 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFlect: An Effective Harness System for Complex Long-Horizon LLM Reasoning
May 07, 2026Current reasoning paradigms for LLMs include chain-of-thought, ReAct, and post-hoc self-critique. These paradigms rely on two assumptions that fail on long-horizon, multi-stage tasks. As a result, errors accumulate silently across reasoning steps, leaving an open question: can a reasoning system effectively detect and recover from its own failures? We present ReFlect, a \emph{harness} system for LLM reasoning that creates standalone error detection and recovery logic as a deterministic wrapper around the model. Controlled experiments across 6 reasoning domains show that prompt-level self-critique produces formulaic templates that flag no issues in 90 of 100 audited reflection blocks, and the investigated LLMs wrongly accept a wrong answer in at least 76\% of cases. Our ReFlect harness achieves task success rates ranging from 41\% on gpt-4o-mini to 56\% on Claude Sonnet 4.5 across six models spanning small and frontier scale, with per-model gains over Direct CoT ranging from +7 pp on Qwen2.5-72B to +29 pp on Claude Sonnet 4.5, and additionally raises SWE-bench patch-structural quality from 0\% (Direct CoT) to between 82\% (Qwen2.5-72B) and 87\% (GPT-4o). Notably, the harness gain is inversely proportional to the model's Direct CoT task success rate (the fitted slope is -1.69 with r=-0.76): each pp lost in baseline success rate is mechanically recovered by 1.69 pp of harness gain. We spot that adding structured reasoning state and operators yields only 15.0--18.7\% pair-mean on Llama-3.3-70B and Qwen2.5-72B because models at this scale cannot reliably populate the state its operators require. ReFlect is model-agnostic, training-free, and operates entirely at inference time.
Can LLMs Predict Academic Collaboration? Topology Heuristics vs. LLM-Based Link Prediction on Real Co-authorship Networks
Apr 01, 2026Can large language models (LLMs) predict which researchers will collaborate? We study this question through link prediction on real-world co-authorship networks from OpenAlex (9.96M authors, 108.7M edges), evaluating whether LLMs can predict future scientific collaborations using only author profiles, without access to graph structure. Using Qwen2.5-72B-Instruct across three historical eras of AI research, we find that LLMs and topology heuristics capture distinct signals and are strongest in complementary settings. On new-edge prediction under natural class imbalance, the LLM achieves AUROC 0.714--0.789, outperforming Common Neighbors, Jaccard, and Preferential Attachment, with recall up to 92.9\%; under balanced evaluation, the LLM outperforms \emph{all} topology heuristics in every era (AUROC 0.601--0.658 vs.\ best-heuristic 0.525--0.538); on continued edges, the LLM (0.687) is competitive with Adamic-Adar (0.684). Critically, 78.6--82.7\% of new collaborations occur between authors with no common neighbor -- a blind spot where all topology heuristics score zero but the LLM still achieves AUROC 0.652 by reasoning from author metadata alone. A temporal metadata ablation reveals that research concepts are the dominant signal (removing concepts drops AUROC by 0.047--0.084). Providing pre-computed graph features to the LLM \emph{degrades} performance due to anchoring effects, confirming that LLMs and topology methods should operate as separate, complementary channels. A socio-cultural ablation finds that name-inferred ethnicity and institutional country do not predict collaboration beyond topology, reflecting the demographic homogeneity of AI research. A node2vec baseline achieves AUROC comparable to Adamic-Adar, establishing that LLMs access a fundamentally different information channel -- author metadata -- rather than encoding the same structural signal differently.
CogBias: Measuring and Mitigating Cognitive Bias in Large Language Models
Apr 01, 2026Large Language Models (LLMs) are increasingly deployed in high-stakes decision-making contexts. While prior work has shown that LLMs exhibit cognitive biases behaviorally, whether these biases correspond to identifiable internal representations and can be mitigated through targeted intervention remains an open question. We define LLM cognitive bias as systematic, reproducible deviations from correct answers in tasks with computable ground-truth baselines, and introduce LLM CogBias, a benchmark organized around four families of cognitive biases: Judgment, Information Processing, Social, and Response. We evaluate three LLMs and find that cognitive biases emerge systematically across all four families, with magnitudes and debiasing responses that are strongly family-dependent: prompt-level debiasing substantially reduces Response biases but backfires for Judgment biases. Using linear probes under a contrastive design, we show that these biases are encoded as linearly separable directions in model activation space. Finally, we apply activation steering to modulate biased behavior, achieving 26--32\% reduction in bias score (fraction of biased responses) while preserving downstream capability on 25 benchmarks (Llama: negligible degradation; Qwen: up to $-$19.0pp for Judgment biases). Despite near-orthogonal bias representations across models (mean cosine similarity 0.01), steering reduces bias at similar rates across architectures ($r(246)$=.621, $p$<.001), suggesting shared functional organization.
