 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraDE: A Graph Diffusion Estimator for Frequent Subgraph Discovery in Neural Architectures
Feb 03, 2026Finding frequently occurring subgraph patterns or network motifs in neural architectures is crucial for optimizing efficiency, accelerating design, and uncovering structural insights. However, as the subgraph size increases, enumeration-based methods are perfectly accurate but computationally prohibitive, while sampling-based methods are computationally tractable but suffer from a severe decline in discovery capability. To address these challenges, this paper proposes GraDE, a diffusion-guided search framework that ensures both computational feasibility and discovery capability. The key innovation is the Graph Diffusion Estimator (GraDE), which is the first to introduce graph diffusion models to identify frequent subgraphs by scoring their typicality within the learned distribution. Comprehensive experiments demonstrate that the estimator achieves superior ranking accuracy, with up to 114\% improvement compared to sampling-based baselines. Benefiting from this, the proposed framework successfully discovers large-scale frequent patterns, achieving up to 30$\times$ higher median frequency than sampling-based methods.
Establishing Rigorous and Cost-effective Clinical Trials for Artificial Intelligence Models
Jul 11, 2024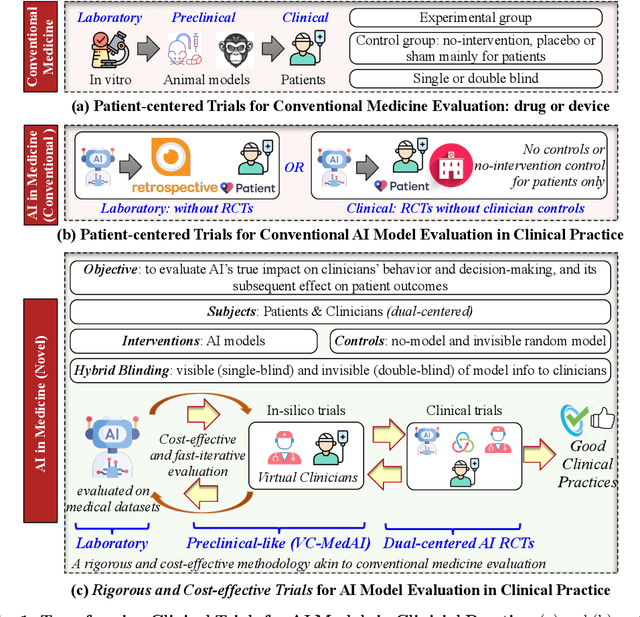
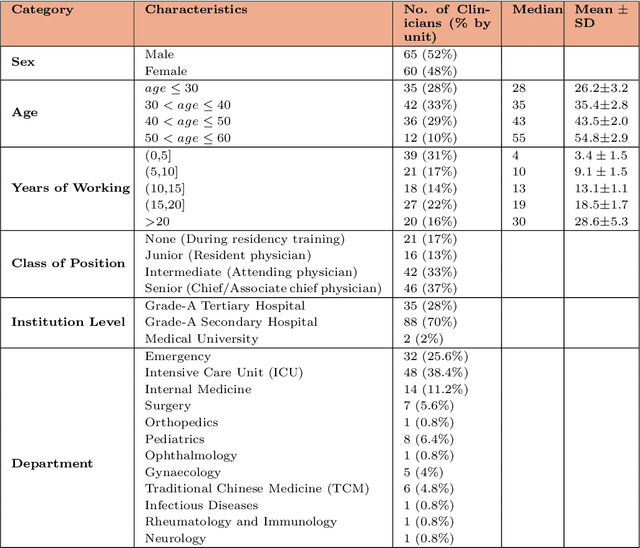
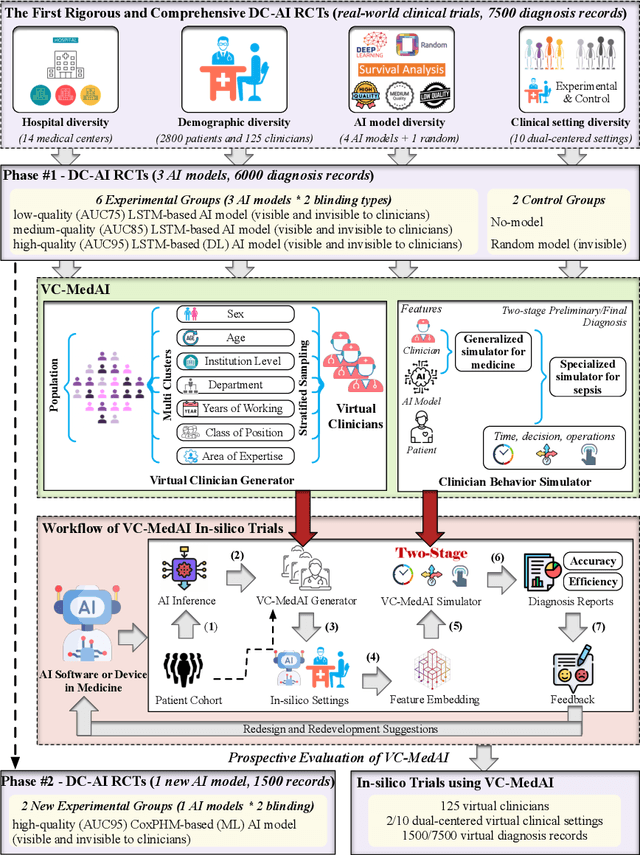
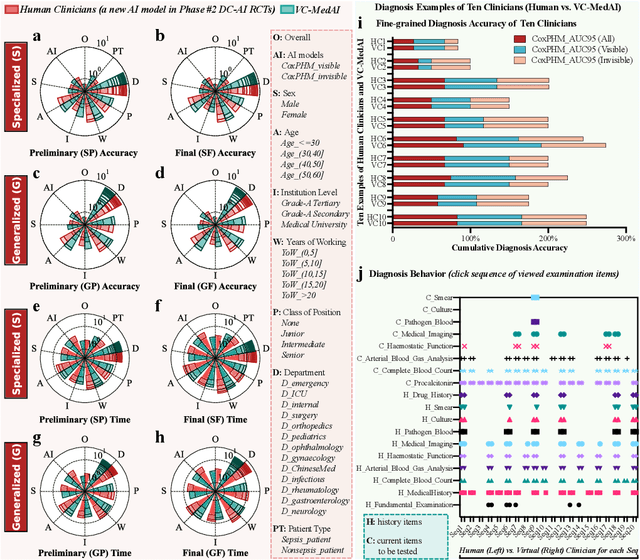
A profound gap persists between artificial intelligence (AI) and clinical practice in medicine, primarily due to the lack of rigorous and cost-effective evaluation methodologies. State-of-the-art and state-of-the-practice AI model evaluations are limited to laboratory studies on medical datasets or direct clinical trials with no or solely patient-centered controls. Moreover, the crucial role of clinicians in collaborating with AI, pivotal for determining its impact on clinical practice, is often overlooked. For the first time, we emphasize the critical necessity for rigorous and cost-effective evaluation methodologies for AI models in clinical practice, featuring patient/clinician-centered (dual-centered) AI