 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAIROS: Unified Training for Universal Non-Autoregressive Time Series Forecasting
Oct 02, 2025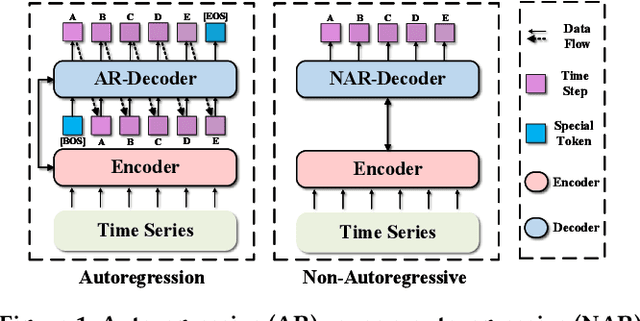

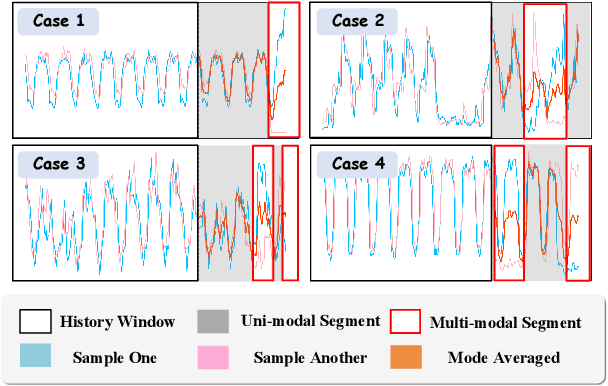
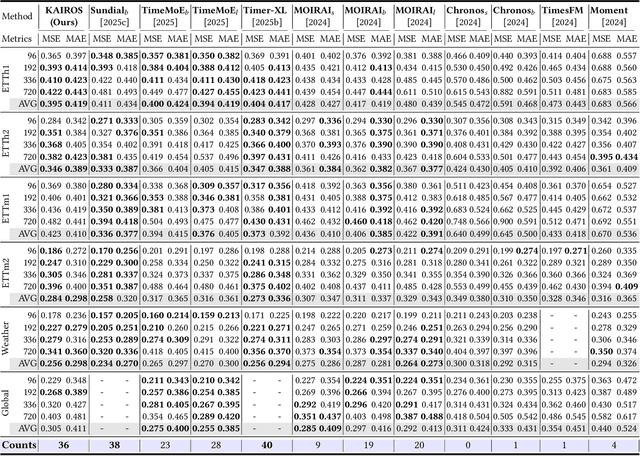
In the World Wide Web, reliable time series forecasts provide the forward-looking signals that drive resource planning, cache placement, and anomaly response, enabling platforms to operate efficiently as user behavior and content distributions evolve. Compared with other domains, time series forecasting for Web applications requires much faster responsiveness to support real-time decision making. We present KAIROS, a non-autoregressive time series forecasting framework that directly models segment-level multi-peak distributions. Unlike autoregressive approaches, KAIROS avoids error accumulation and achieves just-in-time inference, while improving over existing non-autoregressive models that collapse to over-smoothed predictions. Trained on the large-scale corpus, KAIROS demonstrates strong zero-shot generalization on six widely used benchmarks, delivering forecasting performance comparable to state-of-the-art foundation models with similar scale, at a fraction of their inference cost. Beyond empirical results, KAIROS highlights the importance of non-autoregressive design as a scalable paradigm for foundation models in time series.
DualSG: A Dual-Stream Explicit Semantic-Guided Multivariate Time Series Forecasting Framework
Jul 30, 2025



Multivariate Time Series Forecasting plays a key role in many applications. Recent works have explored using Large Language Models for MTSF to take advantage of their reasoning abilities. However, many methods treat LLMs as end-to-end forecasters, which often leads to a loss of numerical precision and forces LLMs to handle patterns beyond their intended design. Alternatively, methods that attempt to align textual and time series modalities within latent space frequently encounter alignment difficulty. In this paper, we propose to treat LLMs not as standalone forecasters, but as semantic guidance modules within a dual-stream framework. We propose DualSG, a dual-stream framework that provides explicit semantic guidance, where LLMs act as Semantic Guides to refine rather than replace traditional predictions. As part of DualSG, we introduce Time Series Caption, an explicit prompt format that summarizes trend patterns in natural language and provides interpretable context for LLMs, rather than relying on implicit alignment between text and time series in the latent space. We also design a caption-guided fusion module that explicitly models inter-variable relationships while reducing noise and computation. Experiments on real-world datasets from diverse domains show that DualSG consistently outperforms 15 state-of-the-art baselines, demonstrating the value of explicitly combining numerical forecasting with semantic guidance.
Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation
Mar 05, 2024



Image-to-video (I2V) generation tasks always suffer from keeping high fidelity in the open domains. Traditional image animation techniques primarily focus on specific domains such as faces or human poses, making them difficult to generalize to open domains. Several recent I2V frameworks based on diffusion models can generate dynamic content for open domain images but fail to maintain fidelity. We found that two main factors of low fidelity are the loss of image details and the noise prediction biases during the denoising process. To this end, we propose an effective method that can be applied to mainstream video diffusion models. This method achieves high fidelity based on supplementing more precise image information and noise rectification. Specifically, given a specified image, our method first adds noise to the input image latent to keep more details, then denoises the noisy latent with proper rectification to alleviate the noise prediction biases. Our method is tuning-free and plug-and-play. The experimental results demonstrate the effectiveness of our approach in improving the fidelity of generated videos. For more image-to-video generated results, please refer to the project website: https://noise-rectification.github.io.
AIGCBench: Comprehensive Evaluation of Image-to-Video Content Generated by AI
Jan 08, 2024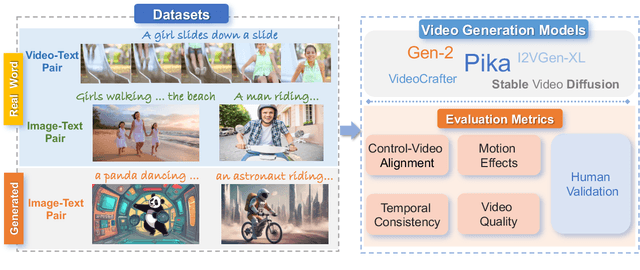
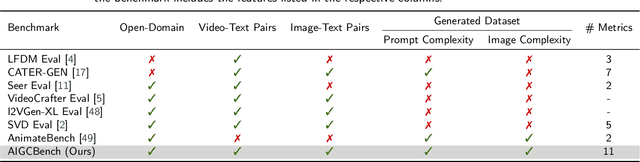
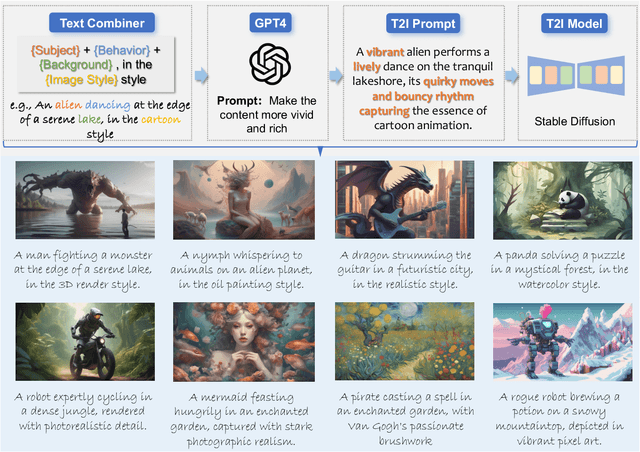
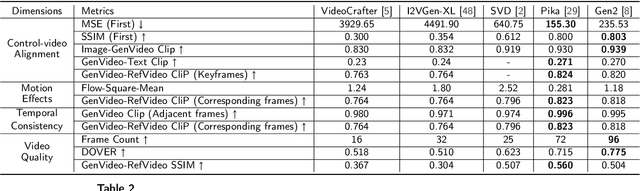
The burgeoning field of Artificial Intelligence Generated Content (AIGC) is witnessing rapid advancements, particularly in video generation. This paper introduces AIGCBench, a pioneering comprehensive and scalable benchmark designed to evaluate a variety of video generation tasks, with a primary focus on Image-to-Video (I2V) generation. AIGCBench tackles the limitations of existing benchmarks, which suffer from a lack of diverse datasets, by including a varied and open-domain image-text dataset that evaluates different state-of-the-art algorithms under equivalent conditions. We employ a novel text combiner and GPT-4 to create rich text prompts, which are then used to generate images via advanced Text-to-Image models. To establish a unified evaluation framework for video generation tasks, our benchmark includes 11 metrics spanning four dimensions to assess algorithm performance. These dimensions are control-video alignment, motion effects, temporal consistency, and video quality. These metrics are both reference video-dependent and video-free, ensuring a comprehensive evaluation strategy. The evaluation standard proposed correlates well with human judgment, providing insights into the strengths and weaknesses of current I2V algorithms. The findings from our extensive experiments aim to stimulate further research and development in the I2V field. AIGCBench represents a significant step toward creating standardized benchmarks for the broader AIGC landscape, proposing an adaptable and equitable framework for future assessments of video generation tasks. We have open-sourced the dataset and evaluation code on the project website: https://www.benchcouncil.org/AIGCBench.
