 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRECTR-V2:Unified Relevance-CTR Framework with Cross-User Preference Mining, Exposure Bias Correction, and LLM-Distilled Encoder Optimization
Feb 24, 2026In search systems, effectively coordinating the two core objectives of search relevance matching and click-through rate (CTR) prediction is crucial for discovering users' interests and enhancing platform revenue. In our prior work PRECTR, we proposed a unified framework to integrate these two subtasks,thereby eliminating their inconsistency and leading to mutual benefit.However, our previous work still faces three main challenges. First, low-active users and new users have limited search behavioral data, making it difficult to achieve effective personalized relevance preference modeling. Second, training data for ranking models predominantly come from high-relevance exposures, creating a distribution mismatch with the broader candidate space in coarse-ranking, leading to generalization bias. Third, due to the latency constraint, the original model employs an Emb+MLP architecture with a frozen BERT encoder, which prevents joint optimization and creates misalignment between representation learning and CTR fine-tuning. To solve these issues, we further reinforce our method and propose PRECTR-V2. Specifically, we mitigate the low-activity users' sparse behavior problem by mining global relevance preferences under the specific query, which facilitates effective personalized relevance modeling for cold-start scenarios. Subsequently, we construct hard negative samples through embedding noise injection and relevance label reconstruction, and optimize their relative ranking against positive samples via pairwise loss, thereby correcting exposure bias. Finally, we pretrain a lightweight transformer-based encoder via knowledge distillation from LLM and SFT on the text relevance classification task. This encoder replaces the frozen BERT module, enabling better adaptation to CTR fine-tuning and advancing beyond the traditional Emb+MLP paradigm.
DAIAN: Deep Adaptive Intent-Aware Network for CTR Prediction in Trigger-Induced Recommendation
Feb 15, 2026Recommendation systems are essential for personalizing e-commerce shopping experiences. Among these, Trigger-Induced Recommendation (TIR) has emerged as a key scenario, which utilizes a trigger item (explicitly represents a user's instantaneous interest), enabling precise, real-time recommendations. Although several trigger-based techniques have been proposed, most of them struggle to address the intent myopia issue, that is, a recommendation system overemphasizes the role of trigger items and narrowly focuses on suggesting commodities that are highly relevant to trigger items. Meanwhile, existing methods rely on collaborative behavior patterns between trigger and recommended items to identify the user's preferences, yet the sparsity of ID-based interaction restricts their effectiveness. To this end, we propose the Deep Adaptive Intent-Aware Network (DAIAN) that dynamically adapts to users' intent preferences. In general, we first extract the users' personalized intent representations by analyzing the correlation between a user's click and the trigger item, and accordingly retrieve the user's related historical behaviors to mine the user's diverse intent. Besides, sparse collaborative behaviors constrain the performance in capturing items associated with user intent. Hence, we reinforce similarity by leveraging a hybrid enhancer with ID and semantic information, followed by adaptive selection based on varying intents. Experimental results on public datasets and our industrial e-commerce datasets demonstrate the effectiveness of DAIAN.
TACLR: A Scalable and Efficient Retrieval-based Method for Industrial Product Attribute Value Identification
Jan 07, 2025Product Attribute Value Identification (PAVI) involves identifying attribute values from product profiles, a key task for improving product search, recommendations, and business analytics on e-commerce platforms. However, existing PAVI methods face critical challenges, such as inferring implicit values, handling out-of-distribution (OOD) values, and producing normalized outputs. To address these limitations, we introduce Taxonomy-Aware Contrastive Learning Retrieval (TACLR), the first retrieval-based method for PAVI. TACLR formulates PAVI as an information retrieval task by encoding product profiles and candidate values into embeddings and retrieving values based on their similarity to the item embedding. It leverages contrastive training with taxonomy-aware hard negative sampling and employs adaptive inference with dynamic thresholds. TACLR offers three key advantages: (1) it effectively handles implicit and OOD values while producing normalized outputs; (2) it scales to thousands of categories, tens of thousands of attributes, and millions of values; and (3) it supports efficient inference for high-load industrial scenarios. Extensive experiments on proprietary and public datasets validate the effectiveness and efficiency of TACLR. Moreover, it has been successfully deployed in a real-world e-commerce platform, processing millions of product listings daily while supporting dynamic, large-scale attribute taxonomies.
IPL: Leveraging Multimodal Large Language Models for Intelligent Product Listing
Oct 22, 2024



Unlike professional Business-to-Consumer (B2C) e-commerce platforms (e.g., Amazon), Consumer-to-Consumer (C2C) platforms (e.g., Facebook marketplace) are mainly targeting individual sellers who usually lack sufficient experience in e-commerce. Individual sellers often struggle to compose proper descriptions for selling products. With the recent advancement of Multimodal Large Language Models (MLLMs), we attempt to integrate such state-of-the-art generative AI technologies into the product listing process. To this end, we develop IPL, an Intelligent Product Listing tool tailored to generate descriptions using various product attributes such as category, brand, color, condition, etc. IPL enables users to compose product descriptions by merely uploading photos of the selling product. More importantly, it can imitate the content style of our C2C platform Xianyu. This is achieved by employing domain-specific instruction tuning on MLLMs and adopting the multi-modal Retrieval-Augmented Generation (RAG) process. A comprehensive empirical evaluation demonstrates that the underlying model of IPL significantly outperforms the base model in domain-specific tasks while producing less hallucination. IPL has been successfully deployed in our production system, where 72% of users have their published product listings based on the generated content, and those product listings are shown to have a quality score 5.6% higher than those without AI assistance.
