 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraDE: A Graph Diffusion Estimator for Frequent Subgraph Discovery in Neural Architectures
Feb 03, 2026Finding frequently occurring subgraph patterns or network motifs in neural architectures is crucial for optimizing efficiency, accelerating design, and uncovering structural insights. However, as the subgraph size increases, enumeration-based methods are perfectly accurate but computationally prohibitive, while sampling-based methods are computationally tractable but suffer from a severe decline in discovery capability. To address these challenges, this paper proposes GraDE, a diffusion-guided search framework that ensures both computational feasibility and discovery capability. The key innovation is the Graph Diffusion Estimator (GraDE), which is the first to introduce graph diffusion models to identify frequent subgraphs by scoring their typicality within the learned distribution. Comprehensive experiments demonstrate that the estimator achieves superior ranking accuracy, with up to 114\% improvement compared to sampling-based baselines. Benefiting from this, the proposed framework successfully discovers large-scale frequent patterns, achieving up to 30$\times$ higher median frequency than sampling-based methods.
Younger: The First Dataset for Artificial Intelligence-Generated Neural Network Architecture
Jun 20, 2024



Designing and optimizing neural network architectures typically requires extensive expertise, starting with handcrafted designs and then manual or automated refinement. This dependency presents a significant barrier to rapid innovation. Recognizing the complexity of automatically generating neural network architecture from scratch, we introduce Younger, a pioneering dataset to advance this ambitious goal. Derived from over 174K real-world models across more than 30 tasks from various public model hubs, Younger includes 7,629 unique architectures, and each is represented as a directed acyclic graph with detailed operator-level information. The dataset facilitates two primary design paradigms: global, for creating complete architectures from scratch, and local, for detailed architecture component refinement. By establishing these capabilities, Younger contributes to a new frontier, Artificial Intelligence-Generated Neural Network Architecture (AIGNNA). Our experiments explore the potential and effectiveness of Younger for automated architecture generation and, as a secondary benefit, demonstrate that Younger can serve as a benchmark dataset, advancing the development of graph neural networks. We release the dataset and code publicly to lower the entry barriers and encourage further research in this challenging area.
AGIBench: A Multi-granularity, Multimodal, Human-referenced, Auto-scoring Benchmark for Large Language Models
Sep 05, 2023

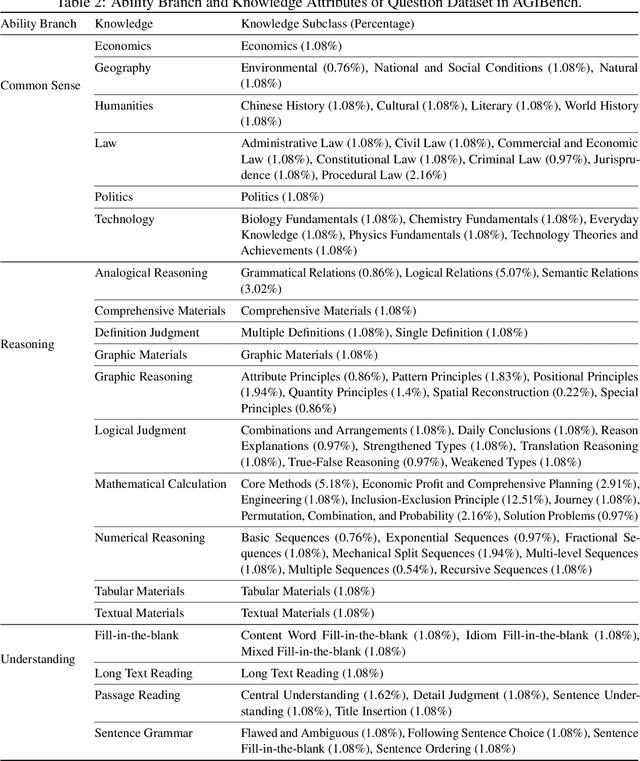

Large language models (LLMs) like ChatGPT have revealed amazing intelligence. How to evaluate the question-solving abilities of LLMs and their degrees of intelligence is a hot-spot but challenging issue. First, the question-solving abilities are interlaced with different ability branches like understanding and massive knowledge categories like mathematics. Second, the inputs of questions are multimodal that may involve text and images. Third, the response format of LLMs is diverse and thus poses great challenges for result extraction and evaluation. In this paper, we propose AGIBench -- a multi-granularity, multimodal, human-referenced, and auto-scoring benchmarking methodology for LLMs. Instead of a collection of blended questions, AGIBench focuses on three typical ability branches and adopts a four-tuple <ability branch, knowledge, difficulty, modal> to label the attributes of each question. First, it supports multi-granularity benchmarking, e.g., per-question, per-ability branch, per-knowledge, per-modal, per-dataset, and per-difficulty level granularities. Second, it contains multimodal input, including text and images. Third, it classifies all the questions into five degrees of difficulty according to the average accuracy rate of abundant educated humans (human-referenced). Fourth, it adopts zero-shot learning to avoid introducing additional unpredictability and provides an auto-scoring method to extract and judge the result. Finally, it defines multi-dimensional metrics, including accuracy under the average, worst, best, and majority voting cases, and repeatability. AGIBench is publically available from \url{https://www.benchcouncil.org/agibench}.