 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Sep 17, 2025Where do learning signals come from when there is no ground truth in post-training? We propose turning exploration into supervision through Compute as Teacher (CaT), which converts the model's own exploration at inference-time into reference-free supervision by synthesizing a single reference from a group of parallel rollouts and then optimizing toward it. Concretely, the current policy produces a group of rollouts; a frozen anchor (the initial policy) reconciles omissions and contradictions to estimate a reference, turning extra inference-time compute into a teacher signal. We turn this into rewards in two regimes: (i) verifiable tasks use programmatic equivalence on final answers; (ii) non-verifiable tasks use self-proposed rubrics-binary, auditable criteria scored by an independent LLM judge, with reward given by the fraction satisfied. Unlike selection methods (best-of-N, majority, perplexity, or judge scores), synthesis may disagree with the majority and be correct even when all rollouts are wrong; performance scales with the number of rollouts. As a test-time procedure, CaT improves Gemma 3 4B, Qwen 3 4B, and Llama 3.1 8B (up to +27% on MATH-500; +12% on HealthBench). With reinforcement learning (CaT-RL), we obtain further gains (up to +33% and +30%), with the trained policy surpassing the initial teacher signal.
Structsum Generation for Faster Text Comprehension
Jan 12, 2024



We consider the task of generating structured representations of text using large language models (LLMs). We focus on tables and mind maps as representative modalities. Tables are more organized way of representing data, while mind maps provide a visually dynamic and flexible approach, particularly suitable for sparse content. Despite the effectiveness of LLMs on different tasks, we show that current models struggle with generating structured outputs. In response, we present effective prompting strategies for both of these tasks. We introduce a taxonomy of problems around factuality, global and local structure, common to both modalities and propose a set of critiques to tackle these issues resulting in an absolute improvement in accuracy of +37pp (79%) for mind maps and +15pp (78%) for tables. To evaluate semantic coverage of generated structured representations we propose Auto-QA, and we verify the adequacy of Auto-QA using SQuAD dataset. We further evaluate the usefulness of structured representations via a text comprehension user study. The results show a significant reduction in comprehension time compared to text when using table (42.9%) and mind map (31.9%), without loss in accuracy.
Conversational Semantic Parsing using Dynamic Context Graphs
May 04, 2023



In this paper we consider the task of conversational semantic parsing over general purpose knowledge graphs (KGs) with millions of entities, and thousands of relation-types. We are interested in developing models capable of interactively mapping user utterances into executable logical forms (e.g., SPARQL) in the context of the conversational history. Our key idea is to represent information about an utterance and its context via a subgraph which is created dynamically, i.e., the number of nodes varies per utterance. Moreover, rather than treating the subgraph as a sequence we exploit its underlying structure, and thus encode it using a graph neural network which further allows us to represent a large number of (unseen) nodes. Experimental results show that modeling context dynamically is superior to static approaches, delivering performance improvements across the board (i.e., for simple and complex questions). Our results further confirm that modeling the structure of context is better at processing discourse information, (i.e., at handling ellipsis and resolving coreference) and longer interactions.
Semantic Parsing for Conversational Question Answering over Knowledge Graphs
Jan 28, 2023



In this paper, we are interested in developing semantic parsers which understand natural language questions embedded in a conversation with a user and ground them to formal queries over definitions in a general purpose knowledge graph (KG) with very large vocabularies (covering thousands of concept names and relations, and millions of entities). To this end, we develop a dataset where user questions are annotated with Sparql parses and system answers correspond to execution results thereof. We present two different semantic parsing approaches and highlight the challenges of the task: dealing with large vocabularies, modelling conversation context, predicting queries with multiple entities, and generalising to new questions at test time. We hope our dataset will serve as useful testbed for the development of conversational semantic parsers. Our dataset and models are released at https://github.com/EdinburghNLP/SPICE.
