 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Calibration and Robust LiDAR-Inertial Odometry for Spinning Actuated LiDAR Systems
Jan 24, 2026Accurate calibration and robust localization are fundamental for downstream tasks in spinning actuated LiDAR applications. Existing methods, however, require parameterizing extrinsic parameters based on different mounting configurations, limiting their generalizability. Additionally, spinning actuated LiDAR inevitably scans featureless regions, which complicates the balance between scanning coverage and localization robustness. To address these challenges, this letter presents a targetless LiDAR-motor calibration (LM-Calibr) on the basis of the Denavit-Hartenberg convention and an environmental adaptive LiDAR-inertial odometry (EVA-LIO). LM-Calibr supports calibration of LiDAR-motor systems with various mounting configurations. Extensive experiments demonstrate its accuracy and convergence across different scenarios, mounting angles, and initial values. Additionally, EVA-LIO adaptively selects downsample rates and map resolutions according to spatial scale. This adaptivity enables the actuator to operate at maximum speed, thereby enhancing scanning completeness while ensuring robust localization, even when LiDAR briefly scans featureless areas. The source code and hardware design are available on GitHub: \textcolor{blue}{\href{https://github.com/zijiechenrobotics/lm_calibr}{github.com/zijiechenrobotics/lm\_calibr}}. The video is available at \textcolor{blue}{\href{https://youtu.be/cZyyrkmeoSk}{youtu.be/cZyyrkmeoSk}}
Mitigating Degree Bias Adaptively with Hard-to-Learn Nodes in Graph Contrastive Learning
Jun 05, 2025Graph Neural Networks (GNNs) often suffer from degree bias in node classification tasks, where prediction performance varies across nodes with different degrees. Several approaches, which adopt Graph Contrastive Learning (GCL), have been proposed to mitigate this bias. However, the limited number of positive pairs and the equal weighting of all positives and negatives in GCL still lead to low-degree nodes acquiring insufficient and noisy information. This paper proposes the Hardness Adaptive Reweighted (HAR) contrastive loss to mitigate degree bias. It adds more positive pairs by leveraging node labels and adaptively weights positive and negative pairs based on their learning hardness. In addition, we develop an experimental framework named SHARP to extend HAR to a broader range of scenarios. Both our theoretical analysis and experiments validate the effectiveness of SHARP. The experimental results across four datasets show that SHARP achieves better performance against baselines at both global and degree levels.
Adaptify: A Refined Adaptation Scheme for Frame Classification in Atrophic Gastritis Videos
Aug 17, 2024Atrophic gastritis is a significant risk factor for developing gastric cancer. The incorporation of machine learning algorithms can efficiently elevate the possibility of accurately detecting atrophic gastritis. Nevertheless, when the trained model is applied in real-life circumstances, its output is often not consistently reliable. In this paper, we propose Adaptify, an adaptation scheme in which the model assimilates knowledge from its own classification decisions. Our proposed approach includes keeping the primary model constant, while simultaneously running and updating the auxiliary model. By integrating the knowledge gleaned by the auxiliary model into the primary model and merging their outputs, we have observed a notable improvement in output stability and consistency compared to relying solely on either the main model or the auxiliary model.
A manometric feature descriptor with linear-SVM to distinguish esophageal contraction vigor
Nov 27, 2023n clinical, if a patient presents with nonmechanical obstructive dysphagia, esophageal chest pain, and gastro esophageal reflux symptoms, the physician will usually assess the esophageal dynamic function. High-resolution manometry (HRM) is a clinically commonly used technique for detection of esophageal dynamic function comprehensively and objectively. However, after the results of HRM are obtained, doctors still need to evaluate by a variety of parameters. This work is burdensome, and the process is complex. We conducted image processing of HRM to predict the esophageal contraction vigor for assisting the evaluation of esophageal dynamic function. Firstly, we used Feature-Extraction and Histogram of Gradients (FE-HOG) to analyses feature of proposal of swallow (PoS) to further extract higher-order features. Then we determine the classification of esophageal contraction vigor normal, weak and failed by using linear-SVM according to these features. Our data set includes 3000 training sets, 500 validation sets and 411 test sets. After verification our accuracy reaches 86.83%, which is higher than other common machine learning methods.
