 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput-specific Attention Subnetworks for Adversarial Detection
Paper and Code
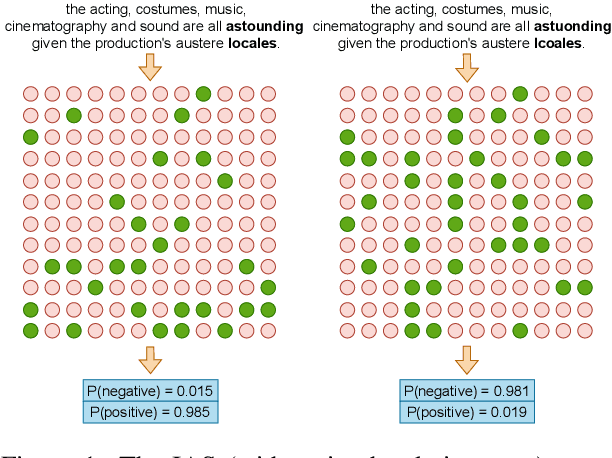
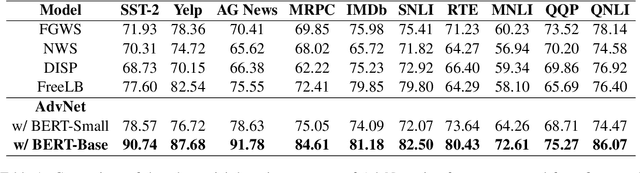
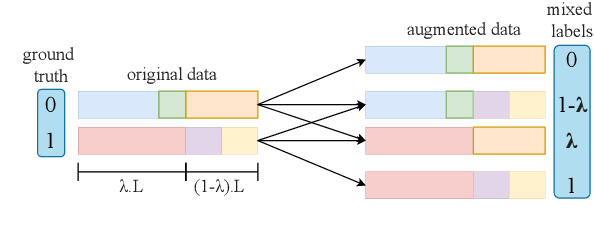
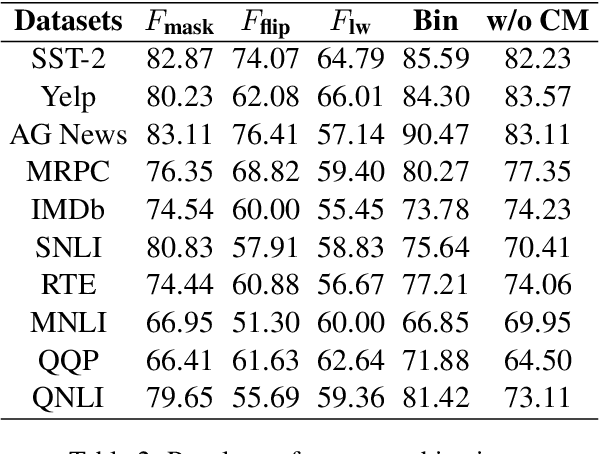
Self-attention heads are characteristic of Transformer models and have been well studied for interpretability and pruning. In this work, we demonstrate an altogether different utility of attention heads, namely for adversarial detection. Specifically, we propose a method to construct input-specific attention subnetworks (IAS) from which we extract three features to discriminate between authentic and adversarial inputs. The resultant detector significantly improves (by over 7.5%) the state-of-the-art adversarial detection accuracy for the BERT encoder on 10 NLU datasets with 11 different adversarial attack types. We also demonstrate that our method (a) is more accurate for larger models which are likely to have more spurious correlations and thus vulnerable to adversarial attack, and (b) performs well even with modest training sets of adversarial examples.