randomized controlled trials (DC-AI RCTs) and virtual clinician-based in-silico trials (VC-MedAI) as an effective proxy for DC-AI RCTs. Leveraging 7500 diagnosis records from two-phase inaugural DC-AI RCTs across 14 medical centers with 125 clinicians, our results demonstrate the necessity of DC-AI RCTs and the effectiveness of VC-MedAI. Notably, VC-MedAI performs comparably to human clinicians, replicating insights and conclusions from prospective DC-AI RCTs. We envision DC-AI RCTs and VC-MedAI as pivotal advancements, presenting innovative and transformative evaluation methodologies for AI models in clinical practice, offering a preclinical-like setting mirroring conventional medicine, and reshaping development paradigms in a cost-effective and fast-iterative manner. Chinese Clinical Trial Registration: ChiCTR2400086816.
Younger: The First Dataset for Artificial Intelligence-Generated Neural Network Architecture
Jun 20, 2024



Designing and optimizing neural network architectures typically requires extensive expertise, starting with handcrafted designs and then manual or automated refinement. This dependency presents a significant barrier to rapid innovation. Recognizing the complexity of automatically generating neural network architecture from scratch, we introduce Younger, a pioneering dataset to advance this ambitious goal. Derived from over 174K real-world models across more than 30 tasks from various public model hubs, Younger includes 7,629 unique architectures, and each is represented as a directed acyclic graph with detailed operator-level information. The dataset facilitates two primary design paradigms: global, for creating complete architectures from scratch, and local, for detailed architecture component refinement. By establishing these capabilities, Younger contributes to a new frontier, Artificial Intelligence-Generated Neural Network Architecture (AIGNNA). Our experiments explore the potential and effectiveness of Younger for automated architecture generation and, as a secondary benefit, demonstrate that Younger can serve as a benchmark dataset, advancing the development of graph neural networks. We release the dataset and code publicly to lower the entry barriers and encourage further research in this challenging area.
