 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration-compatible Listwise Distillation of Privileged Features for CTR Prediction
Dec 14, 2023



In machine learning systems, privileged features refer to the features that are available during offline training but inaccessible for online serving. Previous studies have recognized the importance of privileged features and explored ways to tackle online-offline discrepancies. A typical practice is privileged features distillation (PFD): train a teacher model using all features (including privileged ones) and then distill the knowledge from the teacher model using a student model (excluding the privileged features), which is then employed for online serving. In practice, the pointwise cross-entropy loss is often adopted for PFD. However, this loss is insufficient to distill the ranking ability for CTR prediction. First, it does not consider the non-i.i.d. characteristic of the data distribution, i.e., other items on the same page significantly impact the click probability of the candidate item. Second, it fails to consider the relative item order ranked by the teacher model's predictions, which is essential to distill the ranking ability. To address these issues, we first extend the pointwise-based PFD to the listwise-based PFD. We then define the calibration-compatible property of distillation loss and show that commonly used listwise losses do not satisfy this property when employed as distillation loss, thus compromising the model's calibration ability, which is another important measure for CTR prediction. To tackle this dilemma, we propose Calibration-compatible LIstwise Distillation (CLID), which employs carefully-designed listwise distillation loss to achieve better ranking ability than the pointwise-based PFD while preserving the model's calibration ability. We theoretically prove it is calibration-compatible. Extensive experiments on public datasets and a production dataset collected from the display advertising system of Alibaba further demonstrate the effectiveness of CLID.
Entire Space Cascade Delayed Feedback Modeling for Effective Conversion Rate Prediction
Aug 09, 2023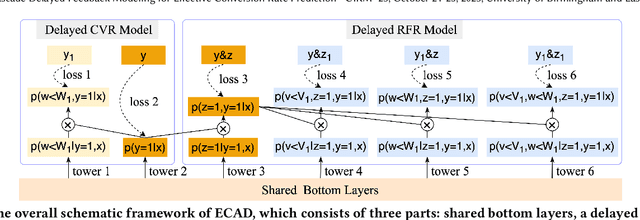
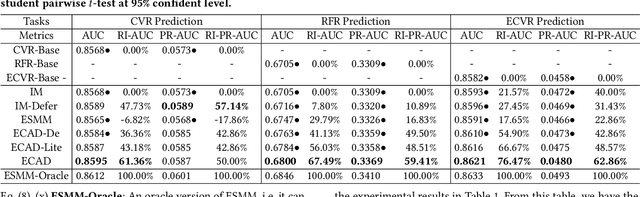
Conversion rate (CVR) prediction is an essential task for large-scale e-commerce platforms. However, refund behaviors frequently occur after conversion in online shopping systems, which drives us to pay attention to effective conversion for building healthier shopping services. This paper defines the probability of item purchasing without any subsequent refund as an effective conversion rate (ECVR). A simple paradigm for ECVR prediction is to decompose it into two sub-tasks: CVR prediction and post-conversion refund rate (RFR) prediction. However, RFR prediction suffers from data sparsity (DS) and sample selection bias (SSB) issues, as the refund behaviors are only available after user purchase. Furthermore, there is delayed feedback in both conversion and refund events and they are sequentially dependent, named cascade delayed feedback (CDF), which significantly harms data freshness for model training. Previous studies mainly focus on tackling DS and SSB or delayed feedback for a single event. To jointly tackle these issues in ECVR prediction, we propose an Entire space CAscade Delayed feedback modeling (ECAD) method. Specifically, ECAD deals with DS and SSB by constructing two tasks including CVR prediction and conversion \& refund rate (CVRFR) prediction using the entire space modeling framework. In addition, it carefully schedules auxiliary tasks to leverage both conversion and refund time within data to alleviate CDF. Experimental results on the offline industrial dataset and online A/B testing demonstrate the effectiveness of ECAD. In addition, ECAD has been deployed in one of the recommender systems in Alibaba, contributing to a significant improvement of ECVR.