 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTOAT: Structured Data to Analytical Text With Controls
May 19, 2023Recent language models have made tremendous progress in the structured data to text generation task. However, these models still give sub-optimal performance where logical inference is required to generate the descriptions. In this work, we specifically focus on analytical text generation from structured data such as tables. Building on the taxonomy proposed in (Gupta et al., 2020) we focus on controllable table to text generation for the following reasoning categories: numerical reasoning, commonsense reasoning, temporal reasoning, table knowledge, and entity knowledge. We propose STOAT model, which is table and reasoning aware, with vector-quantization to infuse the given reasoning categories in the output. We observe that our model provides 10.19%, 1.13% improvement on the PARENT metric in iToTTo and Infotabs for the analytical sentence task. We also found that our model generates 15.3% more faithful and analytical descriptions as compared to the baseline models in human evaluation. We curate and release two reasoning category annotated table-to-interesting text generation datasets based on the ToTTo (Parikh et al., 2020) and InfoTabs datasets (Gupta et al.,2020).
T-STAR: Truthful Style Transfer using AMR Graph as Intermediate Representation
Dec 03, 2022



Unavailability of parallel corpora for training text style transfer (TST) models is a very challenging yet common scenario. Also, TST models implicitly need to preserve the content while transforming a source sentence into the target style. To tackle these problems, an intermediate representation is often constructed that is devoid of style while still preserving the meaning of the source sentence. In this work, we study the usefulness of Abstract Meaning Representation (AMR) graph as the intermediate style agnostic representation. We posit that semantic notations like AMR are a natural choice for an intermediate representation. Hence, we propose T-STAR: a model comprising of two components, text-to-AMR encoder and a AMR-to-text decoder. We propose several modeling improvements to enhance the style agnosticity of the generated AMR. To the best of our knowledge, T-STAR is the first work that uses AMR as an intermediate representation for TST. With thorough experimental evaluation we show T-STAR significantly outperforms state of the art techniques by achieving on an average 15.2% higher content preservation with negligible loss (3% approx.) in style accuracy. Through detailed human evaluation with 90,000 ratings, we also show that T-STAR has up to 50% lesser hallucinations compared to state of the art TST models.
A Framework for Rationale Extraction for Deep QA models
Oct 09, 2021
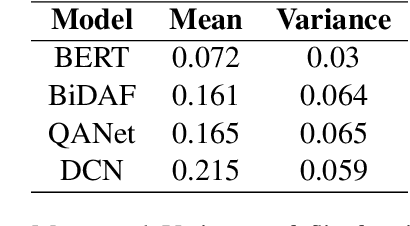

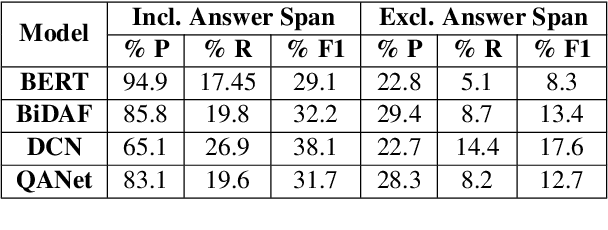
As neural-network-based QA models become deeper and more complex, there is a demand for robust frameworks which can access a model's rationale for its prediction. Current techniques that provide insights on a model's working are either dependent on adversarial datasets or are proposing models with explicit explanation generation components. These techniques are time-consuming and challenging to extend to existing models and new datasets. In this work, we use `Integrated Gradients' to extract rationale for existing state-of-the-art models in the task of Reading Comprehension based Question Answering (RCQA). On detailed analysis and comparison with collected human rationales, we find that though ~40-80% words of extracted rationale coincide with the human rationale (precision), only 6-19% of human rationale is present in the extracted rationale (recall).
