 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
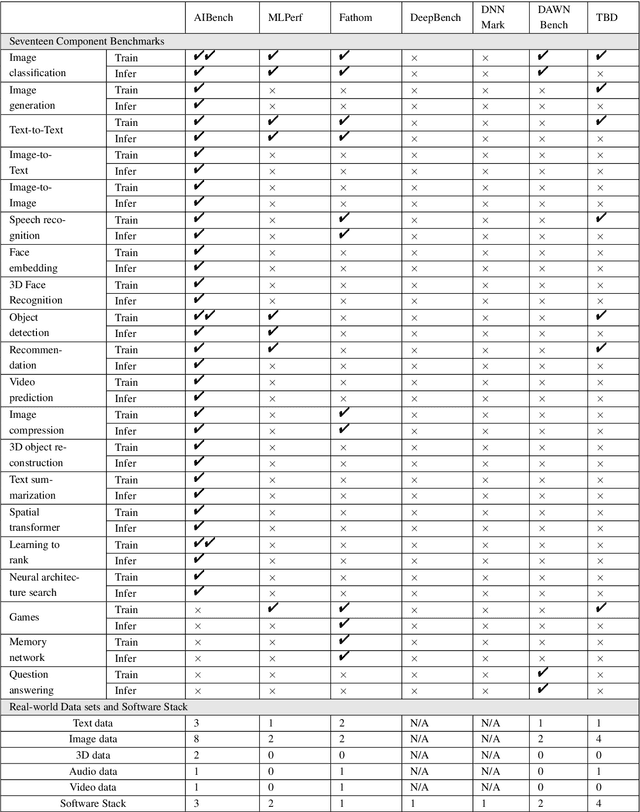
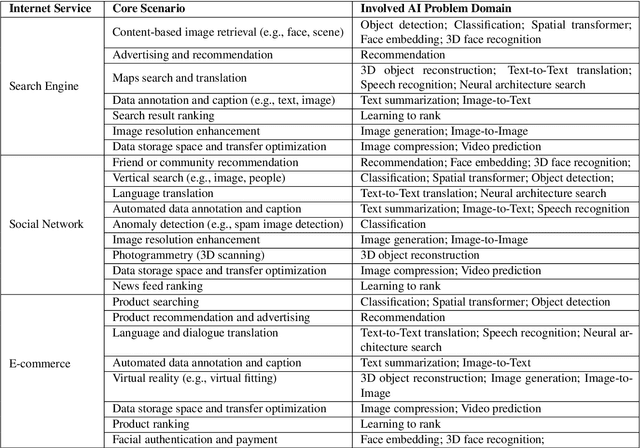
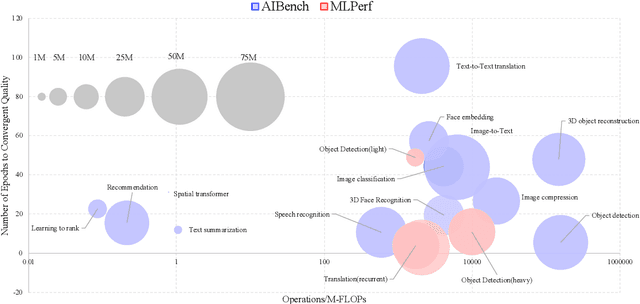
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
HPC AI500: A Benchmark Suite for HPC AI Systems
Aug 13, 2019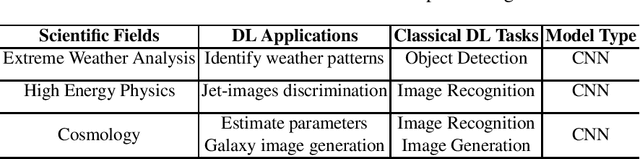
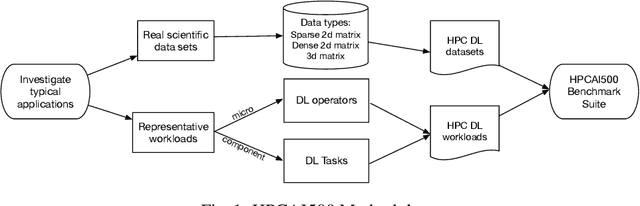

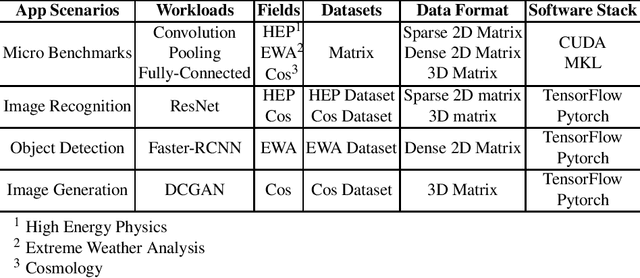
In recent years, with the trend of applying deep learning (DL) in high performance scientific computing, the unique characteristics of emerging DL workloads in HPC raise great challenges in designing, implementing HPC AI systems. The community needs a new yard stick for evaluating the future HPC systems. In this paper, we propose HPC AI500 --- a benchmark suite for evaluating HPC systems that running scientific DL workloads. Covering the most representative scientific fields, each workload from HPC AI500 is based on real-world scientific DL applications. Currently, we choose 14 scientific DL benchmarks from perspectives of application scenarios, data sets, and software stack. We propose a set of metrics for comprehensively evaluating the HPC AI systems, considering both accuracy, performance as well as power and cost. We provide a scalable reference implementation of HPC AI500. HPC AI500 is a part of the open-source AIBench project, the specification and source code are publicly available from \url{http://www.benchcouncil.org/AIBench/index.html}.
A Semantic-based Medical Image Fusion Approach
Jun 01, 2019
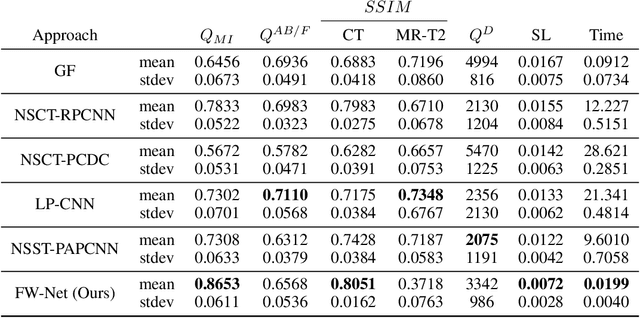

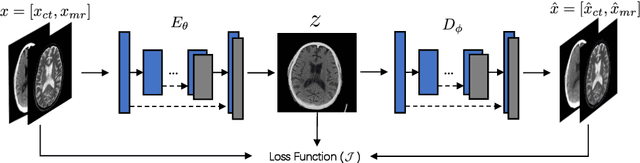
It is necessary for clinicians to comprehensively analyze patient information from different sources. Medical image fusion is a promising approach to providing overall information from medical images of different modalities. However, existing medical image fusion approaches ignore the semantics of images, making the fused image difficult to understand. In this paper, we put forward a semantic-based medical image fusion methodology, and as an implementation, we propose a Fusion W-Net (FW-Net) for multimodal medical image fusion. The experimental results are promising: the fused image generated by our approach greatly reduces the semantic information loss, and has comparable visual effects in contrast to the state-of-art approaches. Our approach and tool have great potential to be applied in the clinical setting. The source code of FW-Net is available at https://github.com/fanfanda/Medical-Image-Fusion.