Deep Natural Language Processing for LinkedIn Search
Aug 16, 2021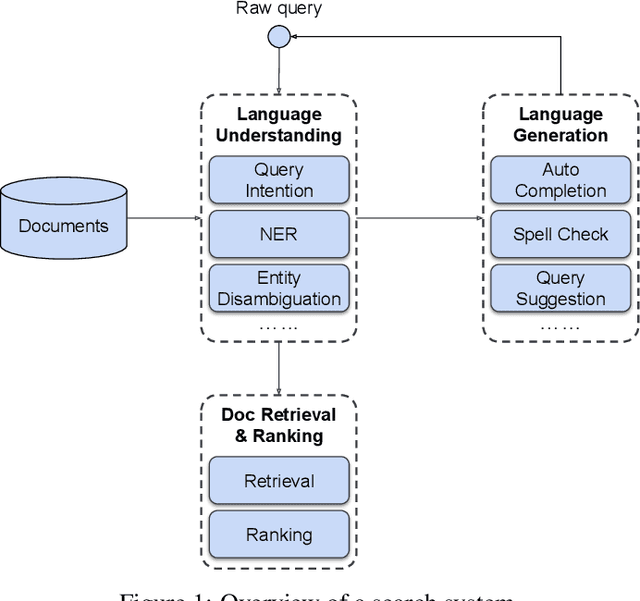

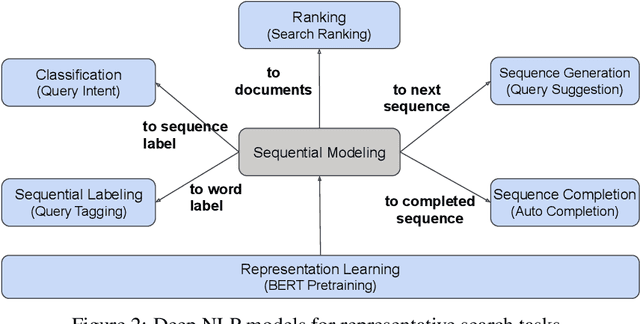

Many search systems work with large amounts of natural language data, e.g., search queries, user profiles, and documents. Building a successful search system requires a thorough understanding of textual data semantics, where deep learning based natural language processing techniques (deep NLP) can be of great help. In this paper, we introduce a comprehensive study for applying deep NLP techniques to five representative tasks in search systems: query intent prediction (classification), query tagging (sequential tagging), document ranking (ranking), query auto completion (language modeling), and query suggestion (sequence to sequence). We also introduce BERT pre-training as a sixth task that can be applied to many of the other tasks. Through the model design and experiments of the six tasks, readers can find answers to four important questions: (1). When is deep NLP helpful/not helpful in search systems? (2). How to address latency challenges? (3). How to ensure model robustness? This work builds on existing efforts of LinkedIn search, and is tested at scale on LinkedIn's commercial search engines. We believe our experiences can provide useful insights for the industry and research communities.
Deep Natural Language Processing for LinkedIn Search Systems
Jul 30, 2021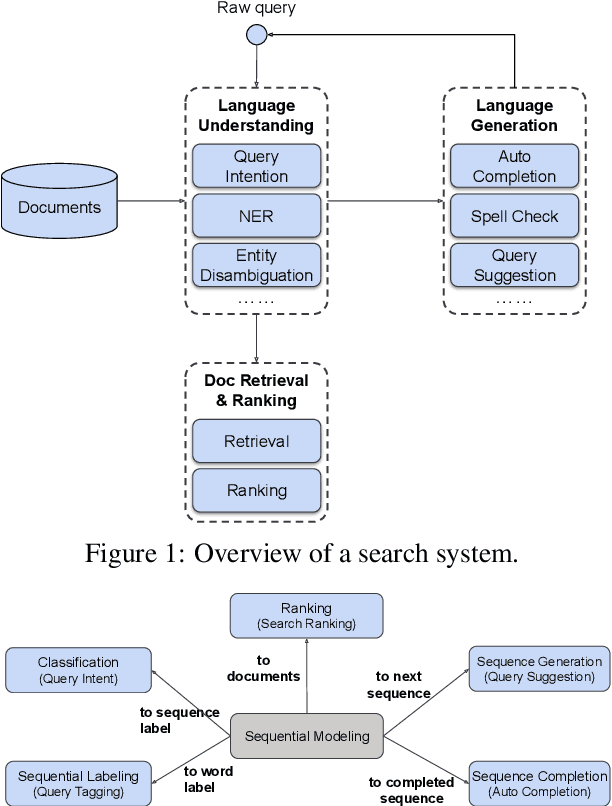
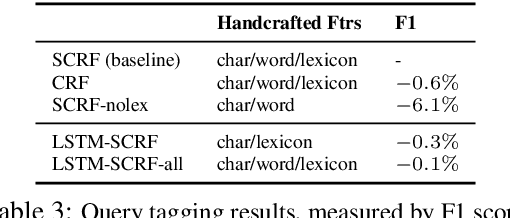
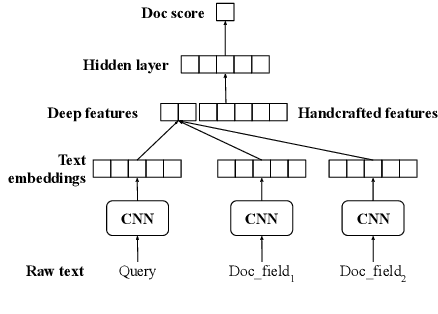
Many search systems work with large amounts of natural language data, e.g., search queries, user profiles and documents, where deep learning based natural language processing techniques (deep NLP) can be of great help. In this paper, we introduce a comprehensive study of applying deep NLP techniques to five representative tasks in search engines. Through the model design and experiments of the five tasks, readers can find answers to three important questions: (1) When is deep NLP helpful/not helpful in search systems? (2) How to address latency challenges? (3) How to ensure model robustness? This work builds on existing efforts of LinkedIn search, and is tested at scale on a commercial search engine. We believe our experiences can provide useful insights for the industry and research communities.