The heads hypothesis: A unifying statistical approach towards understanding multi-headed attention in BERT
Jan 22, 2021
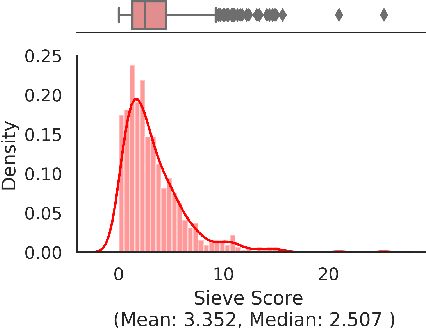
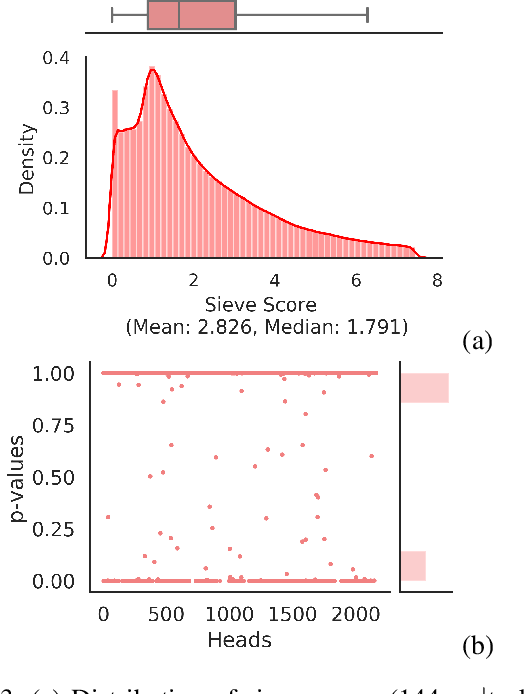
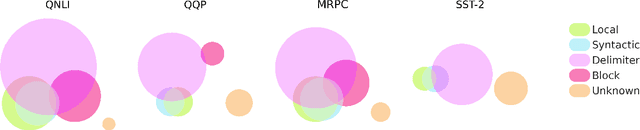
Multi-headed attention heads are a mainstay in transformer-based models. Different methods have been proposed to classify the role of each attention head based on the relations between tokens which have high pair-wise attention. These roles include syntactic (tokens with some syntactic relation), local (nearby tokens), block (tokens in the same sentence) and delimiter (the special [CLS], [SEP] tokens). There are two main challenges with existing methods for classification: (a) there are no standard scores across studies or across functional roles, and (b) these scores are often average quantities measured across sentences without capturing statistical significance. In this work, we formalize a simple yet effective score that generalizes to all the roles of attention heads and employs hypothesis testing on this score for robust inference. This provides us the right lens to systematically analyze attention heads and confidently comment on many commonly posed questions on analyzing the BERT model. In particular, we comment on the co-location of multiple functional roles in the same attention head, the distribution of attention heads across layers, and effect of fine-tuning for specific NLP tasks on these functional roles.