AIGCBench: Comprehensive Evaluation of Image-to-Video Content Generated by AI
Jan 08, 2024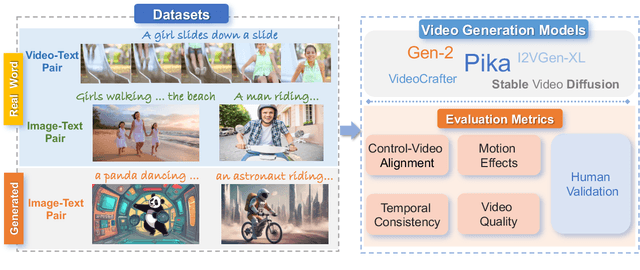
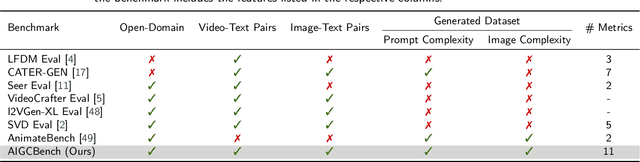
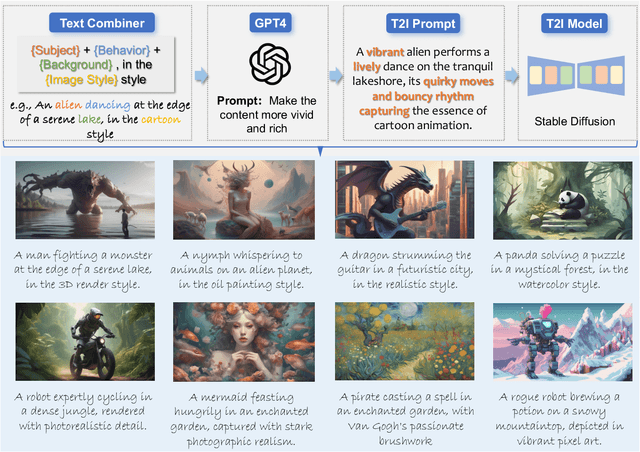
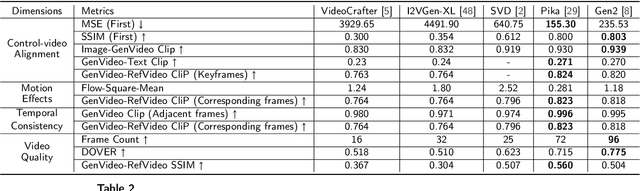
The burgeoning field of Artificial Intelligence Generated Content (AIGC) is witnessing rapid advancements, particularly in video generation. This paper introduces AIGCBench, a pioneering comprehensive and scalable benchmark designed to evaluate a variety of video generation tasks, with a primary focus on Image-to-Video (I2V) generation. AIGCBench tackles the limitations of existing benchmarks, which suffer from a lack of diverse datasets, by including a varied and open-domain image-text dataset that evaluates different state-of-the-art algorithms under equivalent conditions. We employ a novel text combiner and GPT-4 to create rich text prompts, which are then used to generate images via advanced Text-to-Image models. To establish a unified evaluation framework for video generation tasks, our benchmark includes 11 metrics spanning four dimensions to assess algorithm performance. These dimensions are control-video alignment, motion effects, temporal consistency, and video quality. These metrics are both reference video-dependent and video-free, ensuring a comprehensive evaluation strategy. The evaluation standard proposed correlates well with human judgment, providing insights into the strengths and weaknesses of current I2V algorithms. The findings from our extensive experiments aim to stimulate further research and development in the I2V field. AIGCBench represents a significant step toward creating standardized benchmarks for the broader AIGC landscape, proposing an adaptable and equitable framework for future assessments of video generation tasks. We have open-sourced the dataset and evaluation code on the project website: https://www.benchcouncil.org/AIGCBench.
