 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Two-Stage Knowledge Transfer for Multi-Entity Cross-Domain Recommendation
Feb 29, 2024



In recent years, the recommendation content on e-commerce platforms has become increasingly rich -- a single user feed may contain multiple entities, such as selling products, short videos, and content posts. To deal with the multi-entity recommendation problem, an intuitive solution is to adopt the shared-network-based architecture for joint training. The idea is to transfer the extracted knowledge from one type of entity (source entity) to another (target entity). However, different from the conventional same-entity cross-domain recommendation, multi-entity knowledge transfer encounters several important issues: (1) data distributions of the source entity and target entity are naturally different, making the shared-network-based joint training susceptible to the negative transfer issue, (2) more importantly, the corresponding feature schema of each entity is not exactly aligned (e.g., price is an essential feature for selling product while missing for content posts), making the existing methods no longer appropriate. Recent researchers have also experimented with the pre-training and fine-tuning paradigm. Again, they only consider the scenarios with the same entity type and feature systems, which is inappropriate in our case. To this end, we design a pre-training & fine-tuning based Multi-entity Knowledge Transfer framework called MKT. MKT utilizes a multi-entity pre-training module to extract transferable knowledge across different entities. In particular, a feature alignment module is first applied to scale and align different feature schemas. Afterward, a couple of knowledge extractors are employed to extract the common and entity-specific knowledge. In the end, the extracted common knowledge is adopted for target entity model training. Through extensive offline and online experiments, we demonstrated the superiority of MKT over multiple State-Of-The-Art methods.
Learning Vertex Representations for Bipartite Networks
Jan 16, 2019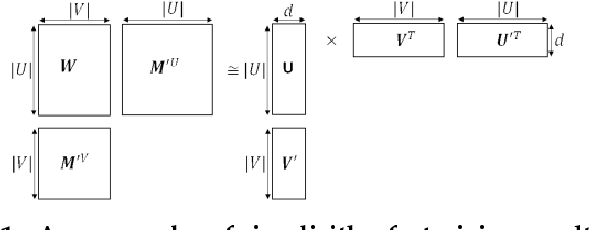
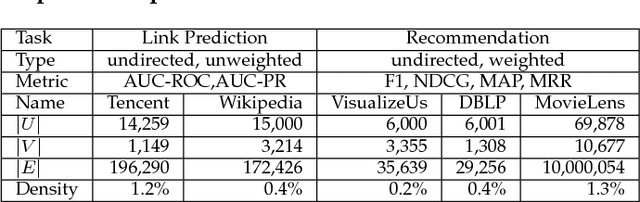
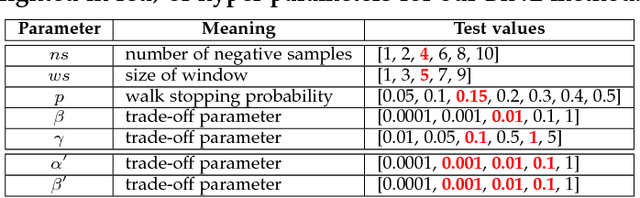
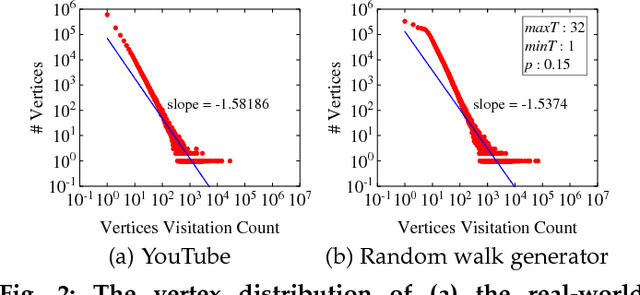
Recent years have witnessed a widespread increase of interest in network representation learning (NRL). By far most research efforts have focused on NRL for homogeneous networks like social networks where vertices are of the same type, or heterogeneous networks like knowledge graphs where vertices (and/or edges) are of different types. There has been relatively little research dedicated to NRL for bipartite networks. Arguably, generic network embedding methods like node2vec and LINE can also be applied to learn vertex embeddings for bipartite networks by ignoring the vertex type information. However, these methods are suboptimal in doing so, since real-world bipartite networks concern the relationship between two types of entities, which usually exhibit different properties and patterns from other types of network data. For example, E-Commerce recommender systems need to capture the collaborative filtering patterns between customers and products, and search engines need to consider the matching signals between queries and webpages. This work addresses the research gap of learning vertex representations for bipartite networks. We present a new solution BiNE, short for Bipartite Network Embedding}, which accounts for two special properties of bipartite networks: long-tail distribution of vertex degrees and implicit connectivity relations between vertices of the same type. Technically speaking, we make three contributions: (1) We design a biased random walk generator to generate vertex sequences that preserve the long-tail distribution of vertices; (2) We propose a new optimization framework by simultaneously modeling the explicit relations (i.e., observed links) and implicit relations (i.e., unobserved but transitive links); (3) We explore the theoretical foundations of BiNE to shed light on how it works, proving that BiNE can be interpreted as factorizing multiple matrices.