 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Rigorous and Cost-effective Clinical Trials for Artificial Intelligence Models
Jul 11, 2024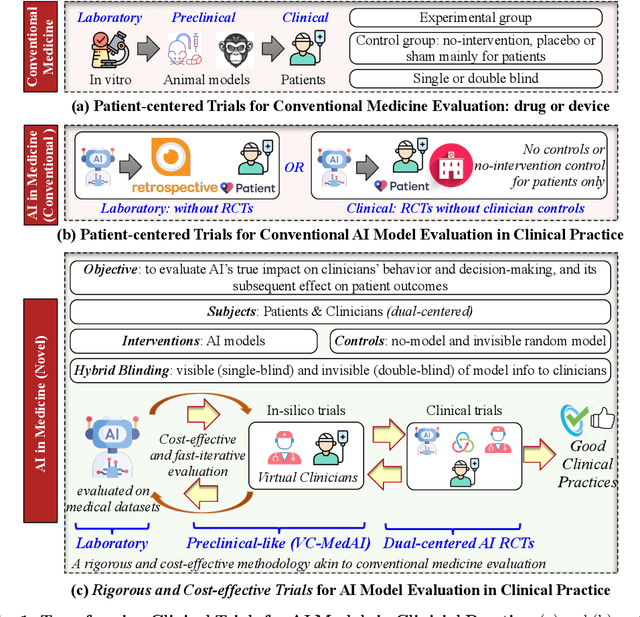
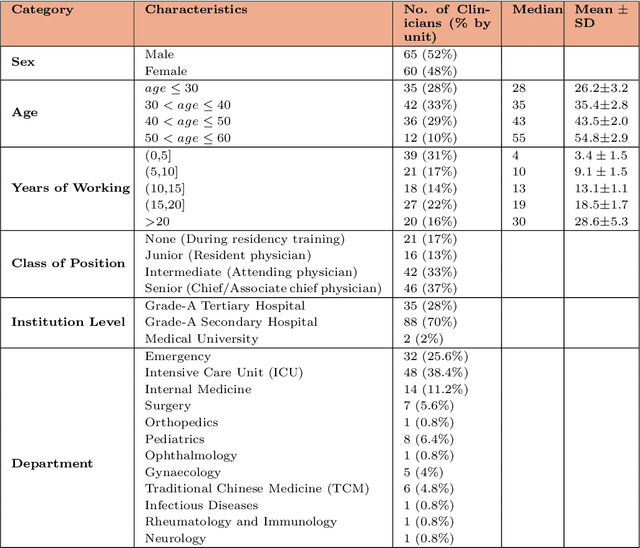
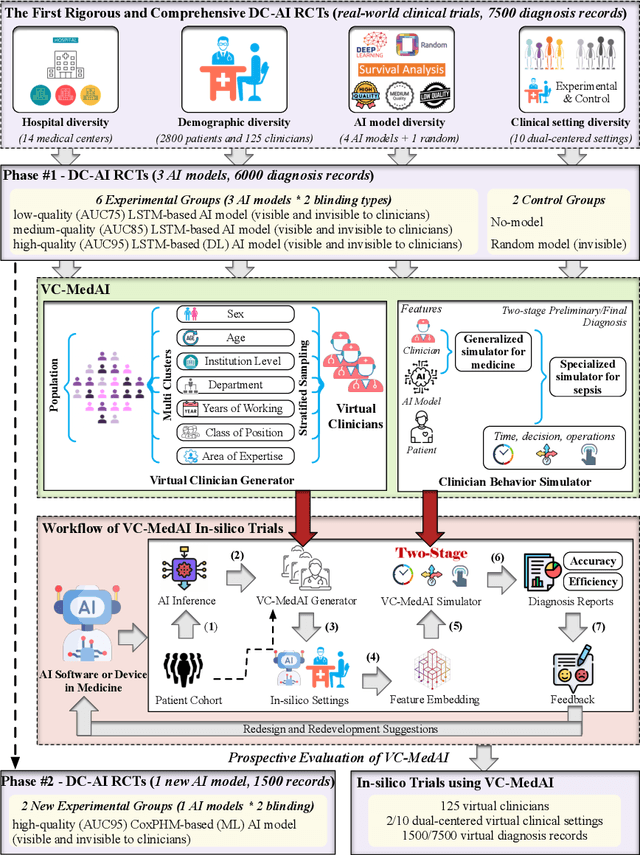
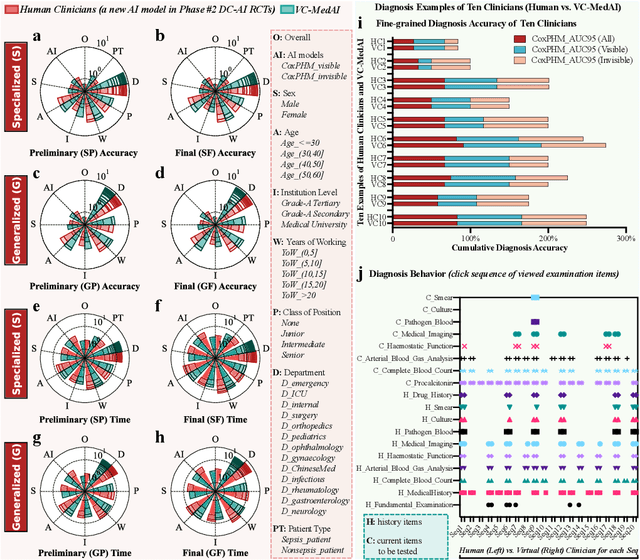
A profound gap persists between artificial intelligence (AI) and clinical practice in medicine, primarily due to the lack of rigorous and cost-effective evaluation methodologies. State-of-the-art and state-of-the-practice AI model evaluations are limited to laboratory studies on medical datasets or direct clinical trials with no or solely patient-centered controls. Moreover, the crucial role of clinicians in collaborating with AI, pivotal for determining its impact on clinical practice, is often overlooked. For the first time, we emphasize the critical necessity for rigorous and cost-effective evaluation methodologies for AI models in clinical practice, featuring patient/clinician-centered (dual-centered) AI randomized controlled trials (DC-AI RCTs) and virtual clinician-based in-silico trials (VC-MedAI) as an effective proxy for DC-AI RCTs. Leveraging 7500 diagnosis records from two-phase inaugural DC-AI RCTs across 14 medical centers with 125 clinicians, our results demonstrate the necessity of DC-AI RCTs and the effectiveness of VC-MedAI. Notably, VC-MedAI performs comparably to human clinicians, replicating insights and conclusions from prospective DC-AI RCTs. We envision DC-AI RCTs and VC-MedAI as pivotal advancements, presenting innovative and transformative evaluation methodologies for AI models in clinical practice, offering a preclinical-like setting mirroring conventional medicine, and reshaping development paradigms in a cost-effective and fast-iterative manner. Chinese Clinical Trial Registration: ChiCTR2400086816.
Younger: The First Dataset for Artificial Intelligence-Generated Neural Network Architecture
Jun 20, 2024



Designing and optimizing neural network architectures typically requires extensive expertise, starting with handcrafted designs and then manual or automated refinement. This dependency presents a significant barrier to rapid innovation. Recognizing the complexity of automatically generating neural network architecture from scratch, we introduce Younger, a pioneering dataset to advance this ambitious goal. Derived from over 174K real-world models across more than 30 tasks from various public model hubs, Younger includes 7,629 unique architectures, and each is represented as a directed acyclic graph with detailed operator-level information. The dataset facilitates two primary design paradigms: global, for creating complete architectures from scratch, and local, for detailed architecture component refinement. By establishing these capabilities, Younger contributes to a new frontier, Artificial Intelligence-Generated Neural Network Architecture (AIGNNA). Our experiments explore the potential and effectiveness of Younger for automated architecture generation and, as a secondary benefit, demonstrate that Younger can serve as a benchmark dataset, advancing the development of graph neural networks. We release the dataset and code publicly to lower the entry barriers and encourage further research in this challenging area.