AGIBench: A Multi-granularity, Multimodal, Human-referenced, Auto-scoring Benchmark for Large Language Models
Sep 05, 2023

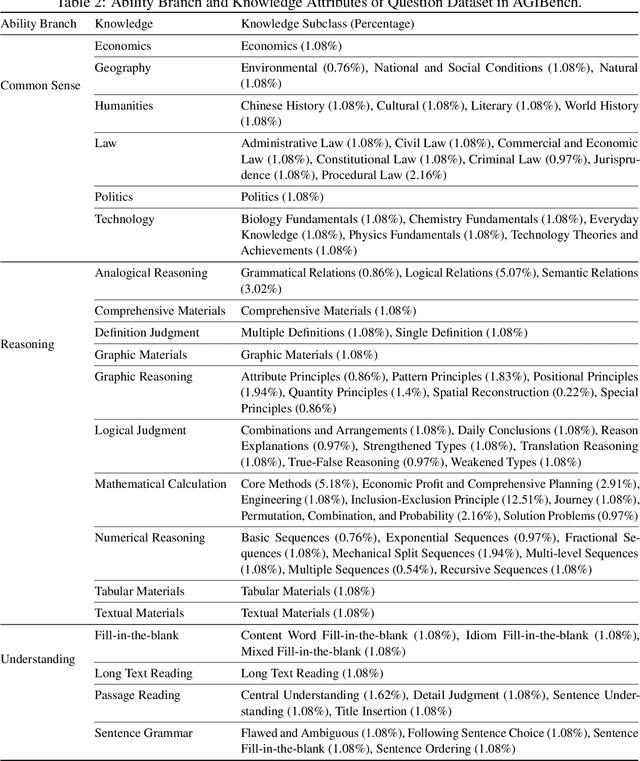

Large language models (LLMs) like ChatGPT have revealed amazing intelligence. How to evaluate the question-solving abilities of LLMs and their degrees of intelligence is a hot-spot but challenging issue. First, the question-solving abilities are interlaced with different ability branches like understanding and massive knowledge categories like mathematics. Second, the inputs of questions are multimodal that may involve text and images. Third, the response format of LLMs is diverse and thus poses great challenges for result extraction and evaluation. In this paper, we propose AGIBench -- a multi-granularity, multimodal, human-referenced, and auto-scoring benchmarking methodology for LLMs. Instead of a collection of blended questions, AGIBench focuses on three typical ability branches and adopts a four-tuple <ability branch, knowledge, difficulty, modal> to label the attributes of each question. First, it supports multi-granularity benchmarking, e.g., per-question, per-ability branch, per-knowledge, per-modal, per-dataset, and per-difficulty level granularities. Second, it contains multimodal input, including text and images. Third, it classifies all the questions into five degrees of difficulty according to the average accuracy rate of abundant educated humans (human-referenced). Fourth, it adopts zero-shot learning to avoid introducing additional unpredictability and provides an auto-scoring method to extract and judge the result. Finally, it defines multi-dimensional metrics, including accuracy under the average, worst, best, and majority voting cases, and repeatability. AGIBench is publically available from \url{https://www.benchcouncil.org/agibench}.
Does AI for science need another ImageNet Or totally different benchmarks? A case study of machine learning force fields
Aug 11, 2023



AI for science (AI4S) is an emerging research field that aims to enhance the accuracy and speed of scientific computing tasks using machine learning methods. Traditional AI benchmarking methods struggle to adapt to the unique challenges posed by AI4S because they assume data in training, testing, and future real-world queries are independent and identically distributed, while AI4S workloads anticipate out-of-distribution problem instances. This paper investigates the need for a novel approach to effectively benchmark AI for science, using the machine learning force field (MLFF) as a case study. MLFF is a method to accelerate molecular dynamics (MD) simulation with low computational cost and high accuracy. We identify various missed opportunities in scientifically meaningful benchmarking and propose solutions to evaluate MLFF models, specifically in the aspects of sample efficiency, time domain sensitivity, and cross-dataset generalization capabilities. By setting up the problem instantiation similar to the actual scientific applications, more meaningful performance metrics from the benchmark can be achieved. This suite of metrics has demonstrated a better ability to assess a model's performance in real-world scientific applications, in contrast to traditional AI benchmarking methodologies. This work is a component of the SAIBench project, an AI4S benchmarking suite. The project homepage is https://www.computercouncil.org/SAIBench.