Hierarchical Masked 3D Diffusion Model for Video Outpainting
Sep 05, 2023


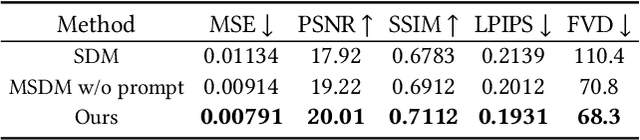
Video outpainting aims to adequately complete missing areas at the edges of video frames. Compared to image outpainting, it presents an additional challenge as the model should maintain the temporal consistency of the filled area. In this paper, we introduce a masked 3D diffusion model for video outpainting. We use the technique of mask modeling to train the 3D diffusion model. This allows us to use multiple guide frames to connect the results of multiple video clip inferences, thus ensuring temporal consistency and reducing jitter between adjacent frames. Meanwhile, we extract the global frames of the video as prompts and guide the model to obtain information other than the current video clip using cross-attention. We also introduce a hybrid coarse-to-fine inference pipeline to alleviate the artifact accumulation problem. The existing coarse-to-fine pipeline only uses the infilling strategy, which brings degradation because the time interval of the sparse frames is too large. Our pipeline benefits from bidirectional learning of the mask modeling and thus can employ a hybrid strategy of infilling and interpolation when generating sparse frames. Experiments show that our method achieves state-of-the-art results in video outpainting tasks. More results are provided at our https://fanfanda.github.io/M3DDM/.
AIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
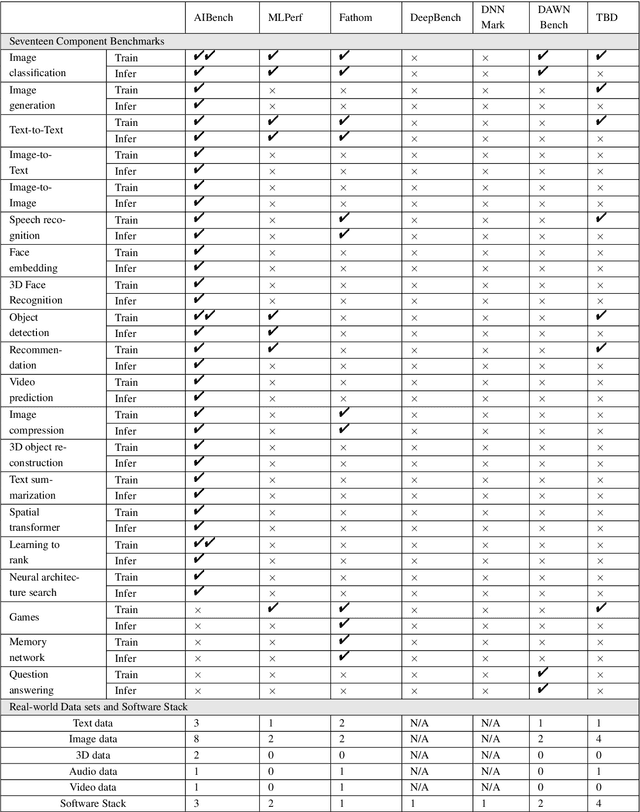
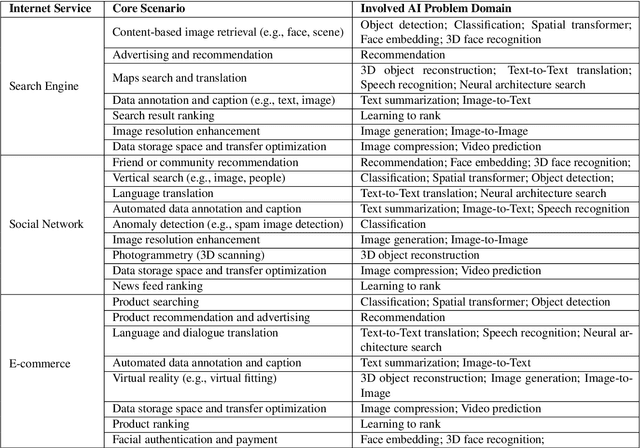
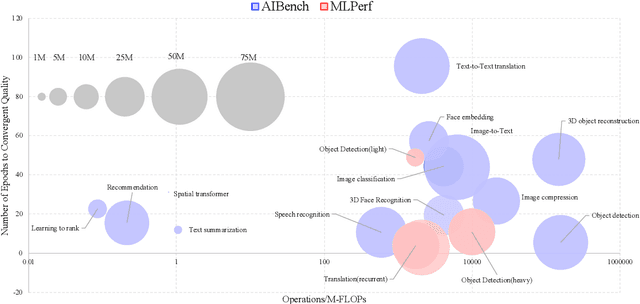
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020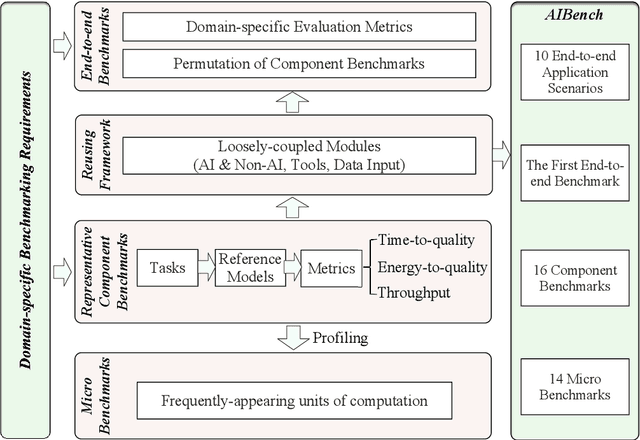
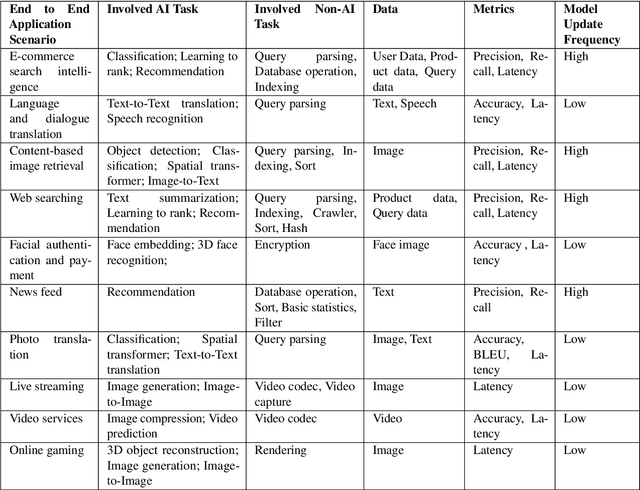

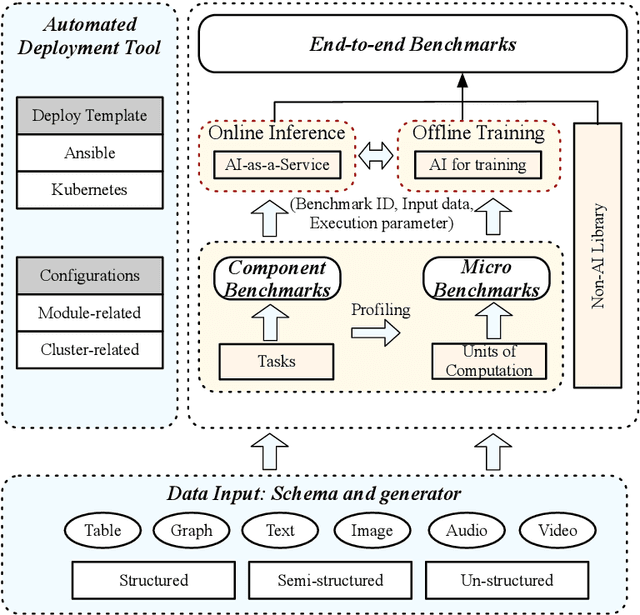
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.
A Semantic-based Medical Image Fusion Approach
Jun 01, 2019
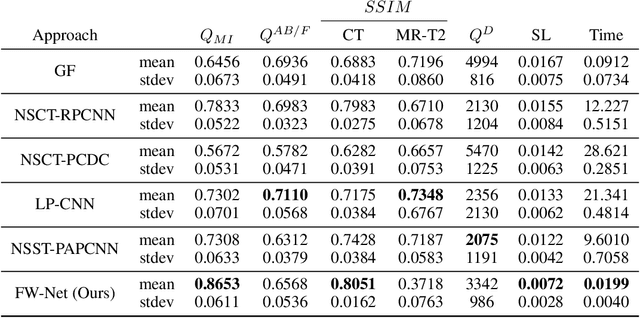

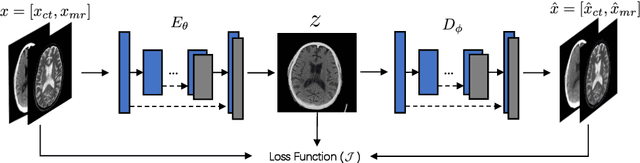
It is necessary for clinicians to comprehensively analyze patient information from different sources. Medical image fusion is a promising approach to providing overall information from medical images of different modalities. However, existing medical image fusion approaches ignore the semantics of images, making the fused image difficult to understand. In this paper, we put forward a semantic-based medical image fusion methodology, and as an implementation, we propose a Fusion W-Net (FW-Net) for multimodal medical image fusion. The experimental results are promising: the fused image generated by our approach greatly reduces the semantic information loss, and has comparable visual effects in contrast to the state-of-art approaches. Our approach and tool have great potential to be applied in the clinical setting. The source code of FW-Net is available at https://github.com/fanfanda/Medical-Image-Fusion.