OpenAPMax: Abnormal Patterns-based Model for Real-World Alzheimer's Disease Diagnosis
Jul 03, 2023



Alzheimer's disease (AD) cannot be reversed, but early diagnosis will significantly benefit patients' medical treatment and care. In recent works, AD diagnosis has the primary assumption that all categories are known a prior -- a closed-set classification problem, which contrasts with the open-set recognition problem. This assumption hinders the application of the model in natural clinical settings. Although many open-set recognition technologies have been proposed in other fields, they are challenging to use for AD diagnosis directly since 1) AD is a degenerative disease of the nervous system with similar symptoms at each stage, and it is difficult to distinguish from its pre-state, and 2) diversified strategies for AD diagnosis are challenging to model uniformly. In this work, inspired by the concerns of clinicians during diagnosis, we propose an open-set recognition model, OpenAPMax, based on the anomaly pattern to address AD diagnosis in real-world settings. OpenAPMax first obtains the abnormal pattern of each patient relative to each known category through statistics or a literature search, clusters the patients' abnormal pattern, and finally, uses extreme value theory (EVT) to model the distance between each patient's abnormal pattern and the center of their category and modify the classification probability. We evaluate the performance of the proposed method with recent open-set recognition, where we obtain state-of-the-art results.
OpenClinicalAI: An Open and Dynamic Model for Alzheimer's Disease Diagnosis
Jul 03, 2023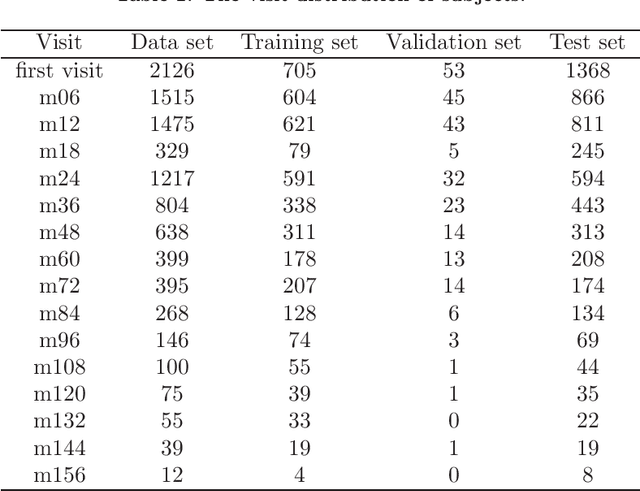
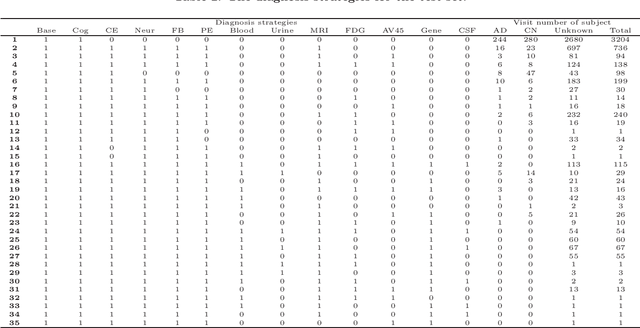
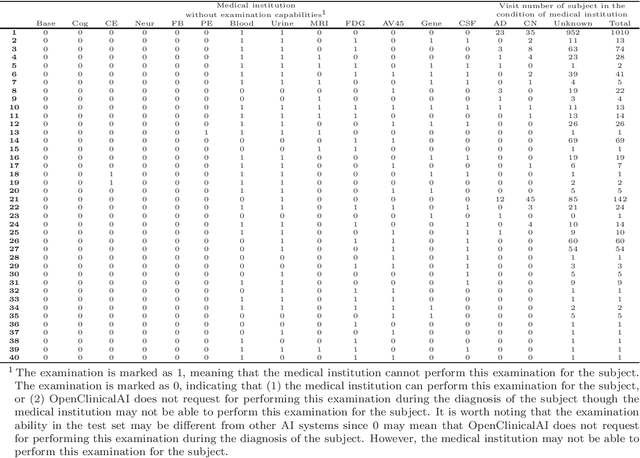
Although Alzheimer's disease (AD) cannot be reversed or cured, timely diagnosis can significantly reduce the burden of treatment and care. Current research on AD diagnosis models usually regards the diagnosis task as a typical classification task with two primary assumptions: 1) All target categories are known a priori; 2) The diagnostic strategy for each patient is consistent, that is, the number and type of model input data for each patient are the same. However, real-world clinical settings are open, with complexity and uncertainty in terms of both subjects and the resources of the medical institutions. This means that diagnostic models may encounter unseen disease categories and need to dynamically develop diagnostic strategies based on the subject's specific circumstances and available medical resources. Thus, the AD diagnosis task is tangled and coupled with the diagnosis strategy formulation. To promote the application of diagnostic systems in real-world clinical settings, we propose OpenClinicalAI for direct AD diagnosis in complex and uncertain clinical settings. This is the first powerful end-to-end model to dynamically formulate diagnostic strategies and provide diagnostic results based on the subject's conditions and available medical resources. OpenClinicalAI combines reciprocally coupled deep multiaction reinforcement learning (DMARL) for diagnostic strategy formulation and multicenter meta-learning (MCML) for open-set recognition. The experimental results show that OpenClinicalAI achieves better performance and fewer clinical examinations than the state-of-the-art model. Our method provides an opportunity to embed the AD diagnostic system into the current health care system to cooperate with clinicians to improve current health care.