Colorectal Polyp Detection in Real-world Scenario: Design and Experiment Study
Jan 11, 2021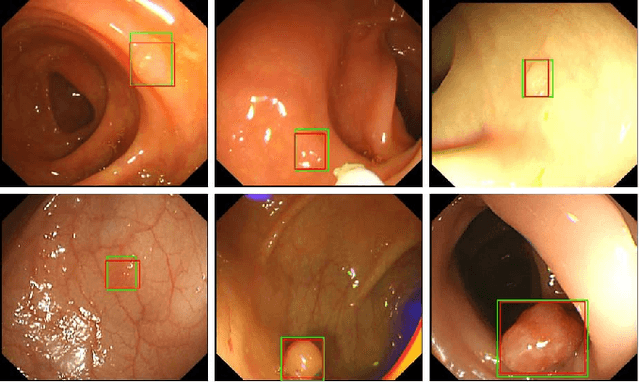
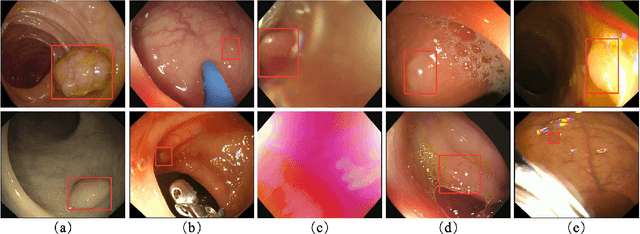


Colorectal polyps are abnormal tissues growing on the intima of the colon or rectum with a high risk of developing into colorectal cancer, the third leading cause of cancer death worldwide. Early detection and removal of colon polyps via colonoscopy have proved to be an effective approach to prevent colorectal cancer. Recently, various CNN-based computer-aided systems have been developed to help physicians detect polyps. However, these systems do not perform well in real-world colonoscopy operations due to the significant difference between images in a real colonoscopy and those in the public datasets. Unlike the well-chosen clear images with obvious polyps in the public datasets, images from a colonoscopy are often blurry and contain various artifacts such as fluid, debris, bubbles, reflection, specularity, contrast, saturation, and medical instruments, with a wide variety of polyps of different sizes, shapes, and textures. All these factors pose a significant challenge to effective polyp detection in a colonoscopy. To this end, we collect a private dataset that contains 7,313 images from 224 complete colonoscopy procedures. This dataset represents realistic operation scenarios and thus can be used to better train the models and evaluate a system's performance in practice. We propose an integrated system architecture to address the unique challenges for polyp detection. Extensive experiments results show that our system can effectively detect polyps in a colonoscopy with excellent performance in real time.
Deep Search Query Intent Understanding
Aug 18, 2020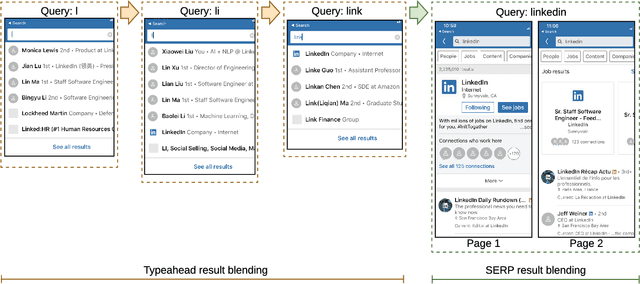


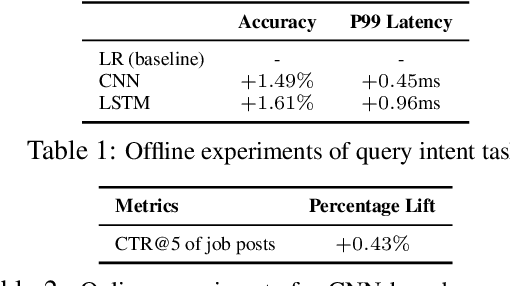
Understanding a user's query intent behind a search is critical for modern search engine success. Accurate query intent prediction allows the search engine to better serve the user's need by rendering results from more relevant categories. This paper aims to provide a comprehensive learning framework for modeling query intent under different stages of a search. We focus on the design for 1) predicting users' intents as they type in queries on-the-fly in typeahead search using character-level models; and 2) accurate word-level intent prediction models for complete queries. Various deep learning components for query text understanding are experimented. Offline evaluation and online A/B test experiments show that the proposed methods are effective in understanding query intent and efficient to scale for online search systems.