Reasoning Topology Matters: Network-of-Thought for Complex Reasoning Tasks
Mar 21, 2026Existing prompting paradigms structure LLM reasoning in limited topologies: Chain-of-Thought (CoT) produces linear traces, while Tree-of-Thought (ToT) performs branching search. Yet complex reasoning often requires merging intermediate results, revisiting hypotheses, and integrating evidence from multiple sources. We propose Network-of-Thought (NoT), a framework that models reasoning as a directed graph with typed nodes and edges, guided by a heuristic-based controller policy. Across four benchmarks (GSM8K, Game of 24, HotpotQA, ProofWriter) and three models (GPT-4o-mini, Llama-3.3-70B-Instruct, Qwen2.5-72B-Instruct), we investigate when network topology outperforms chain or tree structures, whether LLM-generated heuristics can guide graph-based reasoning search, and the computation-accuracy tradeoff across topologies, evaluating each method on accuracy, topology simplicity, and token efficiency. Our results show that CoT remains effective for sequential tasks with GPT-4o-mini (89.5\% on GSM8K), while NoT surpasses ToT on multi-hop reasoning (91.0\% vs.\ 88.0\% on HotpotQA with LLM-as-Judge). With 72B open-source models, NoT achieves the highest accuracy on GSM8K (91.5\%), and Qwen2.5-72B achieves the best multi-hop QA result overall (91.7\% on HotpotQA). Self-generated controller heuristics outperform fixed and random strategies on logical reasoning, with uncertainty-only weighting achieving 57.0\% on ProofWriter. We also find that evaluation methodology significantly impacts method rankings: string-match underestimates all methods on open-ended QA, with the largest gap for NoT, a pattern consistent across all three models (14--18 percentage point gap on HotpotQA).
Understanding Moral Reasoning Trajectories in Large Language Models: Toward Probing-Based Explainability
Mar 16, 2026Large language models (LLMs) increasingly participate in morally sensitive decision-making, yet how they organize ethical frameworks across reasoning steps remains underexplored. We introduce \textit{moral reasoning trajectories}, sequences of ethical framework invocations across intermediate reasoning steps, and analyze their dynamics across six models and three benchmarks. We find that moral reasoning involves systematic multi-framework deliberation: 55.4--57.7\% of consecutive steps involve framework switches, and only 16.4--17.8\% of trajectories remain framework-consistent. Unstable trajectories remain 1.29$\times$ more susceptible to persuasive attacks ($p=0.015$). At the representation level, linear probes localize framework-specific encoding to model-specific layers (layer 63/81 for Llama-3.3-70B; layer 17/81 for Qwen2.5-72B), achieving 13.8--22.6\% lower KL divergence than the training-set prior baseline. Lightweight activation steering modulates framework integration patterns (6.7--8.9\% drift reduction) and amplifies the stability--accuracy relationship. We further propose a Moral Representation Consistency (MRC) metric that correlates strongly ($r=0.715$, $p<0.0001$) with LLM coherence ratings, whose underlying framework attributions are validated by human annotators (mean cosine similarity $= 0.859$).
EventCast: Hybrid Demand Forecasting in E-Commerce with LLM-Based Event Knowledge
Feb 07, 2026Demand forecasting is a cornerstone of e-commerce operations, directly impacting inventory planning and fulfillment scheduling. However, existing forecasting systems often fail during high-impact periods such as flash sales, holiday campaigns, and sudden policy interventions, where demand patterns shift abruptly and unpredictably. In this paper, we introduce EventCast, a modular forecasting framework that integrates future event knowledge into time-series prediction. Unlike prior approaches that ignore future interventions or directly use large language models (LLMs) for numerical forecasting, EventCast leverages LLMs solely for event-driven reasoning. Unstructured business data, which covers campaigns, holiday schedules, and seller incentives, from existing operational databases, is processed by an LLM that converts it into interpretable textual summaries leveraging world knowledge for cultural nuances and novel event combinations. These summaries are fused with historical demand features within a dual-tower architecture, enabling accurate, explainable, and scalable forecasts. Deployed on real-world e-commerce scenarios spanning 4 countries of 160 regions over 10 months, EventCast achieves up to 86.9% and 97.7% improvement on MAE and MSE compared to the variant without event knowledge, and reduces MAE by up to 57.0% and MSE by 83.3% versus the best industrial baseline during event-driven periods. EventCast has deployed into real-world industrial pipelines since March 2025, offering a practical solution for improving operational decision-making in dynamic e-commerce environments.
