 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages
Mar 11, 2024Despite the considerable advancements in English LLMs, the progress in building comparable models for other languages has been hindered due to the scarcity of tailored resources. Our work aims to bridge this divide by introducing an expansive suite of resources specifically designed for the development of Indic LLMs, covering 22 languages, containing a total of 251B tokens and 74.8M instruction-response pairs. Recognizing the importance of both data quality and quantity, our approach combines highly curated manually verified data, unverified yet valuable data, and synthetic data. We build a clean, open-source pipeline for curating pre-training data from diverse sources, including websites, PDFs, and videos, incorporating best practices for crawling, cleaning, flagging, and deduplication. For instruction-fine tuning, we amalgamate existing Indic datasets, translate/transliterate English datasets into Indian languages, and utilize LLaMa2 and Mixtral models to create conversations grounded in articles from Indian Wikipedia and Wikihow. Additionally, we address toxicity alignment by generating toxic prompts for multiple scenarios and then generate non-toxic responses by feeding these toxic prompts to an aligned LLaMa2 model. We hope that the datasets, tools, and resources released as a part of this work will not only propel the research and development of Indic LLMs but also establish an open-source blueprint for extending such efforts to other languages. The data and other artifacts created as part of this work are released with permissive licenses.
Smoothed Gaussian Mixture Models for Video Classification and Recommendation
Dec 17, 2020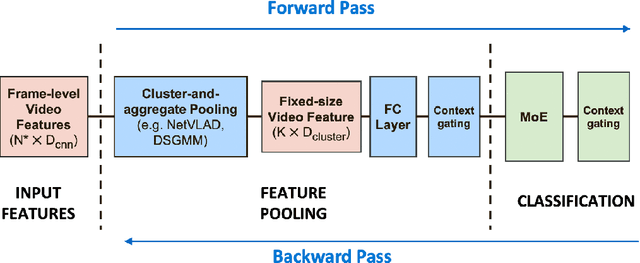
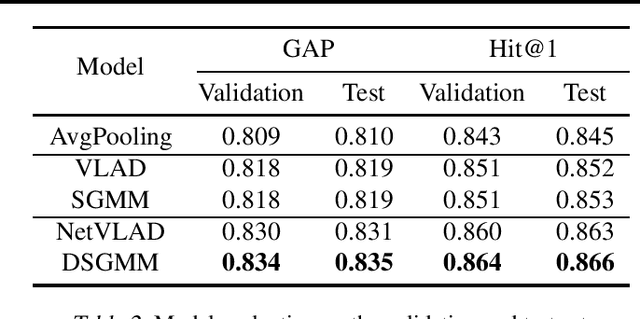
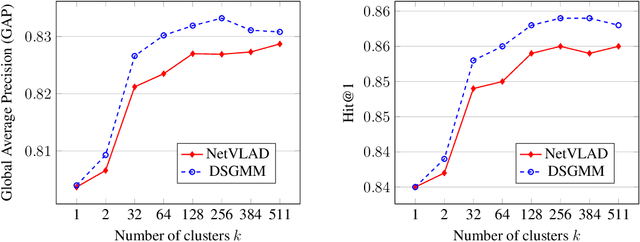
Cluster-and-aggregate techniques such as Vector of Locally Aggregated Descriptors (VLAD), and their end-to-end discriminatively trained equivalents like NetVLAD have recently been popular for video classification and action recognition tasks. These techniques operate by assigning video frames to clusters and then representing the video by aggregating residuals of frames with respect to the mean of each cluster. Since some clusters may see very little video-specific data, these features can be noisy. In this paper, we propose a new cluster-and-aggregate method which we call smoothed Gaussian mixture model (SGMM), and its end-to-end discriminatively trained equivalent, which we call deep smoothed Gaussian mixture model (DSGMM). SGMM represents each video by the parameters of a Gaussian mixture model (GMM) trained for that video. Low-count clusters are addressed by smoothing the video-specific estimates with a universal background model (UBM) trained on a large number of videos. The primary benefit of SGMM over VLAD is smoothing which makes it less sensitive to small number of training samples. We show, through extensive experiments on the YouTube-8M classification task, that SGMM/DSGMM is consistently better than VLAD/NetVLAD by a small but statistically significant margin. We also show results using a dataset created at LinkedIn to predict if a member will watch an uploaded video.