DeText: A Deep Text Ranking Framework with BERT
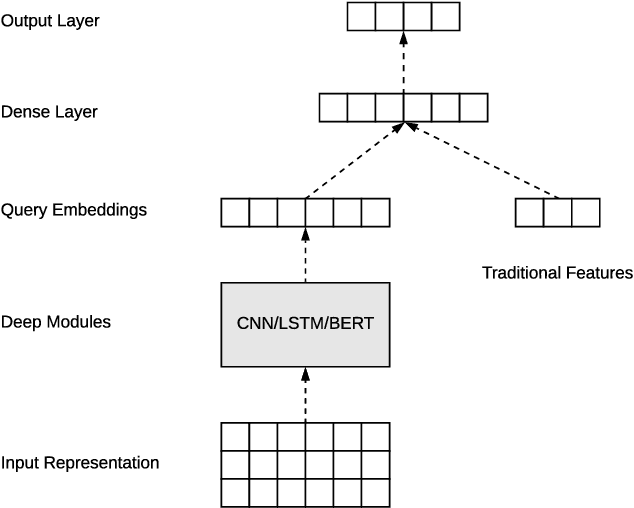
Aug 06, 2020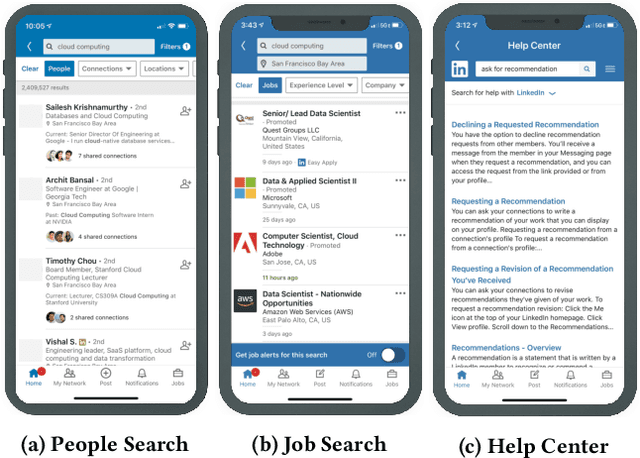

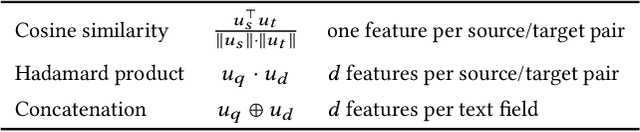
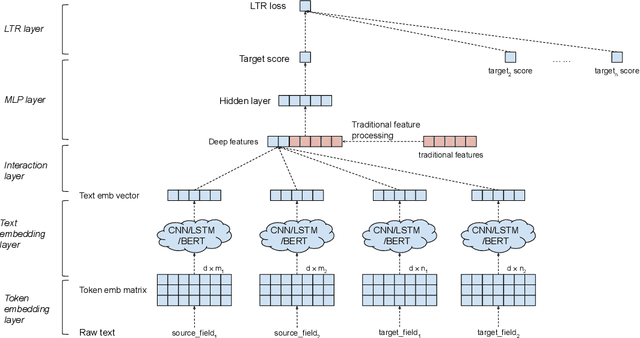
Ranking is the most important component in a search system. Mostsearch systems deal with large amounts of natural language data,hence an effective ranking system requires a deep understandingof text semantics. Recently, deep learning based natural languageprocessing (deep NLP) models have generated promising results onranking systems. BERT is one of the most successful models thatlearn contextual embedding, which has been applied to capturecomplex query-document relations for search ranking. However,this is generally done by exhaustively interacting each query wordwith each document word, which is inefficient for online servingin search product systems. In this paper, we investigate how tobuild an efficient BERT-based ranking model for industry use cases.The solution is further extended to a general ranking framework,DeText, that is open sourced and can be applied to various rankingproductions. Offline and online experiments of DeText on threereal-world search systems present significant improvement overstate-of-the-art approaches.