 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaoBench: Do Automated Theorem Prover LLMs Generalize Beyond MathLib?
Mar 13, 2026Automated theorem proving (ATP) benchmarks largely consist of problems formalized in MathLib, so current ATP training and evaluation are heavily biased toward MathLib's definitional framework. However, frontier mathematics is often exploratory and prototype-heavy, relying on bespoke constructions that deviate from standard libraries. In this work, we evaluate the robustness of current ATP systems when applied to a novel definitional framework, specifically examining the performance gap between standard library problems and bespoke mathematical constructions. We introduce TaoBench, an undergraduate-level benchmark derived from Terence Tao's Analysis I, which formalizes analysis by constructing core mathematical concepts from scratch, without relying on standard Mathlib definitions, as well as by mixing from-scratch and MathLib constructions. For fair evaluation, we build an agentic pipeline that automatically extracts a compilable, self-contained local environment for each problem. To isolate the effect of definitional frameworks, we additionally translate every problem into a mathematically equivalent Mathlib formulation, yielding paired TaoBench-Mathlib statements for direct comparison. While state-of-the-art ATP models perform capably within the MathLib framework, performance drops by an average of roughly 26% on the definitionally equivalent Tao formulation. This indicates that the main bottleneck is limited generalization across definitional frameworks rather than task difficulty. TaoBench thus highlights a gap between benchmark performance and applicability, and provides a concrete foundation for developing and testing provers better aligned with research mathematics.
Secure Semantic Communication With Homomorphic Encryption
Jan 17, 2025



In recent years, Semantic Communication (SemCom), which aims to achieve efficient and reliable transmission of meaning between agents, has garnered significant attention from both academia and industry. To ensure the security of communication systems, encryption techniques are employed to safeguard confidentiality and integrity. However, traditional cryptography-based encryption algorithms encounter obstacles when applied to SemCom. Motivated by this, this paper explores the feasibility of applying homomorphic encryption to SemCom. Initially, we review the encryption algorithms utilized in mobile communication systems and analyze the challenges associated with their application to SemCom. Subsequently, we employ scale-invariant feature transform to demonstrate that