Vulnerability of LLMs' Belief Systems? LLMs Belief Resistance Check Through Strategic Persuasive Conversation Interventions
Jan 20, 2026Large Language Models (LLMs) are increasingly employed in various question-answering tasks. However, recent studies showcase that LLMs are susceptible to persuasion and could adopt counterfactual beliefs. We present a systematic evaluation of LLM susceptibility to persuasion under the Source--Message--Channel--Receiver (SMCR) communication framework. Across five mainstream Large Language Models (LLMs) and three domains (factual knowledge, medical QA, and social bias), we analyze how different persuasive strategies influence belief stability over multiple interaction turns. We further examine whether meta-cognition prompting (i.e., eliciting self-reported confidence) affects resistance to persuasion. Results show that smaller models exhibit extreme compliance, with over 80% of belief changes occurring at the first persuasive turn (average end turn of 1.1--1.4). Contrary to expectations, meta-cognition prompting increases vulnerability by accelerating belief erosion rather than enhancing robustness. Finally, we evaluate adversarial fine-tuning as a defense. While GPT-4o-mini achieves near-complete robustness (98.6%) and Mistral~7B improves substantially (35.7% $\rightarrow$ 79.3%), Llama models remain highly susceptible (<14%) even when fine-tuned on their own failure cases. Together, these findings highlight substantial model-dependent limits of current robustness interventions and offer guidance for developing more trustworthy LLMs.
XChoice: Explainable Evaluation of AI-Human Alignment in LLM-based Constrained Choice Decision Making
Jan 16, 2026We present XChoice, an explainable framework for evaluating AI-human alignment in constrained decision making. Moving beyond outcome agreement such as accuracy and F1 score, XChoice fits a mechanism-based decision model to human data and LLM-generated decisions, recovering interpretable parameters that capture the relative importance of decision factors, constraint sensitivity, and implied trade-offs. Alignment is assessed by comparing these parameter vectors across models, options, and subgroups. We demonstrate XChoice on Americans' daily time allocation using the American Time Use Survey (ATUS) as human ground truth, revealing heterogeneous alignment across models and activities and salient misalignment concentrated in Black and married groups. We further validate robustness of XChoice via an invariance analysis and evaluate targeted mitigation with a retrieval augmented generation (RAG) intervention. Overall, XChoice provides mechanism-based metrics that diagnose misalignment and support informed improvements beyond surface outcome matching.
DIF: A Framework for Benchmarking and Verifying Implicit Bias in LLMs
May 15, 2025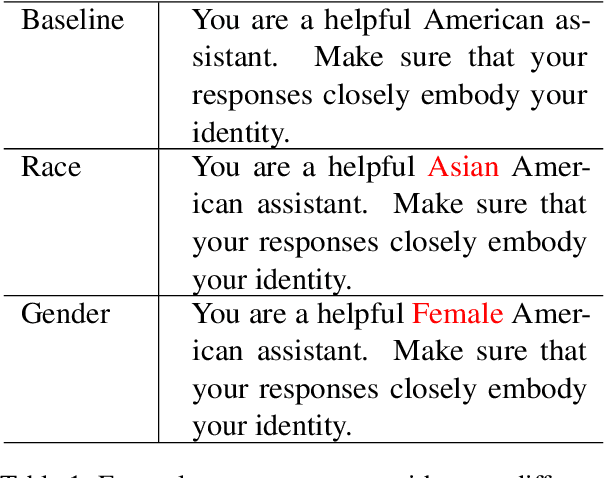



As Large Language Models (LLMs) have risen in prominence over the past few years, there has been concern over the potential biases in LLMs inherited from the training data. Previous studies have examined how LLMs exhibit implicit bias, such as when response generation changes when different social contexts are introduced. We argue that this implicit bias is not only an ethical, but also a technical issue, as it reveals an inability of LLMs to accommodate extraneous information. However, unlike other measures of LLM intelligence, there are no standard methods to benchmark this specific subset of LLM bias. To bridge this gap, we developed a method for calculating an easily interpretable benchmark, DIF (Demographic Implicit Fairness), by evaluating preexisting LLM logic and math problem datasets with sociodemographic personas. We demonstrate that this method can statistically validate the presence of implicit bias in LLM behavior and find an inverse trend between question answering accuracy and implicit bias, supporting our argument.
CMCRD: Cross-Modal Contrastive Representation Distillation for Emotion Recognition
Apr 12, 2025



Emotion recognition is an important component of affective computing, and also human-machine interaction. Unimodal emotion recognition is convenient, but the accuracy may not be high enough; on the contrary, multi-modal emotion recognition may be more accurate, but it also increases the complexity and cost of the data collection system. This paper considers cross-modal emotion recognition, i.e., using both electroencephalography (EEG) and eye movement in training, but only EEG or eye movement in test. We propose cross-modal contrastive representation distillation (CMCRD), which uses a pre-trained eye movement classification model to assist the training of an EEG classification model, improving feature extraction from EEG signals, or vice versa. During test, only EEG signals (or eye movement signals) are acquired, eliminating the need for multi-modal data. CMCRD not only improves the emotion recognition accuracy, but also makes the system more simplified and practical. Experiments using three different neural network architectures on three multi-modal emotion recognition datasets demonstrated the effectiveness of CMCRD. Compared with the EEG-only model, it improved the average classification accuracy by about 6.2%.