MetaSplit: Meta-Split Network for Limited-Stock Product Recommendation
Mar 16, 2024Compared to business-to-consumer (B2C) e-commerce systems, consumer-to-consumer (C2C) e-commerce platforms usually encounter the limited-stock problem, that is, a product can only be sold one time in a C2C system. This poses several unique challenges for click-through rate (CTR) prediction. Due to limited user interactions for each product (i.e. item), the corresponding item embedding in the CTR model may not easily converge. This makes the conventional sequence modeling based approaches cannot effectively utilize user history information since historical user behaviors contain a mixture of items with different volume of stocks. Particularly, the attention mechanism in a sequence model tends to assign higher score to products with more accumulated user interactions, making limited-stock products being ignored and contribute less to the final output. To this end, we propose the Meta-Split Network (MSNet) to split user history sequence regarding to the volume of stock for each product, and adopt differentiated modeling approaches for different sequences. As for the limited-stock products, a meta-learning approach is applied to address the problem of inconvergence, which is achieved by designing meta scaling and shifting networks with ID and side information. In addition, traditional approach can hardly update item embedding once the product is consumed. Thereby, we propose an auxiliary loss that makes the parameters updatable even when the product is no longer in distribution. To the best of our knowledge, this is the first solution addressing the recommendation of limited-stock product. Experimental results on the production dataset and online A/B testing demonstrate the effectiveness of our proposed method.
Effective Two-Stage Knowledge Transfer for Multi-Entity Cross-Domain Recommendation
Feb 29, 2024



In recent years, the recommendation content on e-commerce platforms has become increasingly rich -- a single user feed may contain multiple entities, such as selling products, short videos, and content posts. To deal with the multi-entity recommendation problem, an intuitive solution is to adopt the shared-network-based architecture for joint training. The idea is to transfer the extracted knowledge from one type of entity (source entity) to another (target entity). However, different from the conventional same-entity cross-domain recommendation, multi-entity knowledge transfer encounters several important issues: (1) data distributions of the source entity and target entity are naturally different, making the shared-network-based joint training susceptible to the negative transfer issue, (2) more importantly, the corresponding feature schema of each entity is not exactly aligned (e.g., price is an essential feature for selling product while missing for content posts), making the existing methods no longer appropriate. Recent researchers have also experimented with the pre-training and fine-tuning paradigm. Again, they only consider the scenarios with the same entity type and feature systems, which is inappropriate in our case. To this end, we design a pre-training & fine-tuning based Multi-entity Knowledge Transfer framework called MKT. MKT utilizes a multi-entity pre-training module to extract transferable knowledge across different entities. In particular, a feature alignment module is first applied to scale and align different feature schemas. Afterward, a couple of knowledge extractors are employed to extract the common and entity-specific knowledge. In the end, the extracted common knowledge is adopted for target entity model training. Through extensive offline and online experiments, we demonstrated the superiority of MKT over multiple State-Of-The-Art methods.
Entire Space Cascade Delayed Feedback Modeling for Effective Conversion Rate Prediction
Aug 09, 2023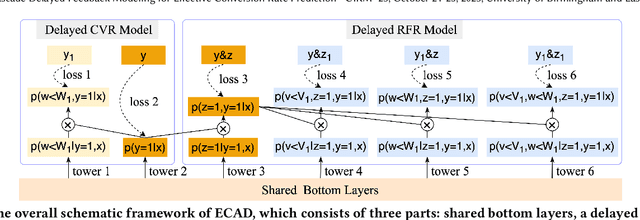
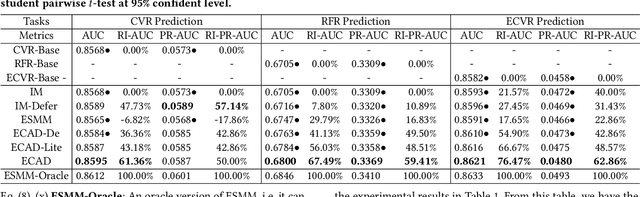
Conversion rate (CVR) prediction is an essential task for large-scale e-commerce platforms. However, refund behaviors frequently occur after conversion in online shopping systems, which drives us to pay attention to effective conversion for building healthier shopping services. This paper defines the probability of item purchasing without any subsequent refund as an effective conversion rate (ECVR). A simple paradigm for ECVR prediction is to decompose it into two sub-tasks: CVR prediction and post-conversion refund rate (RFR) prediction. However, RFR prediction suffers from data sparsity (DS) and sample selection bias (SSB) issues, as the refund behaviors are only available after user purchase. Furthermore, there is delayed feedback in both conversion and refund events and they are sequentially dependent, named cascade delayed feedback (CDF), which significantly harms data freshness for model training. Previous studies mainly focus on tackling DS and SSB or delayed feedback for a single event. To jointly tackle these issues in ECVR prediction, we propose an Entire space CAscade Delayed feedback modeling (ECAD) method. Specifically, ECAD deals with DS and SSB by constructing two tasks including CVR prediction and conversion \& refund rate (CVRFR) prediction using the entire space modeling framework. In addition, it carefully schedules auxiliary tasks to leverage both conversion and refund time within data to alleviate CDF. Experimental results on the offline industrial dataset and online A/B testing demonstrate the effectiveness of ECAD. In addition, ECAD has been deployed in one of the recommender systems in Alibaba, contributing to a significant improvement of ECVR.