IterLara: A Turing Complete Algebra for Big Data, AI, Scientific Computing, and Database
Jul 17, 2023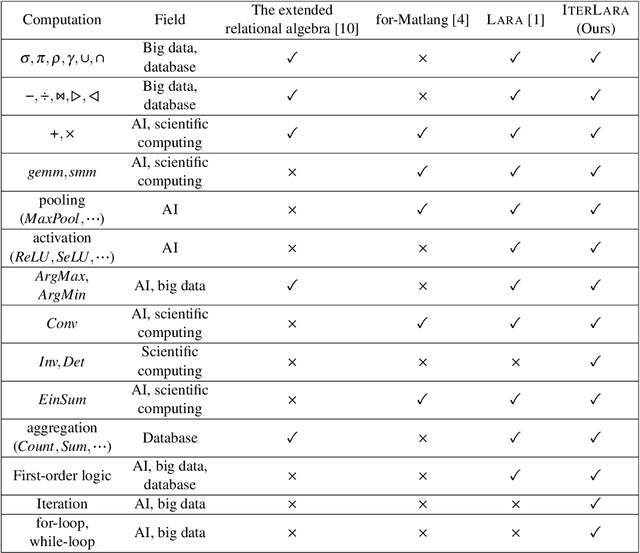
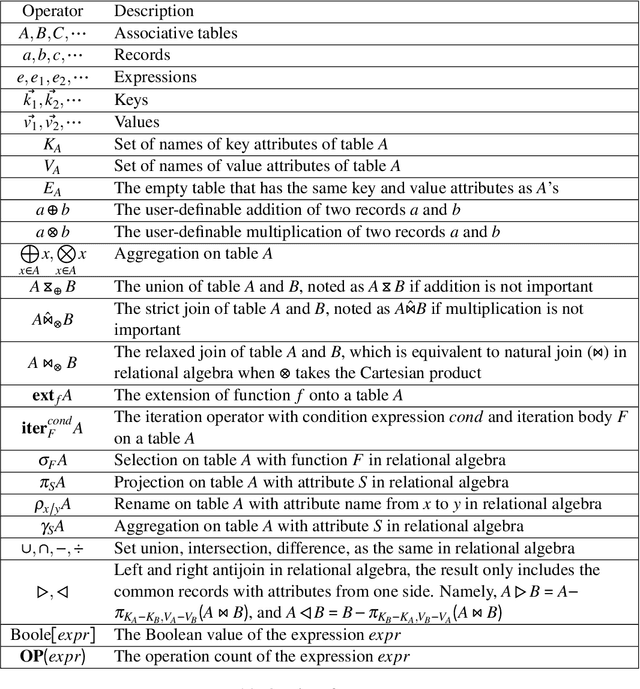
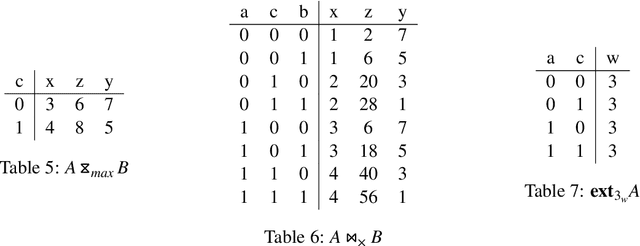
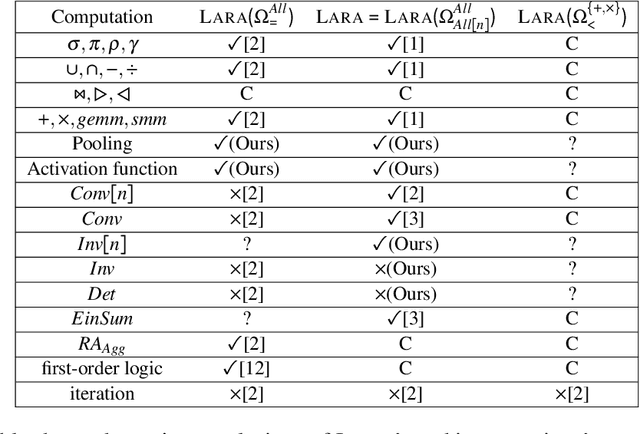
\textsc{Lara} is a key-value algebra that aims at unifying linear and relational algebra with three types of operation abstraction. The study of \textsc{Lara}'s expressive ability reports that it can represent relational algebra and most linear algebra operations. However, several essential computations, such as matrix inversion and determinant, cannot be expressed in \textsc{Lara}. \textsc{Lara} cannot represent global and iterative computation, either. This article proposes \textsc{IterLara}, extending \textsc{Lara} with iterative operators, to provide an algebraic model that unifies operations in general-purpose computing, like big data, AI, scientific computing, and database. We study the expressive ability of \textsc{Lara} and \textsc{IterLara} and prove that \textsc{IterLara} with aggregation functions can represent matrix inversion, determinant. Besides, we demonstrate that \textsc{IterLara} with no limitation of function utility is Turing complete. We also propose the Operation Count (OP) as a metric of computation amount for \textsc{IterLara} and ensure that the OP metric is in accordance with the existing computation metrics.
