 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaPTwin: Low-Cost Adaptive Compression of Product Twins in Transformers
Jun 13, 2024While large transformer-based models have exhibited remarkable performance in speaker-independent speech recognition, their large size and computational requirements make them expensive or impractical to use in resource-constrained settings. In this work, we propose a low-rank adaptive compression technique called AdaPTwin that jointly compresses product-dependent pairs of weight matrices in the transformer attention layer. Our approach can prioritize the compressed model's performance on a specific speaker while maintaining generalizability to new speakers and acoustic conditions. Notably, our technique requires only 8 hours of speech data for fine-tuning, which can be accomplished in under 20 minutes, making it highly cost-effective compared to other compression methods. We demonstrate the efficacy of our approach by compressing the Whisper and Distil-Whisper models by up to 45% while incurring less than a 2% increase in word error rate.
HomE: Homography-Equivariant Video Representation Learning
Jun 02, 2023Recent advances in self-supervised representation learning have enabled more efficient and robust model performance without relying on extensive labeled data. However, most works are still focused on images, with few working on videos and even fewer on multi-view videos, where more powerful inductive biases can be leveraged for self-supervision. In this work, we propose a novel method for representation learning of multi-view videos, where we explicitly model the representation space to maintain Homography Equivariance (HomE). Our method learns an implicit mapping between different views, culminating in a representation space that maintains the homography relationship between neighboring views. We evaluate our HomE representation via action recognition and pedestrian intent prediction as downstream tasks. On action classification, our method obtains 96.4% 3-fold accuracy on the UCF101 dataset, better than most state-of-the-art self-supervised learning methods. Similarly, on the STIP dataset, we outperform the state-of-the-art by 6% for pedestrian intent prediction one second into the future while also obtaining an accuracy of 91.2% for pedestrian action (cross vs. not-cross) classification. Code is available at https://github.com/anirudhs123/HomE.
Joint Transformer/RNN Architecture for Gesture Typing in Indic Languages
Mar 26, 2022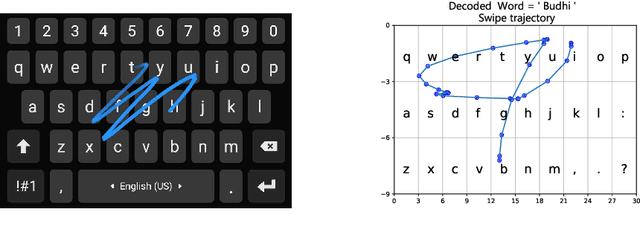
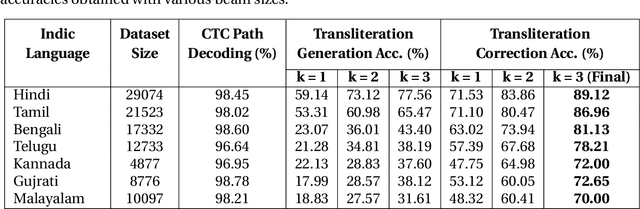
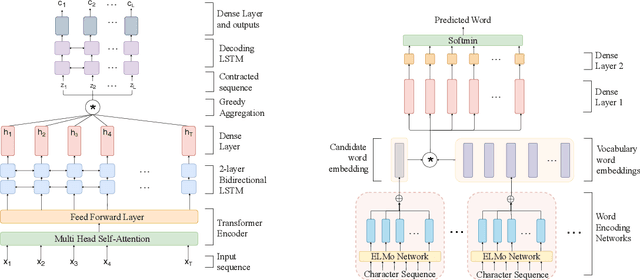
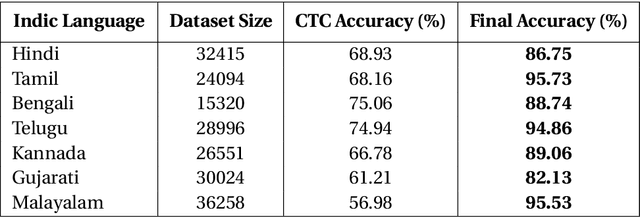
Gesture typing is a method of typing words on a touch-based keyboard by creating a continuous trace passing through the relevant keys. This work is aimed at developing a keyboard that supports gesture typing in Indic languages. We begin by noting that when dealing with Indic languages, one needs to cater to two different sets of users: (i) users who prefer to type in the native Indic script (Devanagari, Bengali, etc.) and (ii) users who prefer to type in the English script but want the output transliterated into the native script. In both cases, we need a model that takes a trace as input and maps it to the intended word. To enable the development of these models, we create and release two datasets. First, we create a dataset containing keyboard traces for 193,658 words from 7 Indic languages. Second, we curate 104,412 English-Indic transliteration pairs from Wikidata across these languages. Using these datasets we build a model that performs path decoding, transliteration, and transliteration correction. Unlike prior approaches, our proposed model does not make co-character independence assumptions during decoding. The overall accuracy of our model across the 7 languages varies from 70-95%.
