 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Engine Optimization at Scale: Measuring Brand Visibility Across AI Search Engines
Jun 18, 2026People increasingly get answers straight from AI search engines like ChatGPT, Claude, Perplexity, and Gemini rather than scrolling search results. Brands that once focused on search engine optimization (SEO) must now optimize for how these engines represent, cite, and recommend them -- a shift variously called Generative Engine Optimization (GEO), Answer Engine Optimization (AEO), and AI Search Visibility. We treat AEO and AI Visibility as part of GEO, and study how to measure brand visibility across AI engines: what they value when they cite a brand, which sources they rely on, and what content large language models surface. The hard case is everyone outside the already-authoritative top brands -- SMEs, D2C brands, creators, and early-stage startups. We analyze 100K+ prompt responses across 100+ brands tracked on Ranqo between March and May 2026. First visibility runs form a clear three-tier brand-stature ladder: global household names (e.g., Stripe, Nike) appear in 73% of relevant AI answers on their first run; established mid-market and regional brands (e.g., Olipop, Klaviyo) in 44%; niche and small brands in just 11% -- about 30 percentage points per step. When engines cite sources, about 78% go to corporate websites; among non-corporate sources YouTube leads, ahead of Reddit, editorial media, and Wikipedia. The highest-leverage page is the ranked "best-of" listicle, the most-cited content format at about 21% of all citations. Sentiment is the unstable signal: whether a brand is framed positively or negatively flips about 6.7 times more often than whether it is mentioned at all. These findings provide a first large-scale baseline for measuring GEO: AI brand visibility can be measured, differs by platform, and varies strongly by brand maturity. We close by proposing seven v1.1 protocols to test whether specific recommendations can causally improve AI visibility.
Empowering Low-Resource Language ASR via Large-Scale Pseudo Labeling
Aug 26, 2024



In this study, we tackle the challenge of limited labeled data for low-resource languages in ASR, focusing on Hindi. Specifically, we explore pseudo-labeling, by proposing a generic framework combining multiple ideas from existing works. Our framework integrates multiple base models for transcription and evaluators for assessing audio-transcript pairs, resulting in robust pseudo-labeling for low resource languages. We validate our approach with a new benchmark, IndicYT, comprising diverse YouTube audio files from multiple content categories. Our findings show that augmenting pseudo labeled data from YouTube with existing training data leads to significant performance improvements on IndicYT, without affecting performance on out-of-domain benchmarks, demonstrating the efficacy of pseudo-labeled data in enhancing ASR capabilities for low-resource languages. The benchmark, code and models developed as a part of this work will be made publicly available.
RoundTable: Leveraging Dynamic Schema and Contextual Autocomplete for Enhanced Query Precision in Tabular Question Answering
Aug 23, 2024With advancements in Large Language Models (LLMs), a major use case that has emerged is querying databases in plain English, translating user questions into executable database queries, which has improved significantly. However, real-world datasets often feature a vast array of attributes and complex values, complicating the LLMs task of accurately identifying relevant columns or values from natural language queries. Traditional methods cannot fully relay the datasets size and complexity to the LLM. To address these challenges, we propose a novel framework that leverages Full-Text Search (FTS) on the input table. This approach not only enables precise detection of specific values and columns but also narrows the search space for language models, thereby enhancing query accuracy. Additionally, it supports a custom auto-complete feature that suggests queries based on the data in the table. This integration significantly refines the interaction between the user and complex datasets, offering a sophisticated solution to the limitations faced by current table querying capabilities. This work is accompanied by an application for both Mac and Windows platforms, which readers can try out themselves on their own data.
IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages
Mar 11, 2024Despite the considerable advancements in English LLMs, the progress in building comparable models for other languages has been hindered due to the scarcity of tailored resources. Our work aims to bridge this divide by introducing an expansive suite of resources specifically designed for the development of Indic LLMs, covering 22 languages, containing a total of 251B tokens and 74.8M instruction-response pairs. Recognizing the importance of both data quality and quantity, our approach combines highly curated manually verified data, unverified yet valuable data, and synthetic data. We build a clean, open-source pipeline for curating pre-training data from diverse sources, including websites, PDFs, and videos, incorporating best practices for crawling, cleaning, flagging, and deduplication. For instruction-fine tuning, we amalgamate existing Indic datasets, translate/transliterate English datasets into Indian languages, and utilize LLaMa2 and Mixtral models to create conversations grounded in articles from Indian Wikipedia and Wikihow. Additionally, we address toxicity alignment by generating toxic prompts for multiple scenarios and then generate non-toxic responses by feeding these toxic prompts to an aligned LLaMa2 model. We hope that the datasets, tools, and resources released as a part of this work will not only propel the research and development of Indic LLMs but also establish an open-source blueprint for extending such efforts to other languages. The data and other artifacts created as part of this work are released with permissive licenses.