DeText: A Deep Text Ranking Framework with BERT
Aug 06, 2020

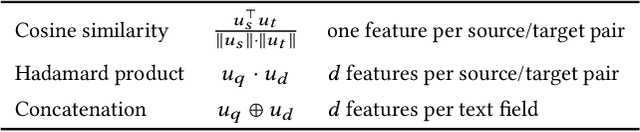
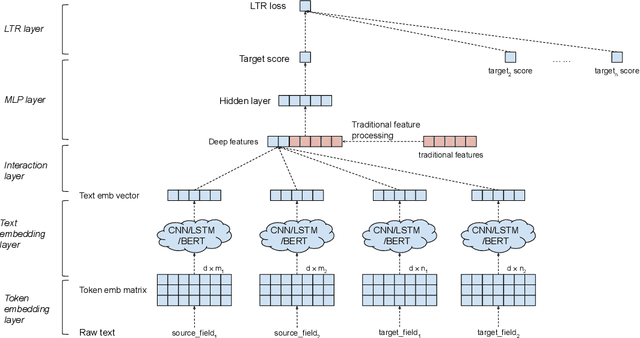
Ranking is the most important component in a search system. Mostsearch systems deal with large amounts of natural language data,hence an effective ranking system requires a deep understandingof text semantics. Recently, deep learning based natural languageprocessing (deep NLP) models have generated promising results onranking systems. BERT is one of the most successful models thatlearn contextual embedding, which has been applied to capturecomplex query-document relations for search ranking. However,this is generally done by exhaustively interacting each query wordwith each document word, which is inefficient for online servingin search product systems. In this paper, we investigate how tobuild an efficient BERT-based ranking model for industry use cases.The solution is further extended to a general ranking framework,DeText, that is open sourced and can be applied to various rankingproductions. Offline and online experiments of DeText on threereal-world search systems present significant improvement overstate-of-the-art approaches.
Speech recognition for medical conversations
Jun 20, 2018
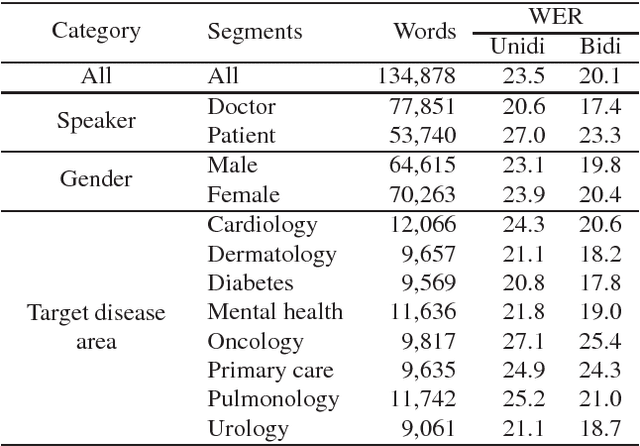
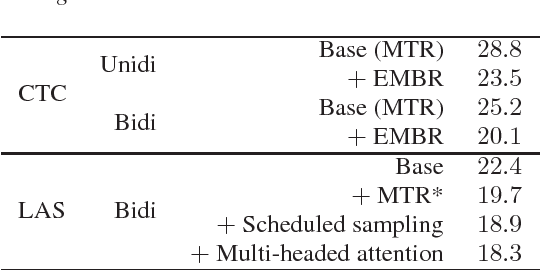
In this work we explored building automatic speech recognition models for transcribing doctor patient conversation. We collected a large scale dataset of clinical conversations ($14,000$ hr), designed the task to represent the real word scenario, and explored several alignment approaches to iteratively improve data quality. We explored both CTC and LAS systems for building speech recognition models. The LAS was more resilient to noisy data and CTC required more data clean up. A detailed analysis is provided for understanding the performance for clinical tasks. Our analysis showed the speech recognition models performed well on important medical utterances, while errors occurred in causal conversations. Overall we believe the resulting models can provide reasonable quality in practice.