Input-specific Attention Subnetworks for Adversarial Detection
Mar 23, 2022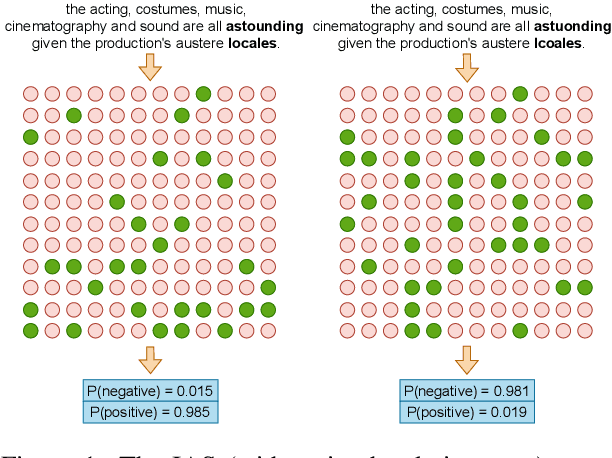
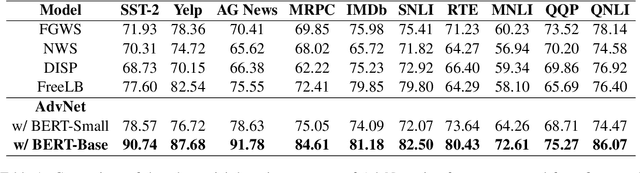
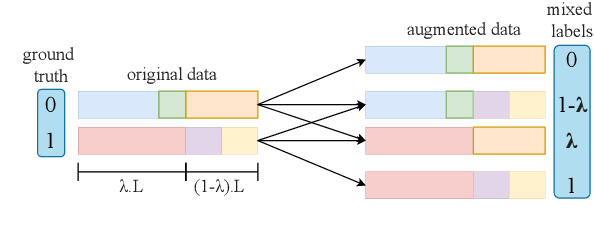
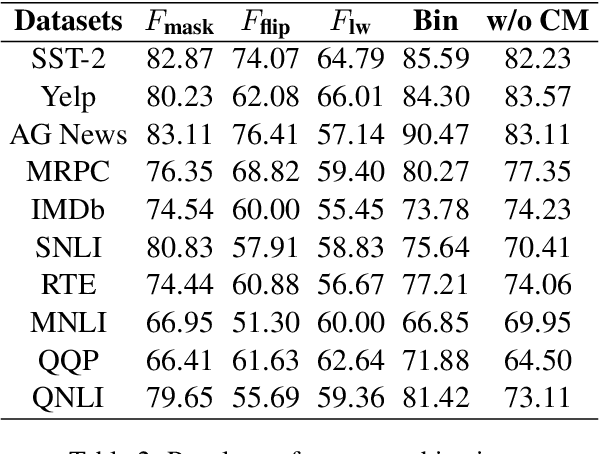
Self-attention heads are characteristic of Transformer models and have been well studied for interpretability and pruning. In this work, we demonstrate an altogether different utility of attention heads, namely for adversarial detection. Specifically, we propose a method to construct input-specific attention subnetworks (IAS) from which we extract three features to discriminate between authentic and adversarial inputs. The resultant detector significantly improves (by over 7.5%) the state-of-the-art adversarial detection accuracy for the BERT encoder on 10 NLU datasets with 11 different adversarial attack types. We also demonstrate that our method (a) is more accurate for larger models which are likely to have more spurious correlations and thus vulnerable to adversarial attack, and (b) performs well even with modest training sets of adversarial examples.