 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRASMALAI: Resources for Adaptive Speech Modeling in Indian Languages with Accents and Intonations
May 24, 2025We introduce RASMALAI, a large-scale speech dataset with rich text descriptions, designed to advance controllable and expressive text-to-speech (TTS) synthesis for 23 Indian languages and English. It comprises 13,000 hours of speech and 24 million text-description annotations with fine-grained attributes like speaker identity, accent, emotion, style, and background conditions. Using RASMALAI, we develop IndicParlerTTS, the first open-source, text-description-guided TTS for Indian languages. Systematic evaluation demonstrates its ability to generate high-quality speech for named speakers, reliably follow text descriptions and accurately synthesize specified attributes. Additionally, it effectively transfers expressive characteristics both within and across languages. IndicParlerTTS consistently achieves strong performance across these evaluations, setting a new standard for controllable multilingual expressive speech synthesis in Indian languages.
BhasaAnuvaad: A Speech Translation Dataset for 14 Indian Languages
Nov 07, 2024



Automatic Speech Translation (AST) datasets for Indian languages remain critically scarce, with public resources covering fewer than 10 of the 22 official languages. This scarcity has resulted in AST systems for Indian languages lagging far behind those available for high-resource languages like English. In this paper, we first evaluate the performance of widely-used AST systems on Indian languages, identifying notable performance gaps and challenges. Our findings show that while these systems perform adequately on read speech, they struggle significantly with spontaneous speech, including disfluencies like pauses and hesitations. Additionally, there is a striking absence of systems capable of accurately translating colloquial and informal language, a key aspect of everyday communication. To this end, we introduce BhasaAnuvaad, the largest publicly available dataset for AST involving 14 scheduled Indian languages spanning over 44,400 hours and 17M text segments. BhasaAnuvaad contains data for English speech to Indic text, as well as Indic speech to English text. This dataset comprises three key categories: (1) Curated datasets from existing resources, (2) Large-scale web mining, and (3) Synthetic data generation. By offering this diverse and expansive dataset, we aim to bridge the resource gap and promote advancements in AST for low-resource Indian languages, especially in handling spontaneous and informal speech patterns.
How Good is Zero-Shot MT Evaluation for Low Resource Indian Languages?
Jun 06, 2024While machine translation evaluation has been studied primarily for high-resource languages, there has been a recent interest in evaluation for low-resource languages due to the increasing availability of data and models. In this paper, we focus on a zero-shot evaluation setting focusing on low-resource Indian languages, namely Assamese, Kannada, Maithili, and Punjabi. We collect sufficient Multi-Dimensional Quality Metrics (MQM) and Direct Assessment (DA) annotations to create test sets and meta-evaluate a plethora of automatic evaluation metrics. We observe that even for learned metrics, which are known to exhibit zero-shot performance, the Kendall Tau and Pearson correlations with human annotations are only as high as 0.32 and 0.45. Synthetic data approaches show mixed results and overall do not help close the gap by much for these languages. This indicates that there is still a long way to go for low-resource evaluation.
IndicVoices: Towards building an Inclusive Multilingual Speech Dataset for Indian Languages
Mar 04, 2024We present INDICVOICES, a dataset of natural and spontaneous speech containing a total of 7348 hours of read (9%), extempore (74%) and conversational (17%) audio from 16237 speakers covering 145 Indian districts and 22 languages. Of these 7348 hours, 1639 hours have already been transcribed, with a median of 73 hours per language. Through this paper, we share our journey of capturing the cultural, linguistic and demographic diversity of India to create a one-of-its-kind inclusive and representative dataset. More specifically, we share an open-source blueprint for data collection at scale comprising of standardised protocols, centralised tools, a repository of engaging questions, prompts and conversation scenarios spanning multiple domains and topics of interest, quality control mechanisms, comprehensive transcription guidelines and transcription tools. We hope that this open source blueprint will serve as a comprehensive starter kit for data collection efforts in other multilingual regions of the world. Using INDICVOICES, we build IndicASR, the first ASR model to support all the 22 languages listed in the 8th schedule of the Constitution of India. All the data, tools, guidelines, models and other materials developed as a part of this work will be made publicly available
Input-specific Attention Subnetworks for Adversarial Detection
Mar 23, 2022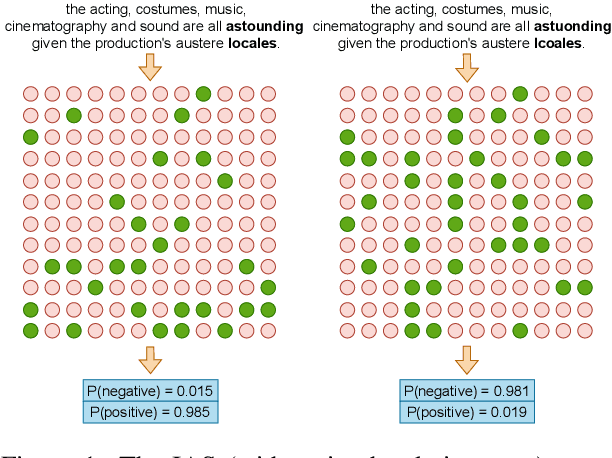
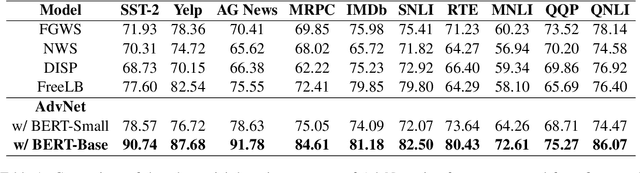
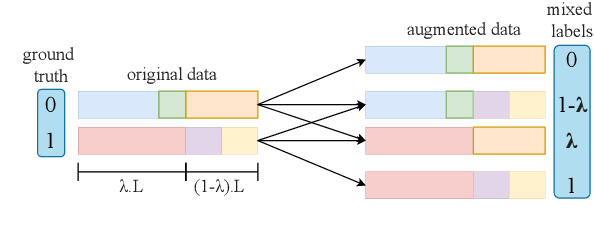
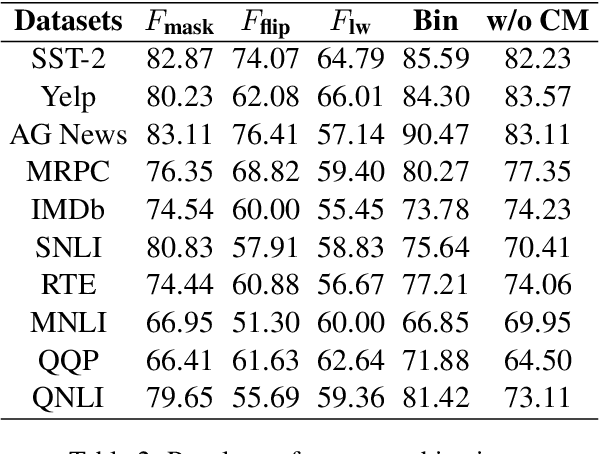
Self-attention heads are characteristic of Transformer models and have been well studied for interpretability and pruning. In this work, we demonstrate an altogether different utility of attention heads, namely for adversarial detection. Specifically, we propose a method to construct input-specific attention subnetworks (IAS) from which we extract three features to discriminate between authentic and adversarial inputs. The resultant detector significantly improves (by over 7.5%) the state-of-the-art adversarial detection accuracy for the BERT encoder on 10 NLU datasets with 11 different adversarial attack types. We also demonstrate that our method (a) is more accurate for larger models which are likely to have more spurious correlations and thus vulnerable to adversarial attack, and (b) performs well even with modest training sets of adversarial examples.