Towards Interpreting BERT for Reading Comprehension Based QA
Oct 18, 2020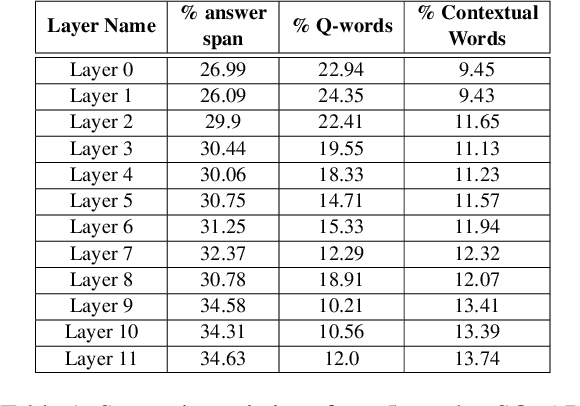

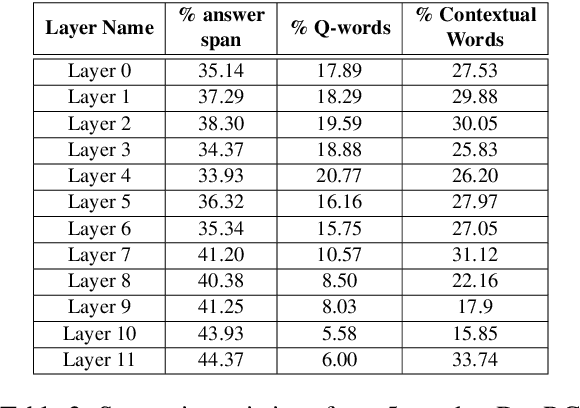
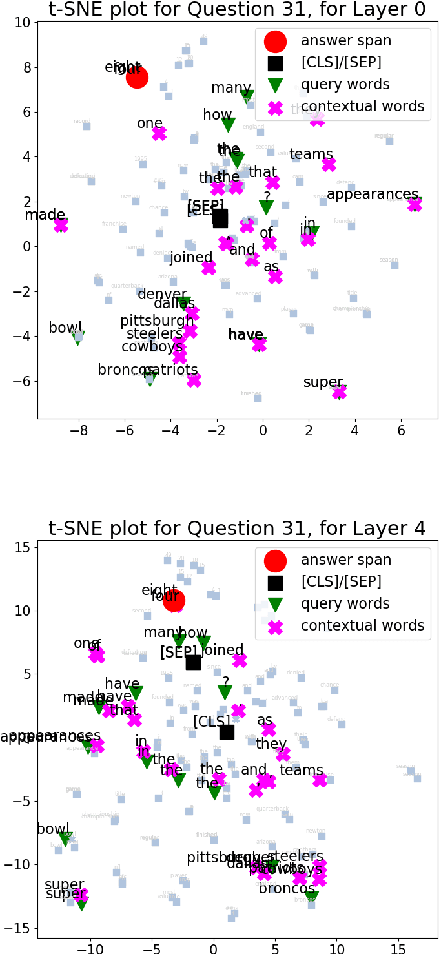
BERT and its variants have achieved state-of-the-art performance in various NLP tasks. Since then, various works have been proposed to analyze the linguistic information being captured in BERT. However, the current works do not provide an insight into how BERT is able to achieve near human-level performance on the task of Reading Comprehension based Question Answering. In this work, we attempt to interpret BERT for RCQA. Since BERT layers do not have predefined roles, we define a layer's role or functionality using Integrated Gradients. Based on the defined roles, we perform a preliminary analysis across all layers. We observed that the initial layers focus on query-passage interaction, whereas later layers focus more on contextual understanding and enhancing the answer prediction. Specifically for quantifier questions (how much/how many), we notice that BERT focuses on confusing words (i.e., on other numerical quantities in the passage) in the later layers, but still manages to predict the answer correctly. The fine-tuning and analysis scripts will be publicly available at https://github.com/iitmnlp/BERT-Analysis-RCQA .
On the Importance of Local Information in Transformer Based Models
Aug 13, 2020


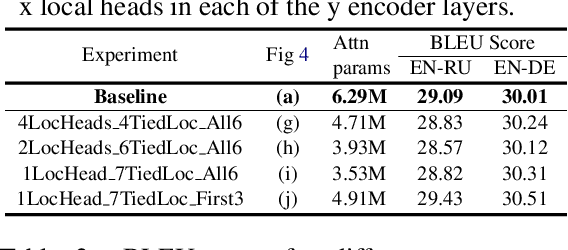
The self-attention module is a key component of Transformer-based models, wherein each token pays attention to every other token. Recent studies have shown that these heads exhibit syntactic, semantic, or local behaviour. Some studies have also identified promise in restricting this attention to be local, i.e., a token attending to other tokens only in a small neighbourhood around it. However, no conclusive evidence exists that such local attention alone is sufficient to achieve high accuracy on multiple NLP tasks. In this work, we systematically analyse the role of locality information in learnt models and contrast it with the role of syntactic information. More specifically, we first do a sensitivity analysis and show that, at every layer, the representation of a token is much more sensitive to tokens in a small neighborhood around it than to tokens which are syntactically related to it. We then define an attention bias metric to determine whether a head pays more attention to local tokens or to syntactically related tokens. We show that a larger fraction of heads have a locality bias as compared to a syntactic bias. Having established the importance of local attention heads, we train and evaluate models where varying fractions of the attention heads are constrained to be local. Such models would be more efficient as they would have fewer computations in the attention layer. We evaluate these models on 4 GLUE datasets (QQP, SST-2, MRPC, QNLI) and 2 MT datasets (En-De, En-Ru) and clearly demonstrate that such constrained models have comparable performance to the unconstrained models. Through this systematic evaluation we establish that attention in Transformer-based models can be constrained to be local without affecting performance.