semantic features can be preserved in homomorphic encrypted ciphertext. Based on this finding, we propose a task-oriented SemCom scheme secured through homomorphic encryption. We design the privacy preserved deep joint source-channel coding (JSCC) encoder and decoder, and the frequency of key updates can be adjusted according to service requirements without compromising transmission performance. Simulation results validate that, when compared to plaintext images, the proposed scheme can achieve almost the same classification accuracy performance when dealing with homomorphic ciphertext images. Furthermore, we provide potential future research directions for homomorphic encrypted SemCom.
Temporal credit assignment for one-shot learning utilizing a phase transition material
Sep 29, 2023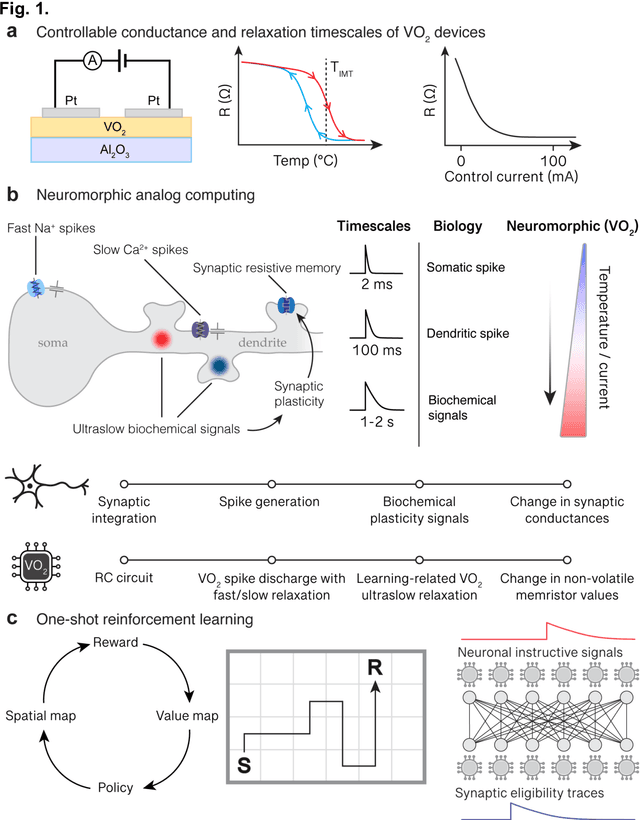
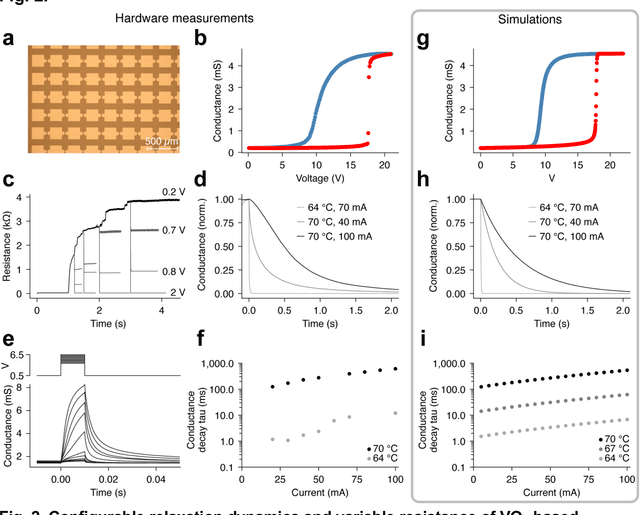
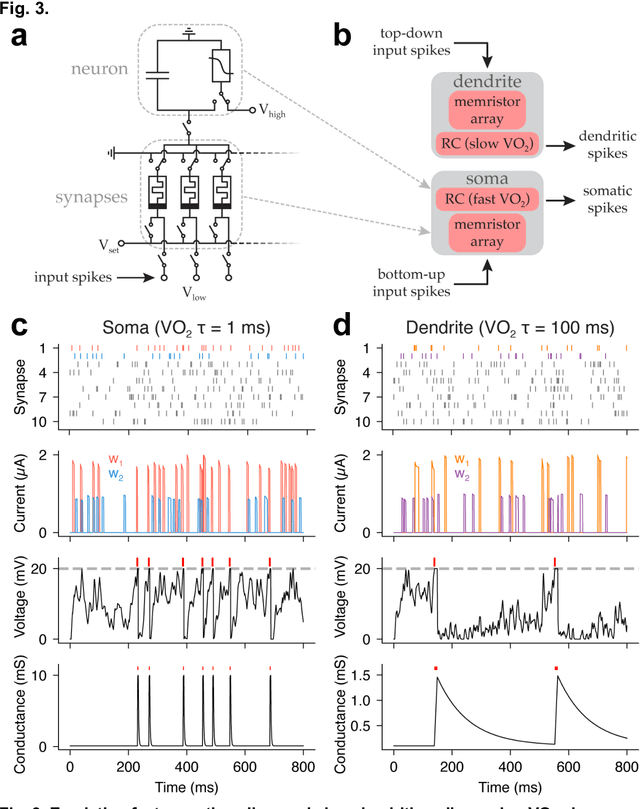
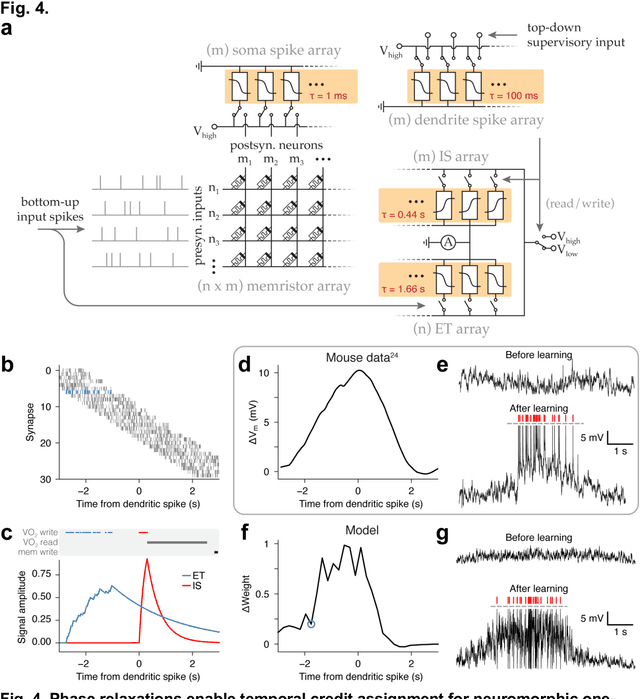
Design of hardware based on biological principles of neuronal computation and plasticity in the brain is a leading approach to realizing energy- and sample-efficient artificial intelligence and learning machines. An important factor in selection of the hardware building blocks is the identification of candidate materials with physical properties suitable to emulate the large dynamic ranges and varied timescales of neuronal signaling. Previous work has shown that the all-or-none spiking behavior of neurons can be mimicked by threshold switches utilizing phase transitions. Here we demonstrate that devices based on a prototypical metal-insulator-transition material, vanadium dioxide (VO2), can be dynamically controlled to access a continuum of intermediate resistance states. Furthermore, the timescale of their intrinsic relaxation can be configured to match a range of biologically-relevant timescales from milliseconds to seconds. We exploit these device properties to emulate three aspects of neuronal analog computation: fast (~1 ms) spiking in a neuronal soma compartment, slow (~100 ms) spiking in a dendritic compartment, and ultraslow (~1 s) biochemical signaling involved in temporal credit assignment for a recently discovered biological mechanism of one-shot learning. Simulations show that an artificial neural network using properties of VO2 devices to control an agent navigating a spatial environment can learn an efficient path to a reward in up to 4 fold fewer trials than standard methods. The phase relaxations described in our study may be engineered in a variety of materials, and can be controlled by thermal, electrical, or optical stimuli, suggesting further opportunities to emulate biological learning.