OpenClinicalAI: enabling AI to diagnose diseases in real-world clinical settings
Sep 09, 2021This paper quantitatively reveals the state-of-the-art and state-of-the-practice AI systems only achieve acceptable performance on the stringent conditions that all categories of subjects are known, which we call closed clinical settings, but fail to work in real-world clinical settings. Compared to the diagnosis task in the closed setting, real-world clinical settings pose severe challenges, and we must treat them differently. We build a clinical AI benchmark named Clinical AIBench to set up real-world clinical settings to facilitate researches. We propose an open, dynamic machine learning framework and develop an AI system named OpenClinicalAI to diagnose diseases in real-world clinical settings. The first versions of Clinical AIBench and OpenClinicalAI target Alzheimer's disease. In the real-world clinical setting, OpenClinicalAI significantly outperforms the state-of-the-art AI system. In addition, OpenClinicalAI develops personalized diagnosis strategies to avoid unnecessary testing and seamlessly collaborates with clinicians. It is promising to be embedded in the current medical systems to improve medical services.
An Isolated Data Island Benchmark Suite for Federated Learning
Aug 17, 2020
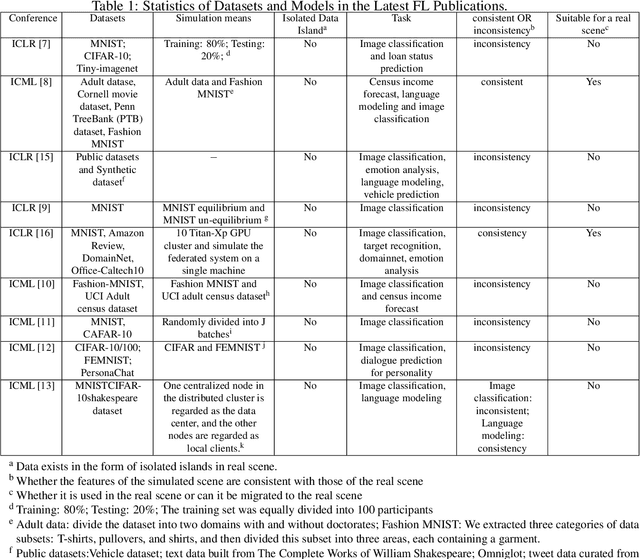
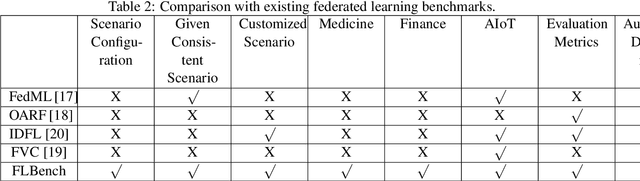
Federated learning (FL) is a new machine learning paradigm, the goal of which is to build a machine learning model based on data sets distributed on multiple devices--so called Isolated Data Island--while keeping their data secure and private. Most existing work manually splits commonly-used public datasets into partitions to simulate real-world Isolated Data Island while failing to capture the intrinsic characteristics of real-world domain data, like medicine, finance or AIoT. To bridge this huge gap, this paper presents and characterizes an Isolated Data Island benchmark suite, named FLBench, for benchmarking federated learning algorithms. FLBench contains three domains: medical, financial and AIoT. By configuring various domains, FLBench is qualified for evaluating the important research aspects of federated learning, and hence become a promising platform for developing novel federated learning algorithms. Finally, FLBench is fully open-sourced and in fast-evolution. We package it as an automated deployment tool. The benchmark suite will be publicly available from http://www.benchcouncil.org/FLBench.
AIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
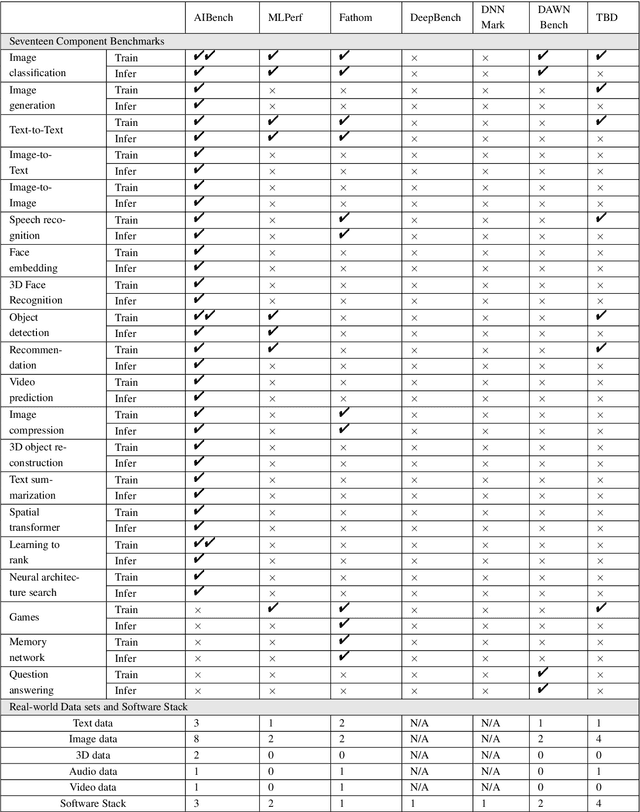
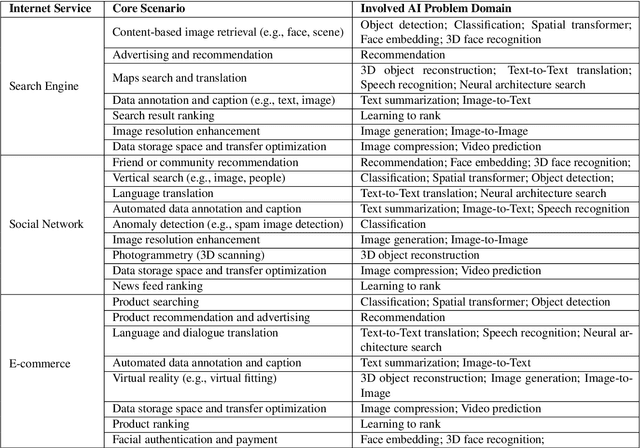
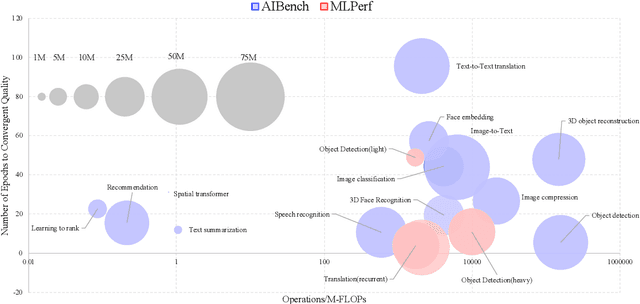
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020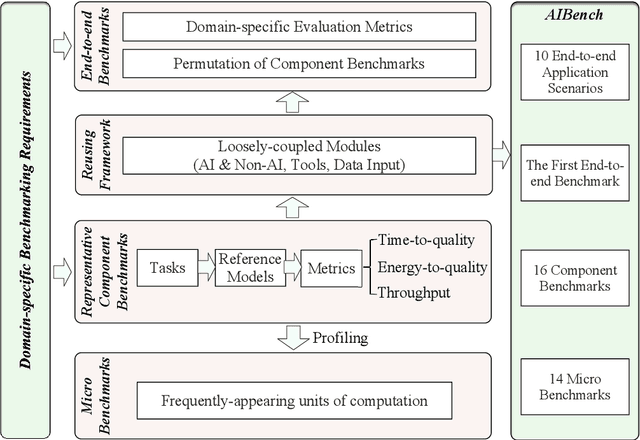
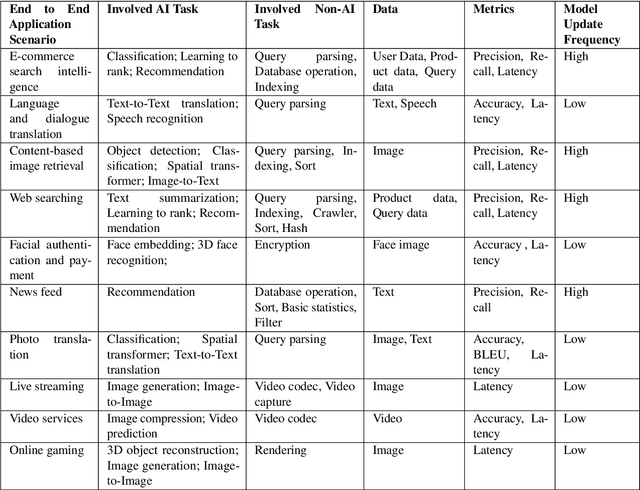

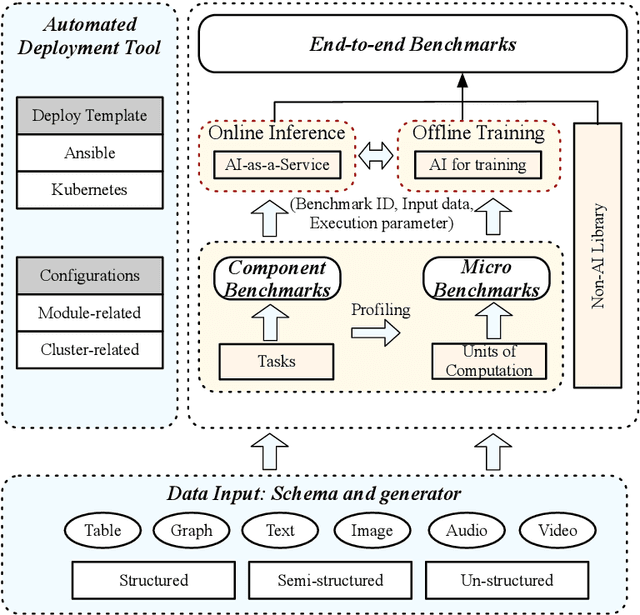
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.
AIBench: An Industry Standard Internet Service AI Benchmark Suite
Aug 13, 2019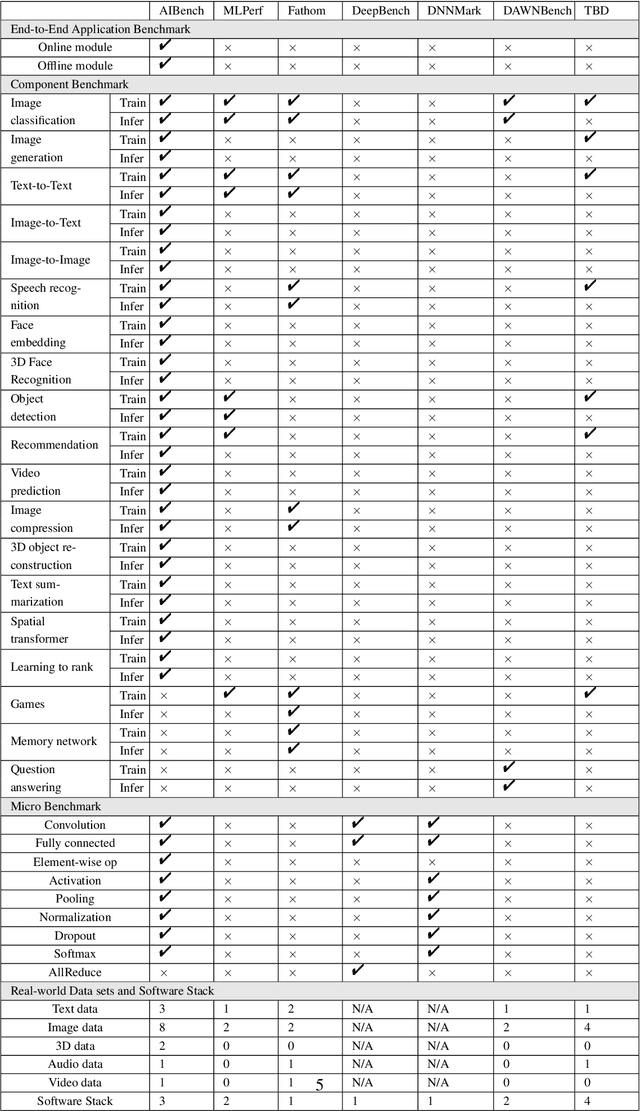
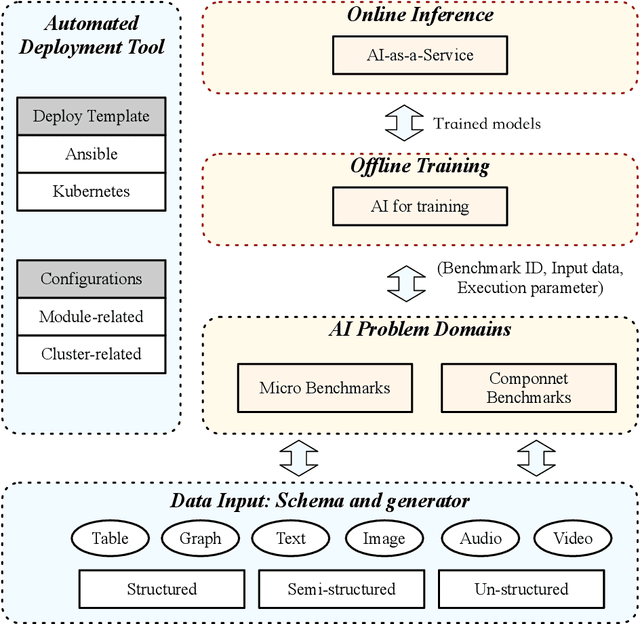
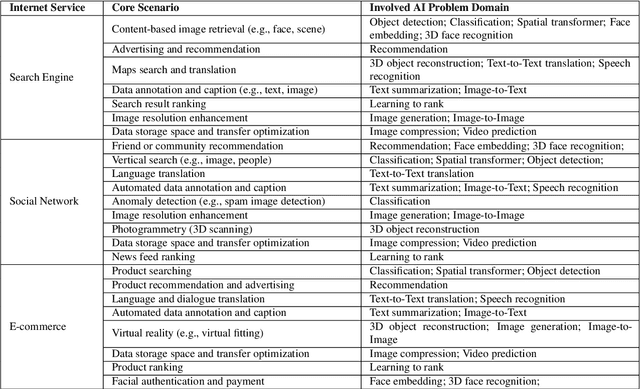
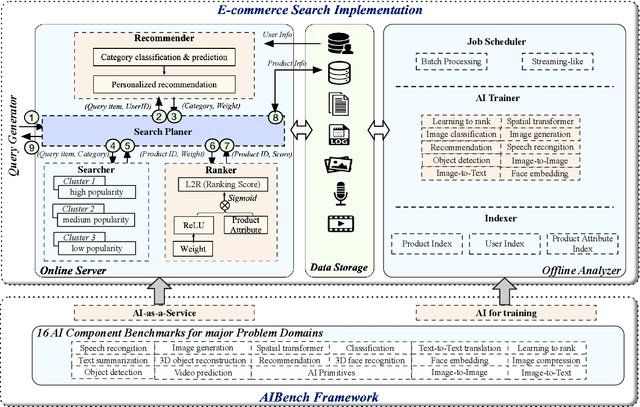
Today's Internet Services are undergoing fundamental changes and shifting to an intelligent computing era where AI is widely employed to augment services. In this context, many innovative AI algorithms, systems, and architectures are proposed, and thus the importance of benchmarking and evaluating them rises. However, modern Internet services adopt a microservice-based architecture and consist of various modules. The diversity of these modules and complexity of execution paths, the massive scale and complex hierarchy of datacenter infrastructure, the confidential issues of data sets and workloads pose great challenges to benchmarking. In this paper, we present the first industry-standard Internet service AI benchmark suite---AIBench with seventeen industry partners, including several top Internet service providers. AIBench provides a highly extensible, configurable, and flexible benchmark framework that contains loosely coupled modules. We identify sixteen prominent AI problem domains like learning to rank, each of which forms an AI component benchmark, from three most important Internet service domains: search engine, social network, and e-commerce, which is by far the most comprehensive AI benchmarking effort. On the basis of the AIBench framework, abstracting the real-world data sets and workloads from one of the top e-commerce providers, we design and implement the first end-to-end Internet service AI benchmark, which contains the primary modules in the critical paths of an industry scale application and is scalable to deploy on different cluster scales. The specifications, source code, and performance numbers are publicly available from the benchmark council web site http://www.benchcouncil.org/AIBench/index.html.