Unified Semantic Parsing with Weak Supervision
Jun 12, 2019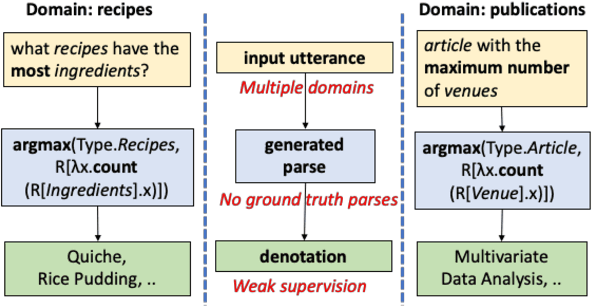
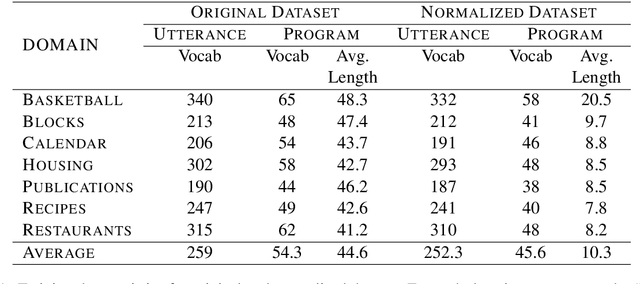

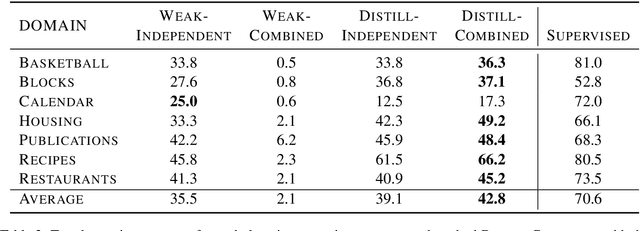
Semantic parsing over multiple knowledge bases enables a parser to exploit structural similarities of programs across the multiple domains. However, the fundamental challenge lies in obtaining high-quality annotations of (utterance, program) pairs across various domains needed for training such models. To overcome this, we propose a novel framework to build a unified multi-domain enabled semantic parser trained only with weak supervision (denotations). Weakly supervised training is particularly arduous as the program search space grows exponentially in a multi-domain setting. To solve this, we incorporate a multi-policy distillation mechanism in which we first train domain-specific semantic parsers (teachers) using weak supervision in the absence of the ground truth programs, followed by training a single unified parser (student) from the domain specific policies obtained from these teachers. The resultant semantic parser is not only compact but also generalizes better, and generates more accurate programs. It further does not require the user to provide a domain label while querying. On the standard Overnight dataset (containing multiple domains), we demonstrate that the proposed model improves performance by 20% in terms of denotation accuracy in comparison to baseline techniques.
Unsupervised Neural Text Simplification
Oct 18, 2018
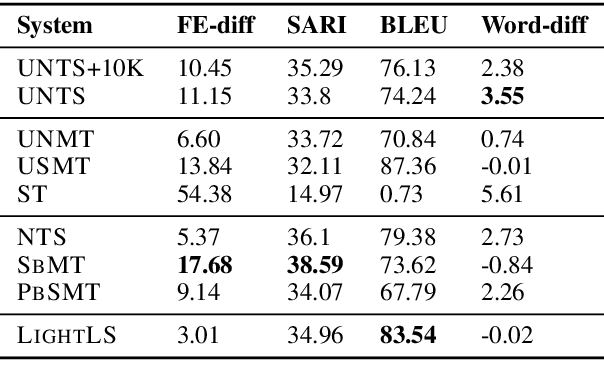
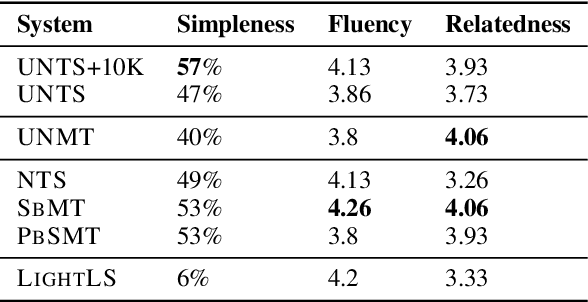
The paper presents a first attempt towards unsupervised neural text simplification that relies only on unlabeled text corpora. The core framework is comprised of a shared encoder and a pair of attentional-decoders that gains knowledge of both text simplification and complexification through discriminator-based-losses, back-translation and denoising. The framework is trained using unlabeled text collected from en-Wikipedia dump. Our analysis (both quantitative and qualitative involving human evaluators) on a public test data shows the efficacy of our model to perform simplification at both lexical and syntactic levels, competitive to existing supervised methods. We open source our implementation for academic use.