CMLCompiler: A Unified Compiler for Classical Machine Learning
Feb 01, 2023



Classical machine learning (CML) occupies nearly half of machine learning pipelines in production applications. Unfortunately, it fails to utilize the state-of-the-practice devices fully and performs poorly. Without a unified framework, the hybrid deployments of deep learning (DL) and CML also suffer from severe performance and portability issues. This paper presents the design of a unified compiler, called CMLCompiler, for CML inference. We propose two unified abstractions: operator representations and extended computational graphs. The CMLCompiler framework performs the conversion and graph optimization based on two unified abstractions, then outputs an optimized computational graph to DL compilers or frameworks. We implement CMLCompiler on TVM. The evaluation shows CMLCompiler's portability and superior performance. It achieves up to 4.38x speedup on CPU, 3.31x speedup on GPU, and 5.09x speedup on IoT devices, compared to the state-of-the-art solutions -- scikit-learn, intel sklearn, and hummingbird. Our performance of CML and DL mixed pipelines achieves up to 3.04x speedup compared with cross-framework implementations.
Quality at the Tail
Dec 25, 2022



Practical applications employing deep learning must guarantee inference quality. However, we found that the inference quality of state-of-the-art and state-of-the-practice in practical applications has a long tail distribution. In the real world, many tasks have strict requirements for the quality of deep learning inference, such as safety-critical and mission-critical tasks. The fluctuation of inference quality seriously affects its practical applications, and the quality at the tail may lead to severe consequences. State-of-the-art and state-of-the-practice with outstanding inference quality designed and trained under loose constraints still have poor inference quality under constraints with practical application significance. On the one hand, the neural network models must be deployed on complex systems with limited resources. On the other hand, safety-critical and mission-critical tasks need to meet more metric constraints while ensuring high inference quality. We coin a new term, ``tail quality,'' to characterize this essential requirement and challenge. We also propose a new metric, ``X-Critical-Quality,'' to measure the inference quality under certain constraints. This article reveals factors contributing to the failure of using state-of-the-art and state-of-the-practice algorithms and systems in real scenarios. Therefore, we call for establishing innovative methodologies and tools to tackle this enormous challenge.
ToL: A Tensor of List-Based Unified Computation Model
Dec 21, 2022
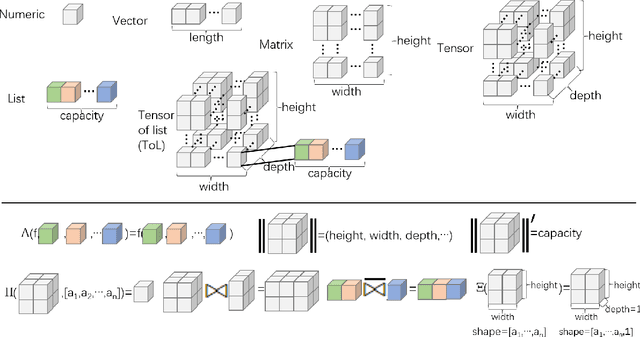


Previous computation models either have equivalent abilities in representing all computations but fail to provide primitive operators for programming complex algorithms or lack generalized expression ability to represent newly-added computations. This article presents a unified computation model with generalized expression ability and a concise set of primitive operators for programming high-level algorithms. We propose a unified data abstraction -- Tensor of List, and offer a unified computation model based on Tensor of List, which we call the ToL model (in short, ToL). ToL introduces five atomic computations that can represent any elementary computation by finite composition, ensured with strict formal proof. Based on ToL, we design a pure-functional language -- ToLang. ToLang provides a concise set of primitive operators that can be used to program complex big data and AI algorithms. Our evaluations show ToL has generalized expression ability and a built-in performance indicator, born with a strictly defined computation metric -- elementary operation count (EOPs), consistent with FLOPs within a small error range.