 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Rationale Extraction for Deep QA models
Paper and Code
Oct 09, 2021
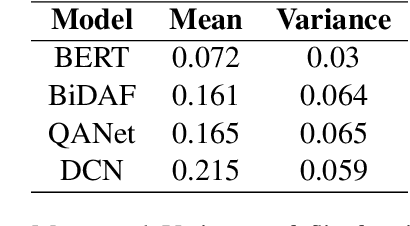

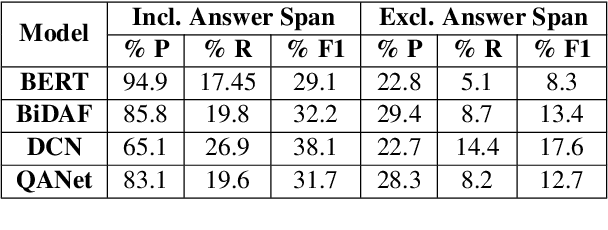
As neural-network-based QA models become deeper and more complex, there is a demand for robust frameworks which can access a model's rationale for its prediction. Current techniques that provide insights on a model's working are either dependent on adversarial datasets or are proposing models with explicit explanation generation components. These techniques are time-consuming and challenging to extend to existing models and new datasets. In this work, we use `Integrated Gradients' to extract rationale for existing state-of-the-art models in the task of Reading Comprehension based Question Answering (RCQA). On detailed analysis and comparison with collected human rationales, we find that though ~40-80% words of extracted rationale coincide with the human rationale (precision), only 6-19% of human rationale is present in the extracted rationale (recall).