Unsupervised Controllable Text Formalization
Sep 10, 2018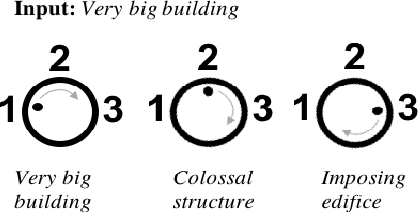
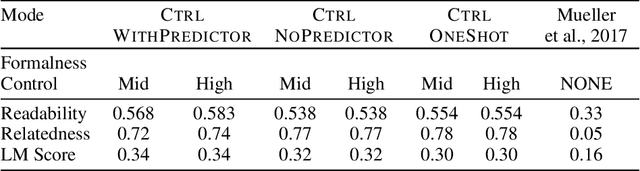
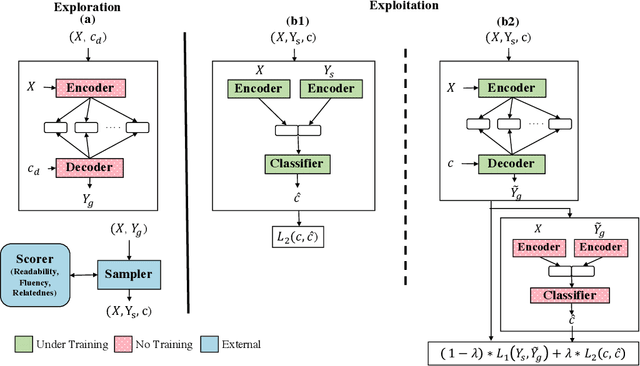
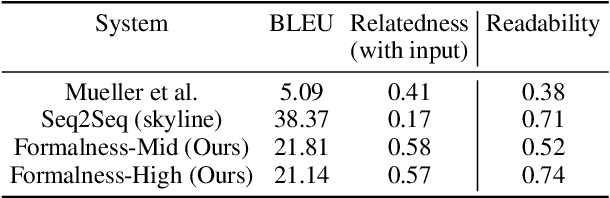
We propose a novel framework for controllable natural language transformation. Realizing that the requirement of parallel corpus is practically unsustainable for controllable generation tasks, an unsupervised training scheme is introduced. The crux of the framework is a deep neural encoder-decoder that is reinforced with text-transformation knowledge through auxiliary modules (called scorers). The scorers, based on off-the-shelf language processing tools, decide the learning scheme of the encoder-decoder based on its actions. We apply this framework for the text-transformation task of formalizing an input text by improving its readability grade; the degree of required formalization can be controlled by the user at run-time. Experiments on public datasets demonstrate the efficacy of our model towards: (a) transforming a given text to a more formal style, and (b) introducing appropriate amount of formalness in the output text pertaining to the input control. Our code and datasets are released for academic use.
A Mixed Hierarchical Attention based Encoder-Decoder Approach for Standard Table Summarization
Apr 20, 2018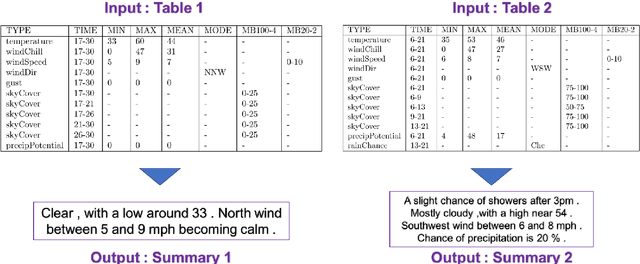
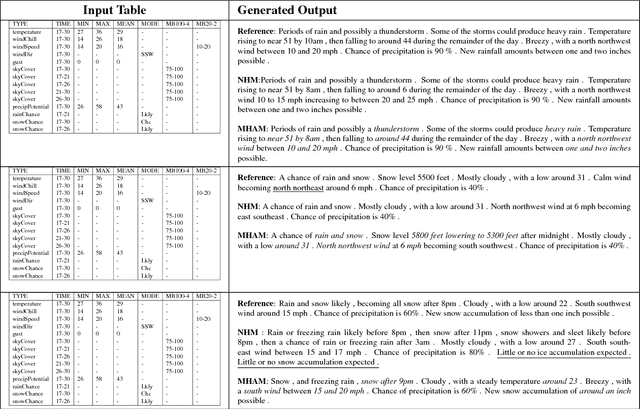
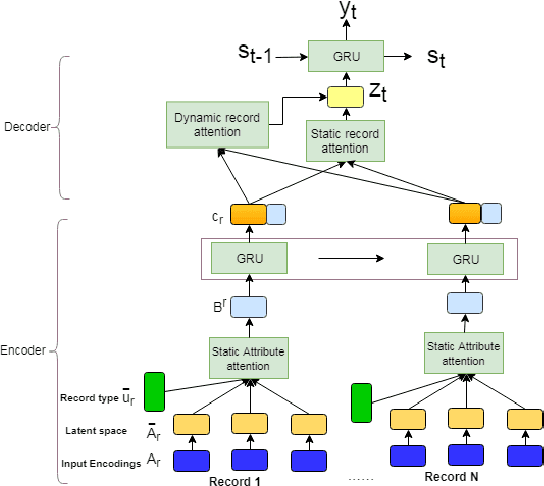
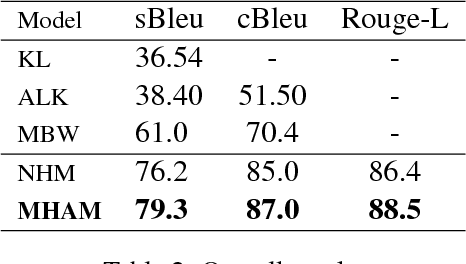
Structured data summarization involves generation of natural language summaries from structured input data. In this work, we consider summarizing structured data occurring in the form of tables as they are prevalent across a wide variety of domains. We formulate the standard table summarization problem, which deals with tables conforming to a single predefined schema. To this end, we propose a mixed hierarchical attention based encoder-decoder model which is able to leverage the structure in addition to the content of the tables. Our experiments on the publicly available WEATHERGOV dataset show around 18 BLEU (~ 30%) improvement over the current state-of-the-art.