LoadCNN: A Efficient Green Deep Learning Model for Day-ahead Individual Resident Load Forecasting
Aug 01, 2019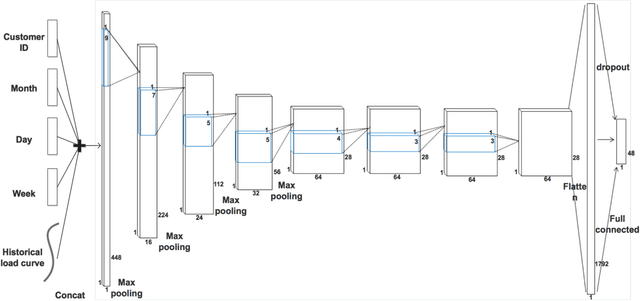
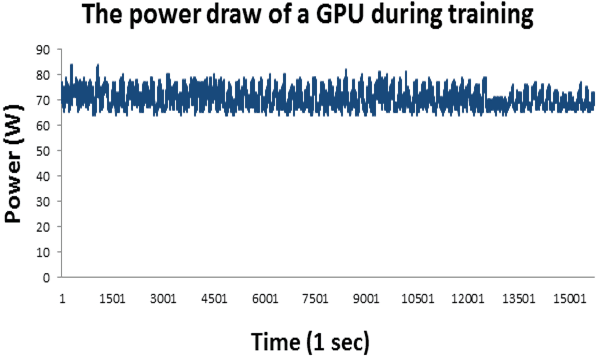
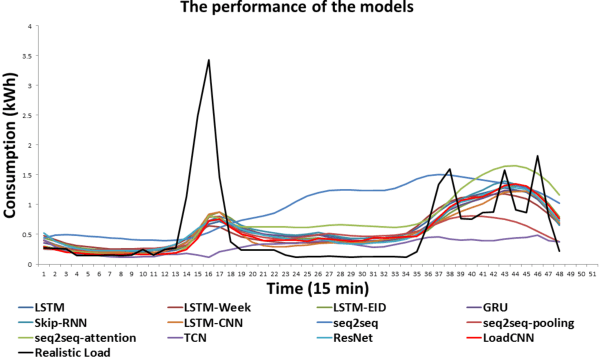
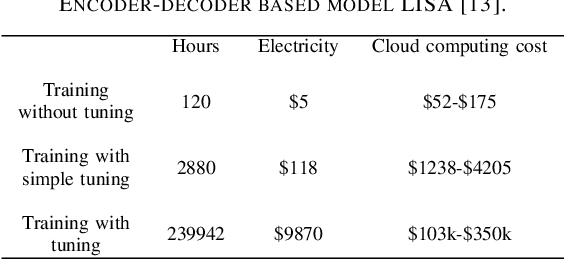
Accurate day-ahead individual resident load forecasting is very important to various applications of smart grid. As a powerful machine learning technology, deep learning has shown great advantages in load forecasting task. However, deep learning is a computationally-hungry method, requires a plenty of training time and results in considerable energy consumed and a plenty of CO2 emitted. This aggravates the energy crisis and incurs a substantial cost to the environment. As a result, the deep learning methods are difficult to be popularized and applied in the real smart grid environment. In this paper, to reduce training time, energy consumed and CO2 emitted, we propose a efficient green model based on convolutional neural network, namely LoadCNN, for next-day load forecasting of individual resident. The training time, energy consumption, and CO2 emissions of LoadCNN are only approximately 1/70 of the corresponding indicators of other state-of-the-art models. Meanwhile, it achieves state-of-the-art performance in terms of prediction accuracy. LoadCNN is the first load forecasting model which simultaneously considers prediction accuracy, training time, energy efficiency and environment costs. It is a efficient green model that is able to be quickly, cost-effectively and environmental-friendly deployed in a realistic smart grid environment.