 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImputation-free and Alignment-free: Incomplete Multi-view Clustering Driven by Consensus Semantic Learning
May 16, 2025In incomplete multi-view clustering (IMVC), missing data induce prototype shifts within views and semantic inconsistencies across views. A feasible solution is to explore cross-view consistency in paired complete observations, further imputing and aligning the similarity relationships inherently shared across views. Nevertheless, existing methods are constrained by two-tiered limitations: (1) Neither instance- nor cluster-level consistency learning construct a semantic space shared across views to learn consensus semantics. The former enforces cross-view instances alignment, and wrongly regards unpaired observations with semantic consistency as negative pairs; the latter focuses on cross-view cluster counterparts while coarsely handling fine-grained intra-cluster relationships within views. (2) Excessive reliance on consistency results in unreliable imputation and alignment without incorporating view-specific cluster information. Thus, we propose an IMVC framework, imputation- and alignment-free for consensus semantics learning (FreeCSL). To bridge semantic gaps across all observations, we learn consensus prototypes from available data to discover a shared space, where semantically similar observations are pulled closer for consensus semantics learning. To capture semantic relationships within specific views, we design a heuristic graph clustering based on modularity to recover cluster structure with intra-cluster compactness and inter-cluster separation for cluster semantics enhancement. Extensive experiments demonstrate, compared to state-of-the-art competitors, FreeCSL achieves more confident and robust assignments on IMVC task.
A manometric feature descriptor with linear-SVM to distinguish esophageal contraction vigor
Nov 27, 2023n clinical, if a patient presents with nonmechanical obstructive dysphagia, esophageal chest pain, and gastro esophageal reflux symptoms, the physician will usually assess the esophageal dynamic function. High-resolution manometry (HRM) is a clinically commonly used technique for detection of esophageal dynamic function comprehensively and objectively. However, after the results of HRM are obtained, doctors still need to evaluate by a variety of parameters. This work is burdensome, and the process is complex. We conducted image processing of HRM to predict the esophageal contraction vigor for assisting the evaluation of esophageal dynamic function. Firstly, we used Feature-Extraction and Histogram of Gradients (FE-HOG) to analyses feature of proposal of swallow (PoS) to further extract higher-order features. Then we determine the classification of esophageal contraction vigor normal, weak and failed by using linear-SVM according to these features. Our data set includes 3000 training sets, 500 validation sets and 411 test sets. After verification our accuracy reaches 86.83%, which is higher than other common machine learning methods.
Multi-Task Fusion via Reinforcement Learning for Long-Term User Satisfaction in Recommender Systems
Aug 10, 2022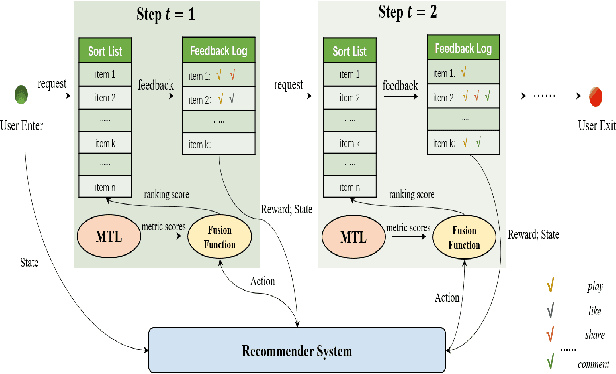
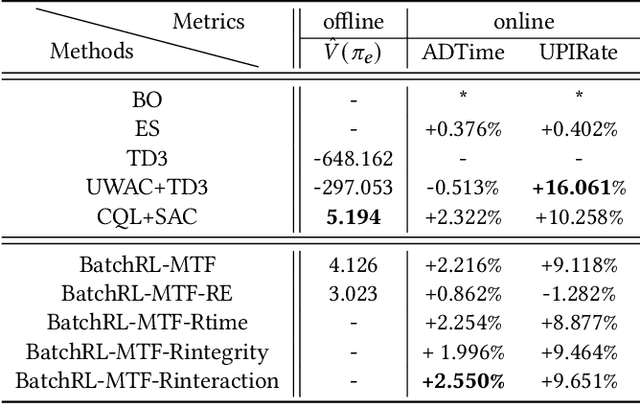
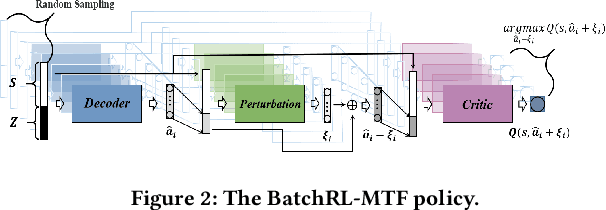
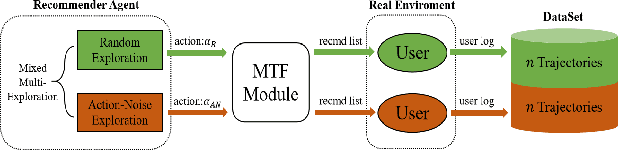
Recommender System (RS) is an important online application that affects billions of users every day. The mainstream RS ranking framework is composed of two parts: a Multi-Task Learning model (MTL) that predicts various user feedback, i.e., clicks, likes, sharings, and a Multi-Task Fusion model (MTF) that combines the multi-task outputs into one final ranking score with respect to user satisfaction. There has not been much research on the fusion model while it has great impact on the final recommendation as the last crucial process of the ranking. To optimize long-term user satisfaction rather than obtain instant returns greedily, we formulate MTF task as Markov Decision Process (MDP) within a recommendation session and propose a Batch Reinforcement Learning (RL) based Multi-Task Fusion framework (BatchRL-MTF) that includes a Batch RL framework and an online exploration. The former exploits Batch RL to learn an optimal recommendation policy from the fixed batch data offline for long-term user satisfaction, while the latter explores potential high-value actions online to break through the local optimal dilemma. With a comprehensive investigation on user behaviors, we model the user satisfaction reward with subtle heuristics from two aspects of user stickiness and user activeness. Finally, we conduct extensive experiments on a billion-sample level real-world dataset to show the effectiveness of our model. We propose a conservative offline policy estimator (Conservative-OPEstimator) to test our model offline. Furthermore, we take online experiments in a real recommendation environment to compare performance of different models. As one of few Batch RL researches applied in MTF task successfully, our model has also been deployed on a large-scale industrial short video platform, serving hundreds of millions of users.