 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Isn't Believing: Uncovering Blind Spots in Evaluator Vision-Language Models
Apr 23, 2026Large Vision-Language Models (VLMs) are increasingly used to evaluate outputs of other models, for image-to-text (I2T) tasks such as visual question answering, and text-to-image (T2I) generation tasks. Despite this growing reliance, the reliability of these Evaluator VLMs remains under explored. In this work, we systematically evaluate the reliability of Evaluator VLMs across both I2T and T2I tasks. We introduce targeted perturbations that degrade output quality along key error dimensions, including object hallucinations, spatial reasoning, factual grounding, and visual fidelity. These perturbations test whether Evaluator VLMs can reliably account for these quality degrading errors in their evaluations. Using a comprehensive benchmark of over 4000 perturbed instances spanning 40 perturbation dimensions, we evaluate 4 prominent VLMs using single-answer scoring, pairwise comparison, and reference-guided paradigms. Our findings reveal that current VLM evaluators exhibit substantial blind spots: they often fail to detect perturbed outputs - in some cases exceeding 50%, struggle particularly with fine-grained compositional and spatial errors, and are often insensitive to hallucinated content that contradicts the input image. Pairwise comparison proves more reliable, though failure rates persist. These results highlight the unreliable nature of current Evaluator VLMs and urge caution in their deployment for benchmarking and development decisions. Code and data have been made publicly available.
Voice of India: A Large-Scale Benchmark for Real-World Speech Recognition in India
Apr 21, 2026Existing Indic ASR benchmarks often use scripted, clean speech and leaderboard driven evaluation that encourages dataset specific overfitting. In addition, strict single reference WER penalizes natural spelling variation in Indian languages, including non standardized spellings of code-mixed English origin words. To address these limitations, we introduce Voice of India, a closed source benchmark built from unscripted telephonic conversations covering 15 major Indian languages across 139 regional clusters. The dataset contains 306230 utterances, totaling 536 hours of speech from 36691 speakers with transcripts accounting for spelling variations. We also analyze performance geographically at the district level, revealing disparities. Finally, we provide detailed analysis across factors such as audio quality, speaking rate, gender, and device type, highlighting where current ASR systems struggle and offering insights for improving real world Indic ASR systems.
Towards Orthographically-Informed Evaluation of Speech Recognition Systems for Indian Languages
Mar 01, 2026Evaluating ASR systems for Indian languages is challenging due to spelling variations, suffix splitting flexibility, and non-standard spellings in code-mixed words. Traditional Word Error Rate (WER) often presents a bleaker picture of system performance than what human users perceive. Better aligning evaluation with real-world performance requires capturing permissible orthographic variations, which is extremely challenging for under-resourced Indian languages. Leveraging recent advances in LLMs, we propose a framework for creating benchmarks that capture permissible variations. Through extensive experiments, we demonstrate that OIWER, by accounting for orthographic variations, reduces pessimistic error rates (an average improvement of 6.3 points), narrows inflated model gaps (e.g., Gemini-Canary performance difference drops from 18.1 to 11.5 points), and aligns more closely with human perception than prior methods like WER-SN by 4.9 points.
The State Of TTS: A Case Study with Human Fooling Rates
Aug 06, 2025


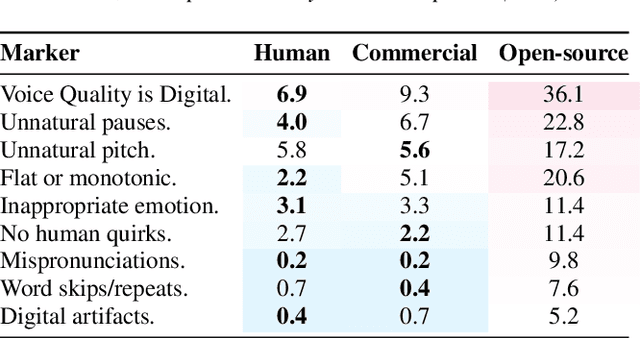
While subjective evaluations in recent years indicate rapid progress in TTS, can current TTS systems truly pass a human deception test in a Turing-like evaluation? We introduce Human Fooling Rate (HFR), a metric that directly measures how often machine-generated speech is mistaken for human. Our large-scale evaluation of open-source and commercial TTS models reveals critical insights: (i) CMOS-based claims of human parity often fail under deception testing, (ii) TTS progress should be benchmarked on datasets where human speech achieves high HFRs, as evaluating against monotonous or less expressive reference samples sets a low bar, (iii) Commercial models approach human deception in zero-shot settings, while open-source systems still struggle with natural conversational speech; (iv) Fine-tuning on high-quality data improves realism but does not fully bridge the gap. Our findings underscore the need for more realistic, human-centric evaluations alongside existing subjective tests.
Recognizing Every Voice: Towards Inclusive ASR for Rural Bhojpuri Women
Jun 11, 2025Digital inclusion remains a challenge for marginalized communities, especially rural women in low-resource language regions like Bhojpuri. Voice-based access to agricultural services, financial transactions, government schemes, and healthcare is vital for their empowerment, yet existing ASR systems for this group remain largely untested. To address this gap, we create SRUTI ,a benchmark consisting of rural Bhojpuri women speakers. Evaluation of current ASR models on SRUTI shows poor performance due to data scarcity, which is difficult to overcome due to social and cultural barriers that hinder large-scale data collection. To overcome this, we propose generating synthetic speech using just 25-30 seconds of audio per speaker from approximately 100 rural women. Augmenting existing datasets with this synthetic data achieves an improvement of 4.7 WER, providing a scalable, minimally intrusive solution to enhance ASR and promote digital inclusion in low-resource language.
Phir Hera Fairy: An English Fairytaler is a Strong Faker of Fluent Speech in Low-Resource Indian Languages
May 27, 2025What happens when an English Fairytaler is fine-tuned on Indian languages? We evaluate how the English F5-TTS model adapts to 11 Indian languages, measuring polyglot fluency, voice-cloning, style-cloning, and code-mixing. We compare: (i) training from scratch, (ii) fine-tuning English F5 on Indian data, and (iii) fine-tuning on both Indian and English data to prevent forgetting. Fine-tuning with only Indian data proves most effective and the resultant IN-F5 is a near-human polyglot; that enables speakers of one language (e.g., Odia) to fluently speak in another (e.g., Hindi). Our results show English pretraining aids low-resource TTS in reaching human parity. To aid progress in other low-resource languages, we study data-constrained setups and arrive at a compute optimal strategy. Finally, we show IN-F5 can synthesize unseen languages like Bhojpuri and Tulu using a human-in-the-loop approach for zero-resource TTS via synthetic data generation.
RomanLens: Latent Romanization and its role in Multilinguality in LLMs
Feb 11, 2025Large Language Models (LLMs) exhibit remarkable multilingual generalization despite being predominantly trained on English-centric corpora. A fundamental question arises: how do LLMs achieve such robust multilingual capabilities? For non-Latin script languages, we investigate the role of romanization - the representation of non-Latin scripts using Latin characters - as a bridge in multilingual processing. Using mechanistic interpretability techniques, we analyze next-token generation and find that intermediate layers frequently represent target words in romanized form before transitioning to native script, a phenomenon we term Latent Romanization. Further, through activation patching experiments, we demonstrate that LLMs encode semantic concepts similarly across native and romanized scripts, suggesting a shared underlying representation. Additionally in translation towards non Latin languages, our findings reveal that when the target language is in romanized form, its representations emerge earlier in the model's layers compared to native script. These insights contribute to a deeper understanding of multilingual representation in LLMs and highlight the implicit role of romanization in facilitating language transfer. Our work provides new directions for potentially improving multilingual language modeling and interpretability.
Can Vision-Language Models Evaluate Handwritten Math?
Jan 13, 2025



