 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISE-T2V: Rephrasing and Injecting Semantics with LLM for Expansive Text-to-Video Generation
Nov 06, 2025Most text-to-video(T2V) diffusion models depend on pre-trained text encoders for semantic alignment, yet they often fail to maintain video quality when provided with concise prompts rather than well-designed ones. The primary issue lies in their limited textual semantics understanding. Moreover, these text encoders cannot rephrase prompts online to better align with user intentions, which limits both the scalability and usability of the models, To address these challenges, we introduce RISE-T2V, which uniquely integrates the processes of prompt rephrasing and semantic feature extraction into a single and seamless step instead of two separate steps. RISE-T2V is universal and can be applied to various pre-trained LLMs and video diffusion models(VDMs), significantly enhancing their capabilities for T2V tasks. We propose an innovative module called the Rephrasing Adapter, enabling diffusion models to utilize text hidden states during the next token prediction of the LLM as a condition for video generation. By employing a Rephrasing Adapter, the video generation model can implicitly rephrase basic prompts into more comprehensive representations that better match the user's intent. Furthermore, we leverage the powerful capabilities of LLMs to enable video generation models to accomplish a broader range of T2V tasks. Extensive experiments demonstrate that RISE-T2V is a versatile framework applicable to different video diffusion model architectures, significantly enhancing the ability of T2V models to generate high-quality videos that align with user intent. Visual results are available on the webpage at https://rise-t2v.github.io.
Enhancing Taobao Display Advertising with Multimodal Representations: Challenges, Approaches and Insights
Jul 28, 2024



Despite the recognized potential of multimodal data to improve model accuracy, many large-scale industrial recommendation systems, including Taobao display advertising system, predominantly depend on sparse ID features in their models. In this work, we explore approaches to leverage multimodal data to enhance the recommendation accuracy. We start from identifying the key challenges in adopting multimodal data in a manner that is both effective and cost-efficient for industrial systems. To address these challenges, we introduce a two-phase framework, including: 1) the pre-training of multimodal representations to capture semantic similarity, and 2) the integration of these representations with existing ID-based models. Furthermore, we detail the architecture of our production system, which is designed to facilitate the deployment of multimodal representations. Since the integration of multimodal representations in mid-2023, we have observed significant performance improvements in Taobao display advertising system. We believe that the insights we have gathered will serve as a valuable resource for practitioners seeking to leverage multimodal data in their systems.
AtomoVideo: High Fidelity Image-to-Video Generation
Mar 05, 2024



Recently, video generation has achieved significant rapid development based on superior text-to-image generation techniques. In this work, we propose a high fidelity framework for image-to-video generation, named AtomoVideo. Based on multi-granularity image injection, we achieve higher fidelity of the generated video to the given image. In addition, thanks to high quality datasets and training strategies, we achieve greater motion intensity while maintaining superior temporal consistency and stability. Our architecture extends flexibly to the video frame prediction task, enabling long sequence prediction through iterative generation. Furthermore, due to the design of adapter training, our approach can be well combined with existing personalized models and controllable modules. By quantitatively and qualitatively evaluation, AtomoVideo achieves superior results compared to popular methods, more examples can be found on our project website: https://atomo-video.github.io/.
Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation
Mar 05, 2024



Image-to-video (I2V) generation tasks always suffer from keeping high fidelity in the open domains. Traditional image animation techniques primarily focus on specific domains such as faces or human poses, making them difficult to generalize to open domains. Several recent I2V frameworks based on diffusion models can generate dynamic content for open domain images but fail to maintain fidelity. We found that two main factors of low fidelity are the loss of image details and the noise prediction biases during the denoising process. To this end, we propose an effective method that can be applied to mainstream video diffusion models. This method achieves high fidelity based on supplementing more precise image information and noise rectification. Specifically, given a specified image, our method first adds noise to the input image latent to keep more details, then denoises the noisy latent with proper rectification to alleviate the noise prediction biases. Our method is tuning-free and plug-and-play. The experimental results demonstrate the effectiveness of our approach in improving the fidelity of generated videos. For more image-to-video generated results, please refer to the project website: https://noise-rectification.github.io.
Hierarchical Masked 3D Diffusion Model for Video Outpainting
Sep 05, 2023


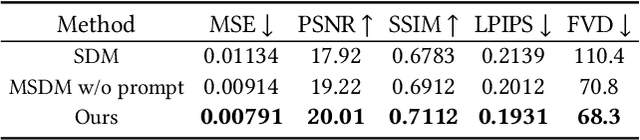
Video outpainting aims to adequately complete missing areas at the edges of video frames. Compared to image outpainting, it presents an additional challenge as the model should maintain the temporal consistency of the filled area. In this paper, we introduce a masked 3D diffusion model for video outpainting. We use the technique of mask modeling to train the 3D diffusion model. This allows us to use multiple guide frames to connect the results of multiple video clip inferences, thus ensuring temporal consistency and reducing jitter between adjacent frames. Meanwhile, we extract the global frames of the video as prompts and guide the model to obtain information other than the current video clip using cross-attention. We also introduce a hybrid coarse-to-fine inference pipeline to alleviate the artifact accumulation problem. The existing coarse-to-fine pipeline only uses the infilling strategy, which brings degradation because the time interval of the sparse frames is too large. Our pipeline benefits from bidirectional learning of the mask modeling and thus can employ a hybrid strategy of infilling and interpolation when generating sparse frames. Experiments show that our method achieves state-of-the-art results in video outpainting tasks. More results are provided at our https://fanfanda.github.io/M3DDM/.