Towards Transparent and Explainable Attention Models
Apr 29, 2020
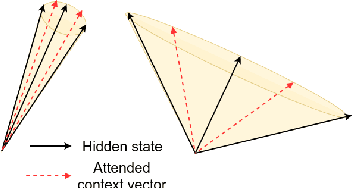
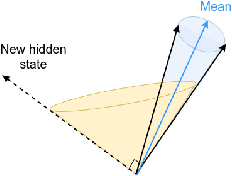
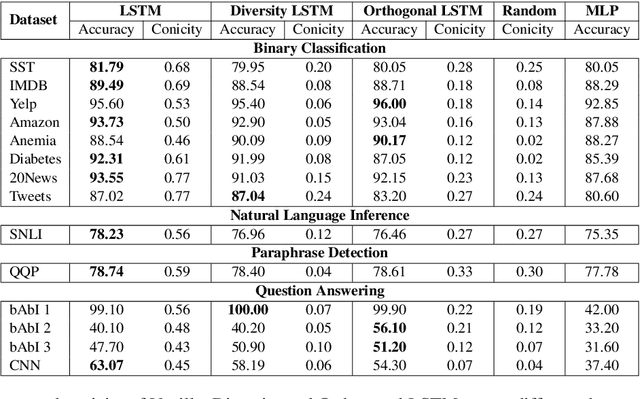
Recent studies on interpretability of attention distributions have led to notions of faithful and plausible explanations for a model's predictions. Attention distributions can be considered a faithful explanation if a higher attention weight implies a greater impact on the model's prediction. They can be considered a plausible explanation if they provide a human-understandable justification for the model's predictions. In this work, we first explain why current attention mechanisms in LSTM based encoders can neither provide a faithful nor a plausible explanation of the model's predictions. We observe that in LSTM based encoders the hidden representations at different time-steps are very similar to each other (high conicity) and attention weights in these situations do not carry much meaning because even a random permutation of the attention weights does not affect the model's predictions. Based on experiments on a wide variety of tasks and datasets, we observe attention distributions often attribute the model's predictions to unimportant words such as punctuation and fail to offer a plausible explanation for the predictions. To make attention mechanisms more faithful and plausible, we propose a modified LSTM cell with a diversity-driven training objective that ensures that the hidden representations learned at different time steps are diverse. We show that the resulting attention distributions offer more transparency as they (i) provide a more precise importance ranking of the hidden states (ii) are better indicative of words important for the model's predictions (iii) correlate better with gradient-based attribution methods. Human evaluations indicate that the attention distributions learned by our model offer a plausible explanation of the model's predictions. Our code has been made publicly available at https://github.com/akashkm99/Interpretable-Attention
Let's Ask Again: Refine Network for Automatic Question Generation
Aug 31, 2019
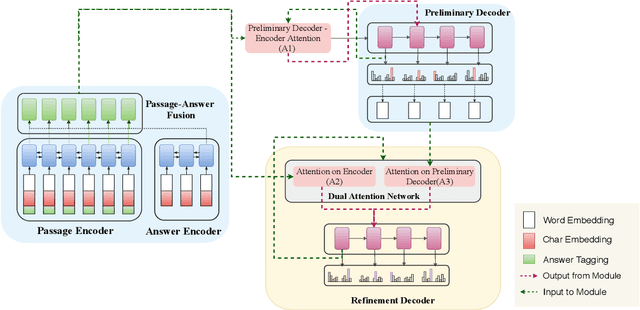

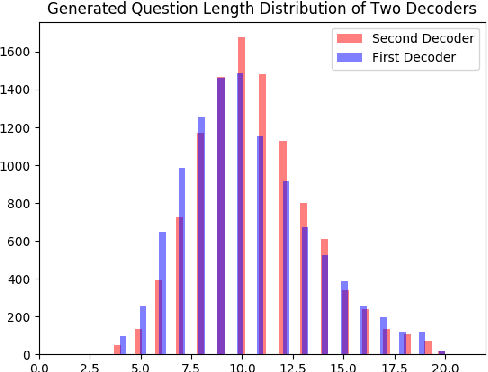
In this work, we focus on the task of Automatic Question Generation (AQG) where given a passage and an answer the task is to generate the corresponding question. It is desired that the generated question should be (i) grammatically correct (ii) answerable from the passage and (iii) specific to the given answer. An analysis of existing AQG models shows that they produce questions which do not adhere to one or more of {the above-mentioned