IndicVoices: Towards building an Inclusive Multilingual Speech Dataset for Indian Languages
Mar 04, 2024We present INDICVOICES, a dataset of natural and spontaneous speech containing a total of 7348 hours of read (9%), extempore (74%) and conversational (17%) audio from 16237 speakers covering 145 Indian districts and 22 languages. Of these 7348 hours, 1639 hours have already been transcribed, with a median of 73 hours per language. Through this paper, we share our journey of capturing the cultural, linguistic and demographic diversity of India to create a one-of-its-kind inclusive and representative dataset. More specifically, we share an open-source blueprint for data collection at scale comprising of standardised protocols, centralised tools, a repository of engaging questions, prompts and conversation scenarios spanning multiple domains and topics of interest, quality control mechanisms, comprehensive transcription guidelines and transcription tools. We hope that this open source blueprint will serve as a comprehensive starter kit for data collection efforts in other multilingual regions of the world. Using INDICVOICES, we build IndicASR, the first ASR model to support all the 22 languages listed in the 8th schedule of the Constitution of India. All the data, tools, guidelines, models and other materials developed as a part of this work will be made publicly available
DSFormer: Effective Compression of Text-Transformers by Dense-Sparse Weight Factorization
Dec 20, 2023With the tremendous success of large transformer models in natural language understanding, down-sizing them for cost-effective deployments has become critical. Recent studies have explored the low-rank weight factorization techniques which are efficient to train, and apply out-of-the-box to any transformer architecture. Unfortunately, the low-rank assumption tends to be over-restrictive and hinders the expressiveness of the compressed model. This paper proposes, DSFormer, a simple alternative factorization scheme which expresses a target weight matrix as the product of a small dense and a semi-structured sparse matrix. The resulting approximation is more faithful to the weight distribution in transformers and therefore achieves a stronger efficiency-accuracy trade-off. Another concern with existing factorizers is their dependence on a task-unaware initialization step which degrades the accuracy of the resulting model. DSFormer addresses this issue through a novel Straight-Through Factorizer (STF) algorithm that jointly learns all the weight factorizations to directly maximize the final task accuracy. Extensive experiments on multiple natural language understanding benchmarks demonstrate that DSFormer obtains up to 40% better compression than the state-of-the-art low-rank factorizers, leading semi-structured sparsity baselines and popular knowledge distillation approaches. Our approach is also orthogonal to mainstream compressors and offers up to 50% additional compression when added to popular distilled, layer-shared and quantized transformers. We empirically evaluate the benefits of STF over conventional optimization practices.
Svarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023
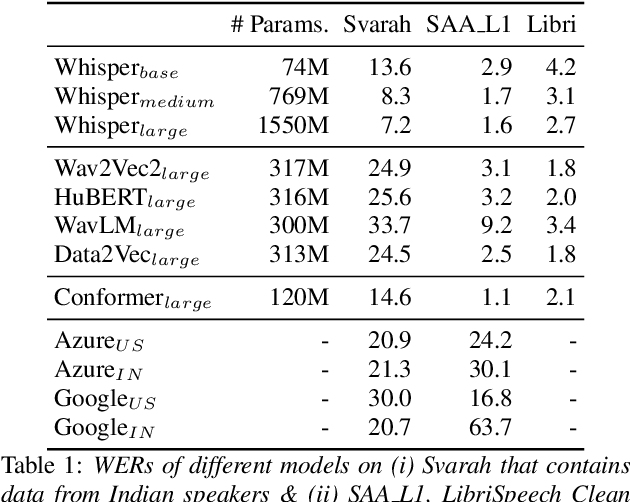
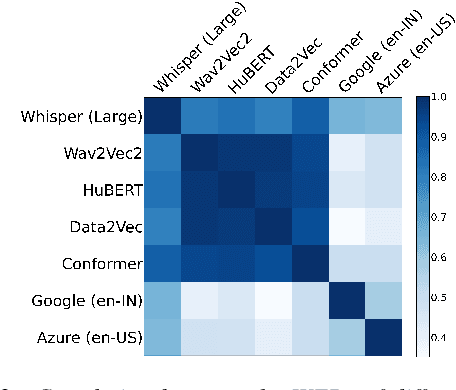
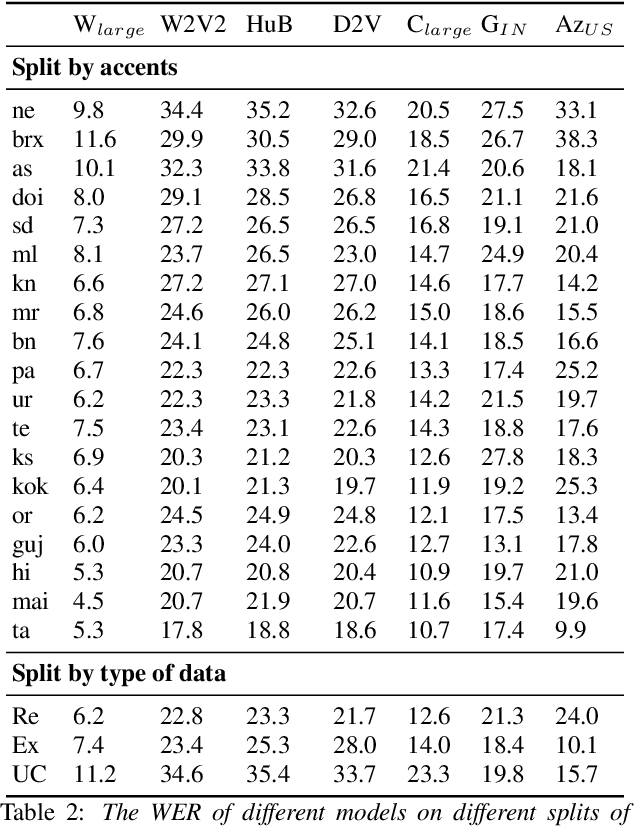
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.
IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages
May 25, 2023India has a rich linguistic landscape with languages from 4 major language families spoken by over a billion people. 22 of these languages are listed in the Constitution of India (referred to as scheduled languages) are the focus of this work. Given the linguistic diversity, high-quality and accessible Machine Translation (MT) systems are essential in a country like India. Prior to this work, there was (i) no parallel training data spanning all the 22 languages, (ii) no robust benchmarks covering all these languages and containing content relevant to India, and (iii) no existing translation models which support all the 22 scheduled languages of India. In this work, we aim to address this gap by focusing on the missing pieces required for enabling wide, easy, and open access to good machine translation systems for all 22 scheduled Indian languages. We identify four key areas of improvement: curating and creating larger training datasets, creating diverse and high-quality benchmarks, training multilingual models, and releasing models with open access. Our first contribution is the release of the Bharat Parallel Corpus Collection (BPCC), the largest publicly available parallel corpora for Indic languages. BPCC contains a total of 230M bitext pairs, of which a total of 126M were newly added, including 644K manually translated sentence pairs created as part of this work. Our second contribution is the release of the first n-way parallel benchmark covering all 22 Indian languages, featuring diverse domains, Indian-origin content, and source-original test sets. Next, we present IndicTrans2, the first model to support all 22 languages, surpassing existing models on multiple existing and new benchmarks created as a part of this work. Lastly, to promote accessibility and collaboration, we release our models and associated data with permissive licenses at https://github.com/ai4bharat/IndicTrans2.
Vistaar: Diverse Benchmarks and Training Sets for Indian Language ASR
May 24, 2023



Improving ASR systems is necessary to make new LLM-based use-cases accessible to people across the globe. In this paper, we focus on Indian languages, and make the case that diverse benchmarks are required to evaluate and improve ASR systems for Indian languages. To address this, we collate Vistaar as a set of 59 benchmarks across various language and domain combinations, on which we evaluate 3 publicly available ASR systems and 2 commercial systems. We also train IndicWhisper models by fine-tuning the Whisper models on publicly available training datasets across 12 Indian languages totalling to 10.7K hours. We show that IndicWhisper significantly improves on considered ASR systems on the Vistaar benchmark. Indeed, IndicWhisper has the lowest WER in 39 out of the 59 benchmarks, with an average reduction of 4.1 WER. We open-source all datasets, code and models.
Large Language Models Humanize Technology
May 09, 2023



Large Language Models (LLMs) have made rapid progress in recent months and weeks, garnering significant public attention. This has sparked concerns about aligning these models with human values, their impact on labor markets, and the potential need for regulation in further research and development. However, the discourse often lacks a focus on the imperative to widely diffuse the societal benefits of LLMs. To qualify this societal benefit, we assert that LLMs exhibit emergent abilities to humanize technology more effectively than previous technologies, and for people across language, occupation, and accessibility divides. We argue that they do so by addressing three mechanizing bottlenecks in today's computing technologies: creating diverse and accessible content, learning complex digital tools, and personalizing machine learning algorithms. We adopt a case-based approach and illustrate each bottleneck with two examples where current technology imposes bottlenecks that LLMs demonstrate the ability to address. Given this opportunity to humanize technology widely, we advocate for more widespread understanding of LLMs, tools and methods to simplify use of LLMs, and cross-cutting institutional capacity.