Multi-Task Fusion via Reinforcement Learning for Long-Term User Satisfaction in Recommender Systems
Aug 10, 2022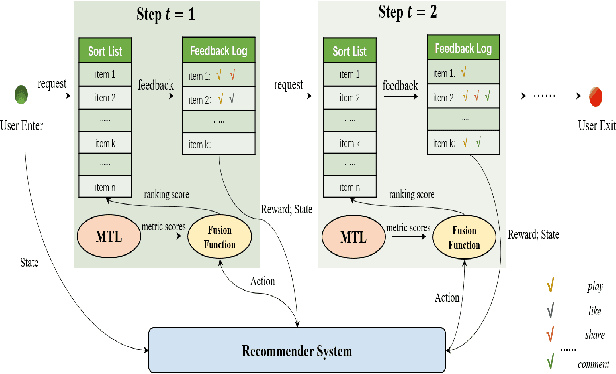
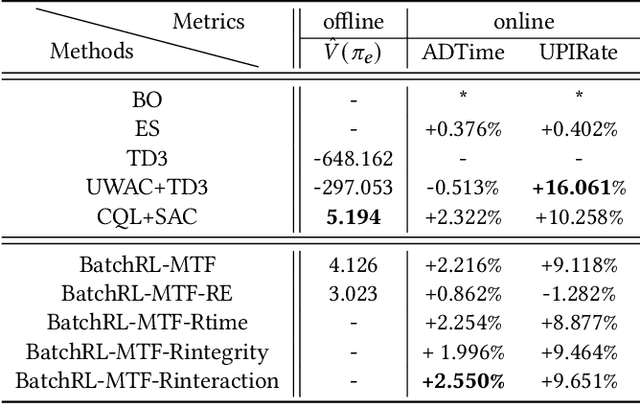
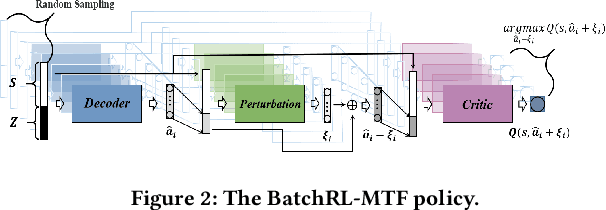
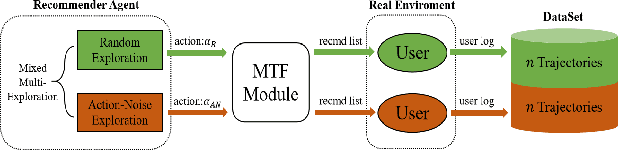
Recommender System (RS) is an important online application that affects billions of users every day. The mainstream RS ranking framework is composed of two parts: a Multi-Task Learning model (MTL) that predicts various user feedback, i.e., clicks, likes, sharings, and a Multi-Task Fusion model (MTF) that combines the multi-task outputs into one final ranking score with respect to user satisfaction. There has not been much research on the fusion model while it has great impact on the final recommendation as the last crucial process of the ranking. To optimize long-term user satisfaction rather than obtain instant returns greedily, we formulate MTF task as Markov Decision Process (MDP) within a recommendation session and propose a Batch Reinforcement Learning (RL) based Multi-Task Fusion framework (BatchRL-MTF) that includes a Batch RL framework and an online exploration. The former exploits Batch RL to learn an optimal recommendation policy from the fixed batch data offline for long-term user satisfaction, while the latter explores potential high-value actions online to break through the local optimal dilemma. With a comprehensive investigation on user behaviors, we model the user satisfaction reward with subtle heuristics from two aspects of user stickiness and user activeness. Finally, we conduct extensive experiments on a billion-sample level real-world dataset to show the effectiveness of our model. We propose a conservative offline policy estimator (Conservative-OPEstimator) to test our model offline. Furthermore, we take online experiments in a real recommendation environment to compare performance of different models. As one of few Batch RL researches applied in MTF task successfully, our model has also been deployed on a large-scale industrial short video platform, serving hundreds of millions of users.