qualities}. In particular, the generated questions look like an incomplete draft of the desired question with a clear scope for refinement. {To alleviate this shortcoming}, we propose a method which tries to mimic the human process of generating questions by first creating an initial draft and then refining it. More specifically, we propose Refine Network (RefNet) which contains two decoders. The second decoder uses a dual attention network which pays attention to both (i) the original passage and (ii) the question (initial draft) generated by the first decoder. In effect, it refines the question generated by the first decoder, thereby making it more correct and complete. We evaluate RefNet on three datasets, \textit{viz.}, SQuAD, HOTPOT-QA, and DROP, and show that it outperforms existing state-of-the-art methods by 7-16\% on all of these datasets. Lastly, we show that we can improve the quality of the second decoder on specific metrics, such as, fluency and answerability by explicitly rewarding revisions that improve on the corresponding metric during training. The code has been made publicly available \footnote{https://github.com/PrekshaNema25/RefNet-QG}
Frustratingly Poor Performance of Reading Comprehension Models on Non-adversarial Examples
Apr 04, 2019
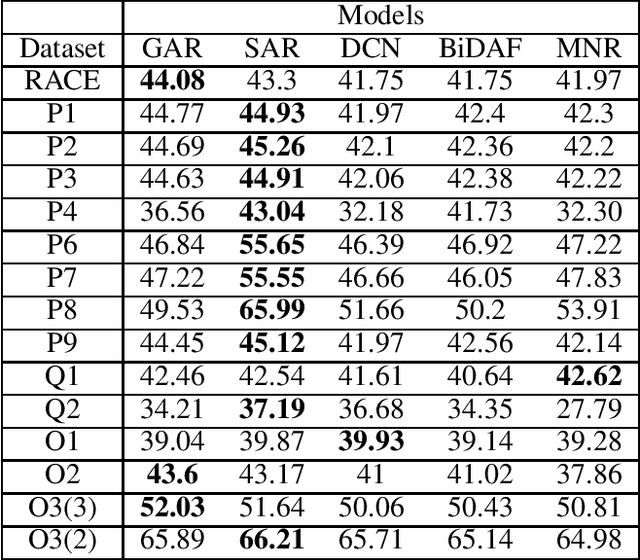

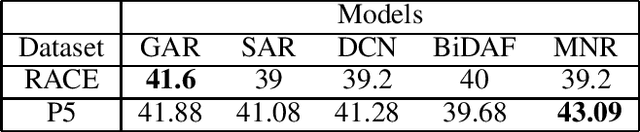
When humans learn to perform a difficult task (say, reading comprehension (RC) over longer passages), it is typically the case that their performance improves significantly on an easier version of this task (say, RC over shorter passages). Ideally, we would want an intelligent agent to also exhibit such a behavior. However, on experimenting with state of the art RC models using the standard RACE dataset, we observe that this is not true. Specifically, we see counter-intuitive results wherein even when we show frustratingly easy examples to the model at test time, there is hardly any improvement in its performance. We refer to this as non-adversarial evaluation as opposed to adversarial evaluation. Such non-adversarial examples allow us to assess the utility of specialized neural components. For example, we show that even for easy examples where the answer is clearly embedded in the passage, the neural components designed for paying attention to relevant portions of the passage fail to serve their intended purpose. We believe that the non-adversarial dataset created as a part of this work would complement the research on adversarial evaluation and give a more realistic assessment of the ability of RC models. All the datasets and codes developed as a part of this work will be made publicly available.
