 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023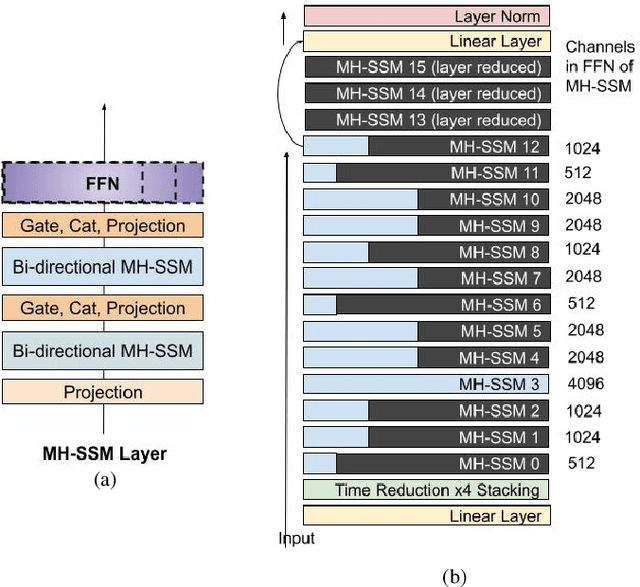
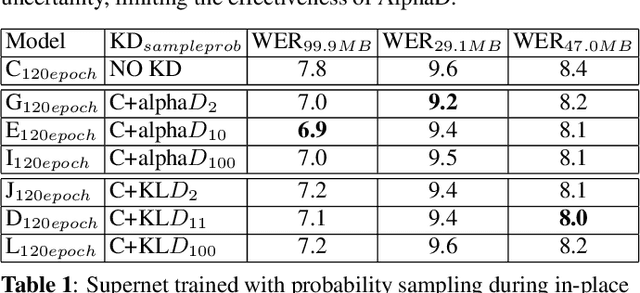
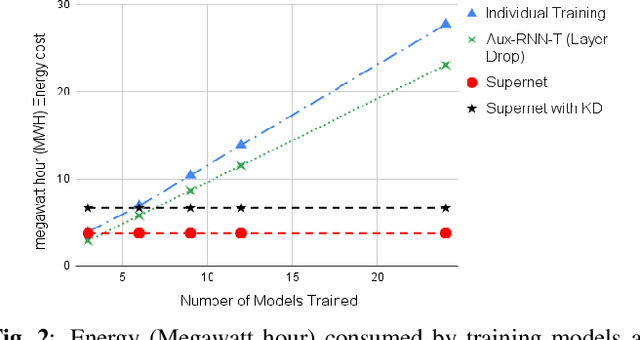
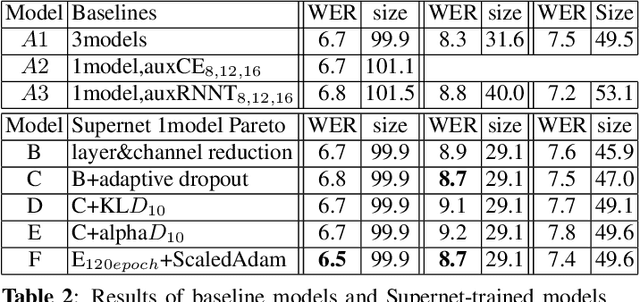
Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
Unified Semantic Parsing with Weak Supervision
Jun 12, 2019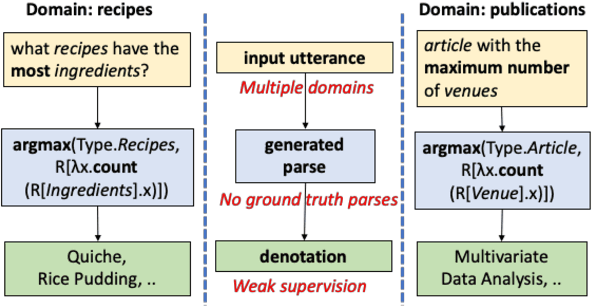
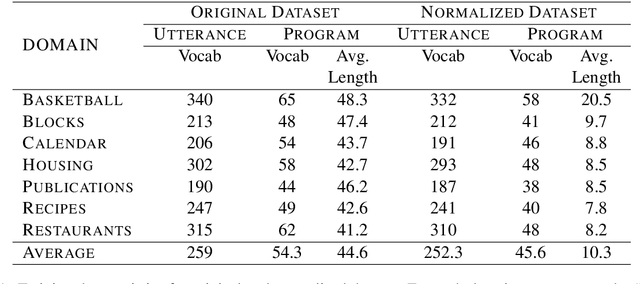

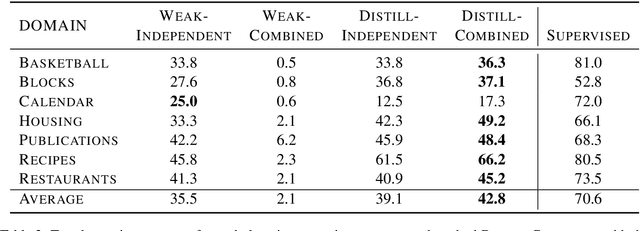
Semantic parsing over multiple knowledge bases enables a parser to exploit structural similarities of programs across the multiple domains. However, the fundamental challenge lies in obtaining high-quality annotations of (utterance, program) pairs across various domains needed for training such models. To overcome this, we propose a novel framework to build a unified multi-domain enabled semantic parser trained only with weak supervision (denotations). Weakly supervised training is particularly arduous as the program search space grows exponentially in a multi-domain setting. To solve this, we incorporate a multi-policy distillation mechanism in which we first train domain-specific semantic parsers (teachers) using weak supervision in the absence of the ground truth programs, followed by training a single unified parser (student) from the domain specific policies obtained from these teachers. The resultant semantic parser is not only compact but also generalizes better, and generates more accurate programs. It further does not require the user to provide a domain label while querying. On the standard Overnight dataset (containing multiple domains), we demonstrate that the proposed model improves performance by 20% in terms of denotation accuracy in comparison to baseline techniques.
Styling with Attention to Details
Jul 03, 2018



Fashion as characterized by its nature, is driven by style. In this paper, we propose a method that takes into account the style information to complete a given set of selected fashion items with a complementary fashion item. Complementary items are those items that can be worn along with the selected items according to the style. Addressing this problem facilitates in automatically generating stylish fashion ensembles leading to a richer shopping experience for users. Recently, there has been a surge of online social websites where fashion enthusiasts post the outfit of the day and other users can like and comment on them. These posts contain a gold-mine of information about style. In this paper, we exploit these posts to train a deep neural network which captures style in an automated manner. We pose the problem of predicting complementary fashion items as a sequence to sequence problem where the input is the selected set of fashion items and the output is a complementary fashion item based on the style information learned by the model. We use the encoder decoder architecture to solve this problem of completing the set of fashion items. We evaluate the goodness of the proposed model through a variety of experiments. We empirically observe that our proposed model outperforms competitive baseline like apriori algorithm by ~28 in terms of accuracy for top-1 recommendation to complete the fashion ensemble. We also perform retrieval based experiments to understand the ability of the model to learn style and rank the complementary fashion items and find that using attention in our encoder decoder model helps in improving the mean reciprocal rank by ~24. Qualitatively we find the complementary fashion items generated by our proposed model are richer than the apriori algorithm.