 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIF: Asynchronous Inference Framework for Cost-Effective Pre-Ranking
Nov 17, 2025In industrial recommendation systems, pre-ranking models based on deep neural networks (DNNs) commonly adopt a sequential execution framework: feature fetching and model forward computation are triggered only after receiving candidates from the upstream retrieval stage. This design introduces inherent bottlenecks, including redundant computations of identical users/items and increased latency due to strictly sequential operations, which jointly constrain the model's capacity and system efficiency. To address these limitations, we propose the Asynchronous Inference Framework (AIF), a cost-effective computational architecture that decouples interaction-independent components, those operating within a single user or item, from real-time prediction. AIF reorganizes the model inference process by performing user-side computations in parallel with the retrieval stage and conducting item-side computations in a nearline manner. This means that interaction-independent components are calculated just once and completed before the real-time prediction phase of the pre-ranking stage. As a result, AIF enhances computational efficiency and reduces latency, freeing up resources to significantly improve the feature set and model architecture of interaction-independent components. Moreover, we delve into model design within the AIF framework, employing approximated methods for interaction-dependent components in online real-time predictions. By co-designing both the framework and the model, our solution achieves notable performance gains without significantly increasing computational and latency costs. This has enabled the successful deployment of AIF in the Taobao display advertising system.
Enhancing Taobao Display Advertising with Multimodal Representations: Challenges, Approaches and Insights
Jul 28, 2024



Despite the recognized potential of multimodal data to improve model accuracy, many large-scale industrial recommendation systems, including Taobao display advertising system, predominantly depend on sparse ID features in their models. In this work, we explore approaches to leverage multimodal data to enhance the recommendation accuracy. We start from identifying the key challenges in adopting multimodal data in a manner that is both effective and cost-efficient for industrial systems. To address these challenges, we introduce a two-phase framework, including: 1) the pre-training of multimodal representations to capture semantic similarity, and 2) the integration of these representations with existing ID-based models. Furthermore, we detail the architecture of our production system, which is designed to facilitate the deployment of multimodal representations. Since the integration of multimodal representations in mid-2023, we have observed significant performance improvements in Taobao display advertising system. We believe that the insights we have gathered will serve as a valuable resource for practitioners seeking to leverage multimodal data in their systems.
Calibration-compatible Listwise Distillation of Privileged Features for CTR Prediction
Dec 14, 2023



In machine learning systems, privileged features refer to the features that are available during offline training but inaccessible for online serving. Previous studies have recognized the importance of privileged features and explored ways to tackle online-offline discrepancies. A typical practice is privileged features distillation (PFD): train a teacher model using all features (including privileged ones) and then distill the knowledge from the teacher model using a student model (excluding the privileged features), which is then employed for online serving. In practice, the pointwise cross-entropy loss is often adopted for PFD. However, this loss is insufficient to distill the ranking ability for CTR prediction. First, it does not consider the non-i.i.d. characteristic of the data distribution, i.e., other items on the same page significantly impact the click probability of the candidate item. Second, it fails to consider the relative item order ranked by the teacher model's predictions, which is essential to distill the ranking ability. To address these issues, we first extend the pointwise-based PFD to the listwise-based PFD. We then define the calibration-compatible property of distillation loss and show that commonly used listwise losses do not satisfy this property when employed as distillation loss, thus compromising the model's calibration ability, which is another important measure for CTR prediction. To tackle this dilemma, we propose Calibration-compatible LIstwise Distillation (CLID), which employs carefully-designed listwise distillation loss to achieve better ranking ability than the pointwise-based PFD while preserving the model's calibration ability. We theoretically prove it is calibration-compatible. Extensive experiments on public datasets and a production dataset collected from the display advertising system of Alibaba further demonstrate the effectiveness of CLID.
Joint Optimization of Ranking and Calibration with Contextualized Hybrid Model
Aug 12, 2022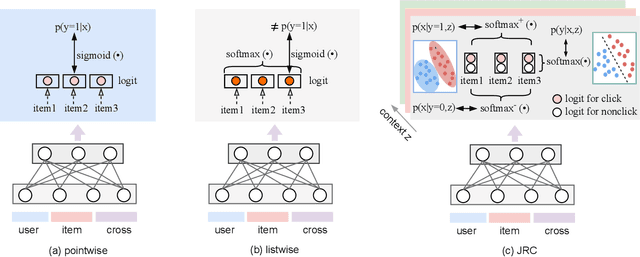
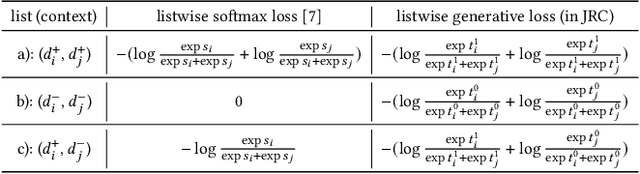

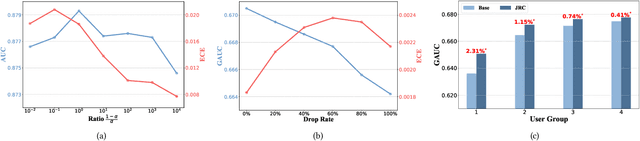
Despite the development of ranking optimization techniques, the pointwise model remains the dominating approach for click-through rate (CTR) prediction. It can be attributed to the calibration ability of the pointwise model since the prediction can be viewed as the click probability. In practice, a CTR prediction model is also commonly assessed with the ranking ability, for which prediction models based on ranking losses (e.g., pairwise or listwise loss) usually achieve better performances than the pointwise loss. Previous studies have experimented with a direct combination of the two losses to obtain the benefit from both losses and observed an improved performance. However, previous studies break the meaning of output logit as the click-through rate, which may lead to sub-optimal solutions. To address this issue, we propose an approach that can Jointly optimize the Ranking and Calibration abilities (JRC for short). JRC improves the ranking ability by contrasting the logit value for the sample with different labels and constrains the predicted probability to be a function of the logit subtraction. We further show that JRC consolidates the interpretation of logits, where the logits model the joint distribution. With such an interpretation, we prove that JRC approximately optimizes the contextualized hybrid discriminative-generative objective. Experiments on public and industrial datasets and online A/B testing show that our approach improves both ranking and calibration abilities. Since May 2022, JRC has been deployed on the display advertising platform of Alibaba and has obtained significant performance improvements.