ElimiNet: A Model for Eliminating Options for Reading Comprehension with Multiple Choice Questions
Apr 04, 2019
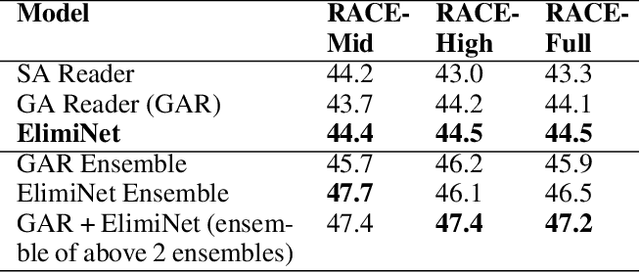
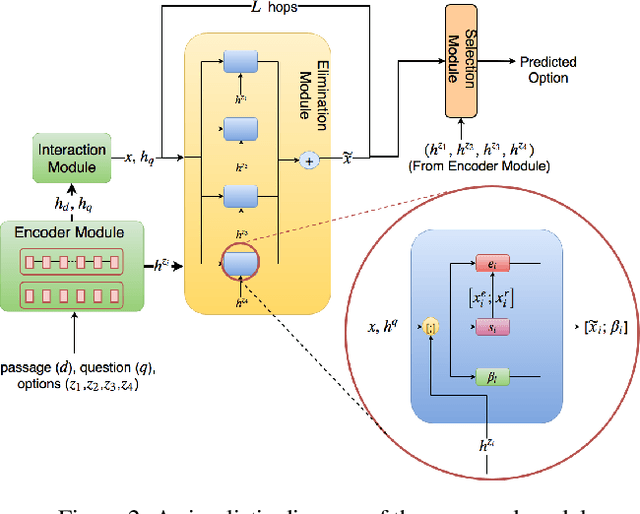
The task of Reading Comprehension with Multiple Choice Questions, requires a human (or machine) to read a given passage, question pair and select one of the n given options. The current state of the art model for this task first computes a question-aware representation for the passage and then selects the option which has the maximum similarity with this representation. However, when humans perform this task they do not just focus on option selection but use a combination of elimination and selection. Specifically, a human would first try to eliminate the most irrelevant option and then read the passage again in the light of this new information (and perhaps ignore portions corresponding to the eliminated option). This process could be repeated multiple times till the reader is finally ready to select the correct option. We propose ElimiNet, a neural network-based model which tries to mimic this process. Specifically, it has gates which decide whether an option can be eliminated given the passage, question pair and if so it tries to make the passage representation orthogonal to this eliminated option (akin to ignoring portions of the passage corresponding to the eliminated option). The model makes multiple rounds of partial elimination to refine the passage representation and finally uses a selection module to pick the best option. We evaluate our model on the recently released large scale RACE dataset and show that it outperforms the current state of the art model on 7 out of the $13$ question types in this dataset. Further, we show that taking an ensemble of our elimination-selection based method with a selection based method gives us an improvement of 3.1% over the best-reported performance on this dataset.
* IJCAI-18