between 3x to 6x speedup with only a very small accuracy degradation (under 1% absolute WER difference). In addition, we demonstrate similar results for PGM even in settings where the training data is corrupted with noise.