 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Generalization: Re-examining Tabular Language Model Evaluation
Feb 03, 2026Tabular Language Models (TLMs) have been claimed to achieve emergent generalization for tabular prediction. We conduct a systematic re-evaluation of Tabula-8B as a representative TLM, utilizing 165 datasets from the UniPredict benchmark. Our investigation reveals three findings. First, binary and categorical classification achieve near-zero median lift over majority-class baselines and strong aggregate performance is driven entirely by quartile classification tasks. Second, top-performing datasets exhibit pervasive contamination, including complete train-test overlap and task-level leakage that evades standard deduplication. Third, instruction-tuning without tabular exposure recovers 92.2% of standard classification performance and on quartile classification, format familiarity closes 71.3% of the gap with the residual attributable to contaminated datasets. These findings suggest claimed generalization likely reflects evaluation artifacts rather than learned tabular reasoning. We conclude with recommendations for strengthening TLM evaluation.
The Reasoning Lingua Franca: A Double-Edged Sword for Multilingual AI
Oct 23, 2025Large Reasoning Models (LRMs) achieve strong performance on mathematical, scientific, and other question-answering tasks, but their multilingual reasoning abilities remain underexplored. When presented with non-English questions, LRMs often default to reasoning in English, raising concerns about interpretability and the handling of linguistic and cultural nuances. We systematically compare an LRM's reasoning in English versus the language of the question. Our evaluation spans two tasks: MGSM and GPQA Diamond. Beyond measuring answer accuracy, we also analyze cognitive attributes in the reasoning traces. We find that English reasoning traces exhibit a substantially higher presence of these cognitive behaviors, and that reasoning in English generally yields higher final-answer accuracy, with the performance gap increasing as tasks become more complex. However, this English-centric strategy is susceptible to a key failure mode - getting "Lost in Translation," where translation steps lead to errors that would have been avoided by question's language reasoning.
RomanLens: Latent Romanization and its role in Multilinguality in LLMs
Feb 11, 2025Large Language Models (LLMs) exhibit remarkable multilingual generalization despite being predominantly trained on English-centric corpora. A fundamental question arises: how do LLMs achieve such robust multilingual capabilities? For non-Latin script languages, we investigate the role of romanization - the representation of non-Latin scripts using Latin characters - as a bridge in multilingual processing. Using mechanistic interpretability techniques, we analyze next-token generation and find that intermediate layers frequently represent target words in romanized form before transitioning to native script, a phenomenon we term Latent Romanization. Further, through activation patching experiments, we demonstrate that LLMs encode semantic concepts similarly across native and romanized scripts, suggesting a shared underlying representation. Additionally in translation towards non Latin languages, our findings reveal that when the target language is in romanized form, its representations emerge earlier in the model's layers compared to native script. These insights contribute to a deeper understanding of multilingual representation in LLMs and highlight the implicit role of romanization in facilitating language transfer. Our work provides new directions for potentially improving multilingual language modeling and interpretability.
An Empirical Comparison of Vocabulary Expansion and Initialization Approaches for Language Models
Jul 08, 2024



Language Models (LMs) excel in natural language processing tasks for English but show reduced performance in most other languages. This problem is commonly tackled by continually pre-training and fine-tuning these models for said languages. A significant issue in this process is the limited vocabulary coverage in the original model's tokenizer, leading to inadequate representation of new languages and necessitating an expansion of the tokenizer. The initialization of the embeddings corresponding to new vocabulary items presents a further challenge. Current strategies require cross-lingual embeddings and lack a solid theoretical foundation as well as comparisons with strong baselines. In this paper, we first establish theoretically that initializing within the convex hull of existing embeddings is a good initialization, followed by a novel but simple approach, Constrained Word2Vec (CW2V), which does not require cross-lingual embeddings. Our study evaluates different initialization methods for expanding RoBERTa and LLaMA 2 across four languages and five tasks. The results show that CW2V performs equally well or even better than more advanced techniques. Additionally, simpler approaches like multivariate initialization perform on par with these advanced methods indicating that efficient large-scale multilingual continued pretraining can be achieved even with simpler initialization methods.