Recent advancements in Vision-Language Models (VLMs) have opened new possibilities in automatic grading of handwritten student responses, particularly in mathematics. However, a comprehensive study to test the ability of VLMs to evaluate and reason over handwritten content remains absent. To address this gap, we introduce FERMAT, a benchmark designed to assess the ability of VLMs to detect, localize and correct errors in handwritten mathematical content. FERMAT spans four key error dimensions - computational, conceptual, notational, and presentation - and comprises over 2,200 handwritten math solutions derived from 609 manually curated problems from grades 7-12 with intentionally introduced perturbations. Using FERMAT we benchmark nine VLMs across three tasks: error detection, localization, and correction. Our results reveal significant shortcomings in current VLMs in reasoning over handwritten text, with Gemini-1.5-Pro achieving the highest error correction rate (77%). We also observed that some models struggle with processing handwritten content, as their accuracy improves when handwritten inputs are replaced with printed text or images. These findings highlight the limitations of current VLMs and reveal new avenues for improvement. We release FERMAT and all the associated resources in the open-source to drive further research.
Pralekha: An Indic Document Alignment Evaluation Benchmark
Nov 28, 2024



Mining parallel document pairs poses a significant challenge because existing sentence embedding models often have limited context windows, preventing them from effectively capturing document-level information. Another overlooked issue is the lack of concrete evaluation benchmarks comprising high-quality parallel document pairs for assessing document-level mining approaches, particularly for Indic languages. In this study, we introduce Pralekha, a large-scale benchmark for document-level alignment evaluation. Pralekha includes over 2 million documents, with a 1:2 ratio of unaligned to aligned pairs, covering 11 Indic languages and English. Using Pralekha, we evaluate various document-level mining approaches across three dimensions: the embedding models, the granularity levels, and the alignment algorithm. To address the challenge of aligning documents using sentence and chunk-level alignments, we propose a novel scoring method, Document Alignment Coefficient (DAC). DAC demonstrates substantial improvements over baseline pooling approaches, particularly in noisy scenarios, achieving average gains of 20-30% in precision and 15-20% in F1 score. These results highlight DAC's effectiveness in parallel document mining for Indic languages.
Rethinking MUSHRA: Addressing Modern Challenges in Text-to-Speech Evaluation
Nov 19, 2024Despite rapid advancements in TTS models, a consistent and robust human evaluation framework is still lacking. For example, MOS tests fail to differentiate between similar models, and CMOS's pairwise comparisons are time-intensive. The MUSHRA test is a promising alternative for evaluating multiple TTS systems simultaneously, but in this work we show that its reliance on matching human reference speech unduly penalises the scores of modern TTS systems that can exceed human speech quality. More specifically, we conduct a comprehensive assessment of the MUSHRA test, focusing on its sensitivity to factors such as rater variability, listener fatigue, and reference bias. Based on our extensive evaluation involving 471 human listeners across Hindi and Tamil we identify two primary shortcomings: (i) reference-matching bias, where raters are unduly influenced by the human reference, and (ii) judgement ambiguity, arising from a lack of clear fine-grained guidelines. To address these issues, we propose two refined variants of the MUSHRA test. The first variant enables fairer ratings for synthesized samples that surpass human reference quality. The second variant reduces ambiguity, as indicated by the relatively lower variance across raters. By combining these approaches, we achieve both more reliable and more fine-grained assessments. We also release MANGO, a massive dataset of 47,100 human ratings, the first-of-its-kind collection for Indian languages, aiding in analyzing human preferences and developing automatic metrics for evaluating TTS systems.