How Good is Zero-Shot MT Evaluation for Low Resource Indian Languages?
Jun 06, 2024While machine translation evaluation has been studied primarily for high-resource languages, there has been a recent interest in evaluation for low-resource languages due to the increasing availability of data and models. In this paper, we focus on a zero-shot evaluation setting focusing on low-resource Indian languages, namely Assamese, Kannada, Maithili, and Punjabi. We collect sufficient Multi-Dimensional Quality Metrics (MQM) and Direct Assessment (DA) annotations to create test sets and meta-evaluate a plethora of automatic evaluation metrics. We observe that even for learned metrics, which are known to exhibit zero-shot performance, the Kendall Tau and Pearson correlations with human annotations are only as high as 0.32 and 0.45. Synthetic data approaches show mixed results and overall do not help close the gap by much for these languages. This indicates that there is still a long way to go for low-resource evaluation.
Airavata: Introducing Hindi Instruction-tuned LLM
Jan 26, 2024We announce the initial release of "Airavata," an instruction-tuned LLM for Hindi. Airavata was created by fine-tuning OpenHathi with diverse, instruction-tuning Hindi datasets to make it better suited for assistive tasks. Along with the model, we also share the IndicInstruct dataset, which is a collection of diverse instruction-tuning datasets to enable further research for Indic LLMs. Additionally, we present evaluation benchmarks and a framework for assessing LLM performance across tasks in Hindi. Currently, Airavata supports Hindi, but we plan to expand this to all 22 scheduled Indic languages. You can access all artifacts at https://ai4bharat.github.io/airavata.
RomanSetu: Efficiently unlocking multilingual capabilities of Large Language Models models via Romanization
Jan 25, 2024This study addresses the challenge of extending Large Language Models (LLMs) to non-English languages, specifically those using non-Latin scripts. We propose an innovative approach that utilizes the romanized form of text as an interface for LLMs, hypothesizing that its frequent informal use and shared tokens with English enhance cross-lingual alignment. Focusing on Hindi, we demonstrate through Hindi-to-English translation and sentiment analysis tasks that romanized text not only significantly improves inference efficiency due to its lower fertility compared to native text but also achieves competitive performance with limited pre-training. Additionally, our novel multi-script prompting approach, which combines romanized and native texts, shows promise in further enhancing task performance. These findings suggest the potential of romanization in bridging the language gap for LLM applications, with future work aimed at expanding this approach to more languages and tasks.
VerityMath: Advancing Mathematical Reasoning by Self-Verification Through Unit Consistency
Nov 13, 2023



Large Language Models (LLMs) combined with program-based solving techniques are increasingly demonstrating proficiency in mathematical reasoning. However, such progress is mostly demonstrated in closed-source models such as OpenAI-GPT4 and Claude. In this paper, we seek to study the performance of strong open-source LLMs. Specifically, we analyze the outputs of Code Llama (7B) when applied to math word problems. We identify a category of problems that pose a challenge for the model, particularly those involving quantities that span multiple types or units. To address this issue, we propose a systematic approach by defining units for each quantity and ensuring the consistency of these units during mathematical operations. We developed Unit Consistency Programs (UCPs), an annotated dataset of math word problems, each paired with programs that contain unit specifications and unit verification routines. Finally, we finetune the Code Llama (7B) model with UCPs to produce VerityMath and present our preliminary findings.
IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages
May 25, 2023India has a rich linguistic landscape with languages from 4 major language families spoken by over a billion people. 22 of these languages are listed in the Constitution of India (referred to as scheduled languages) are the focus of this work. Given the linguistic diversity, high-quality and accessible Machine Translation (MT) systems are essential in a country like India. Prior to this work, there was (i) no parallel training data spanning all the 22 languages, (ii) no robust benchmarks covering all these languages and containing content relevant to India, and (iii) no existing translation models which support all the 22 scheduled languages of India. In this work, we aim to address this gap by focusing on the missing pieces required for enabling wide, easy, and open access to good machine translation systems for all 22 scheduled Indian languages. We identify four key areas of improvement: curating and creating larger training datasets, creating diverse and high-quality benchmarks, training multilingual models, and releasing models with open access. Our first contribution is the release of the Bharat Parallel Corpus Collection (BPCC), the largest publicly available parallel corpora for Indic languages. BPCC contains a total of 230M bitext pairs, of which a total of 126M were newly added, including 644K manually translated sentence pairs created as part of this work. Our second contribution is the release of the first n-way parallel benchmark covering all 22 Indian languages, featuring diverse domains, Indian-origin content, and source-original test sets. Next, we present IndicTrans2, the first model to support all 22 languages, surpassing existing models on multiple existing and new benchmarks created as a part of this work. Lastly, to promote accessibility and collaboration, we release our models and associated data with permissive licenses at https://github.com/ai4bharat/IndicTrans2.
In-context Example Selection for Machine Translation Using Multiple Features
May 23, 2023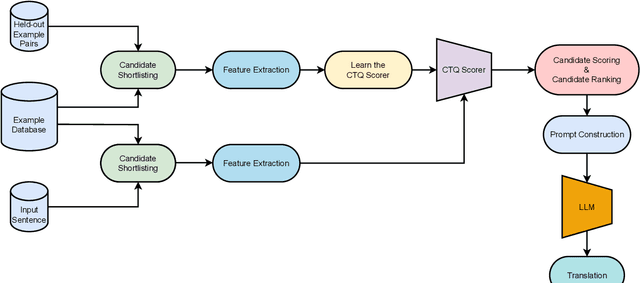
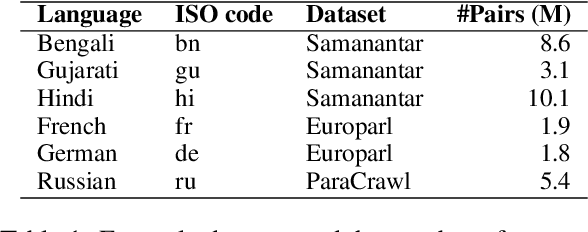
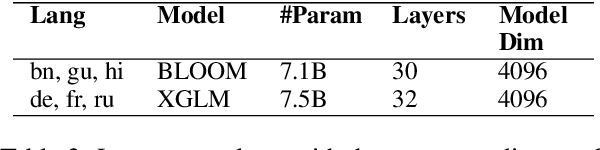
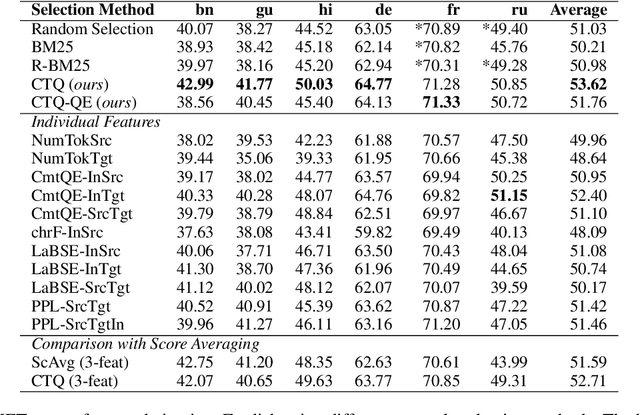
Large language models have demonstrated the capability to perform well on many NLP tasks when the input is prompted with a few examples (in-context learning) including machine translation, which is the focus of this work. The quality of translation depends on various features of the selected examples, such as their quality and relevance. However, previous work has predominantly focused on individual features for example selection. We propose a general framework for combining different features influencing example selection. We learn a regression function that selects examples based on multiple features in order to maximize the translation quality. On multiple language pairs and language models, we show that our example selection method significantly outperforms random selection as well as strong single-factor baselines reported in the literature. Using our example selection method, we see an improvement of over 2.5 COMET points on average with respect to a strong BM25 retrieval-based baseline.