 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Negative Samples Are Equal: LLMs Learn Better from Plausible Reasoning
Feb 03, 2026Learning from negative samples holds great promise for improving Large Language Model (LLM) reasoning capability, yet existing methods treat all incorrect responses as equally informative, overlooking the crucial role of sample quality. To address this, we propose Plausible Negative Samples (PNS), a method that synthesizes high-quality negative samples exhibiting expected format and structural coherence while ultimately yielding incorrect answers. PNS trains a dedicated model via reverse reinforcement learning (RL) guided by a composite reward combining format compliance, accuracy inversion, reward model assessment, and chain-of-thought evaluation, generating responses nearly indistinguishable from correct solutions. We further validate PNS as a plug-and-play data source for preference optimization across three backbone models on seven mathematical reasoning benchmarks. Results demonstrate that PNS consistently outperforms other negative sample synthesis methods, achieving an average improvement of 2.03% over RL-trained models.
Towards Instance-wise Personalized Federated Learning via Semi-Implicit Bayesian Prompt Tuning
Aug 27, 2025Federated learning (FL) is a privacy-preserving machine learning paradigm that enables collaborative model training across multiple distributed clients without disclosing their raw data. Personalized federated learning (pFL) has gained increasing attention for its ability to address data heterogeneity. However, most existing pFL methods assume that each client's data follows a single distribution and learn one client-level personalized model for each client. This assumption often fails in practice, where a single client may possess data from multiple sources or domains, resulting in significant intra-client heterogeneity and suboptimal performance. To tackle this challenge, we propose pFedBayesPT, a fine-grained instance-wise pFL framework based on visual prompt tuning. Specifically, we formulate instance-wise prompt generation from a Bayesian perspective and model the prompt posterior as an implicit distribution to capture diverse visual semantics. We derive a variational training objective under the semi-implicit variational inference framework. Extensive experiments on benchmark datasets demonstrate that pFedBayesPT consistently outperforms existing pFL methods under both feature and label heterogeneity settings.
Integrating LLM-Derived Multi-Semantic Intent into Graph Model for Session-based Recommendation
Jul 27, 2025Session-based recommendation (SBR) is mainly based on anonymous user interaction sequences to recommend the items that the next user is most likely to click. Currently, the most popular and high-performing SBR methods primarily leverage graph neural networks (GNNs), which model session sequences as graph-structured data to effectively capture user intent. However, most GNNs-based SBR methods primarily focus on modeling the ID sequence information of session sequences, while neglecting the rich semantic information embedded within them. This limitation significantly hampers model's ability to accurately infer users' true intention. To address above challenge, this paper proposes a novel SBR approach called Integrating LLM-Derived Multi-Semantic Intent into Graph Model for Session-based Recommendation (LLM-DMsRec). The method utilizes a pre-trained GNN model to select the top-k items as candidate item sets and designs prompts along with a large language model (LLM) to infer multi-semantic intents from these candidate items. Specifically, we propose an alignment mechanism that effectively integrates the semantic intent inferred by the LLM with the structural intent captured by GNNs. Extensive experiments conducted on the Beauty and ML-1M datasets demonstrate that the proposed method can be seamlessly integrated into GNNs framework, significantly enhancing its recommendation performance.
CFMD: Dynamic Cross-layer Feature Fusion for Salient Object Detection
Apr 02, 2025Cross-layer feature pyramid networks (CFPNs) have achieved notable progress in multi-scale feature fusion and boundary detail preservation for salient object detection. However, traditional CFPNs still suffer from two core limitations: (1) a computational bottleneck caused by complex feature weighting operations, and (2) degraded boundary accuracy due to feature blurring in the upsampling process. To address these challenges, we propose CFMD, a novel cross-layer feature pyramid network that introduces two key innovations. First, we design a context-aware feature aggregation module (CFLMA), which incorporates the state-of-the-art Mamba architecture to construct a dynamic weight distribution mechanism. This module adaptively adjusts feature importance based on image context, significantly improving both representation efficiency and generalization. Second, we introduce an adaptive dynamic upsampling unit (CFLMD) that preserves spatial details during resolution recovery. By adjusting the upsampling range dynamically and initializing with a bilinear strategy, the module effectively reduces feature overlap and maintains fine-grained boundary structures. Extensive experiments on three standard benchmarks using three mainstream backbone networks demonstrate that CFMD achieves substantial improvements in pixel-level accuracy and boundary segmentation quality, especially in complex scenes. The results validate the effectiveness of CFMD in jointly enhancing computational efficiency and segmentation performance, highlighting its strong potential in salient object detection tasks.
PA-RAG: RAG Alignment via Multi-Perspective Preference Optimization
Dec 19, 2024



The emergence of Retrieval-augmented generation (RAG) has alleviated the issues of outdated and hallucinatory content in the generation of large language models (LLMs), yet it still reveals numerous limitations. When a general-purpose LLM serves as the RAG generator, it often suffers from inadequate response informativeness, response robustness, and citation quality. Past approaches to tackle these limitations, either by incorporating additional steps beyond generating responses or optimizing the generator through supervised fine-tuning (SFT), still failed to align with the RAG requirement thoroughly. Consequently, optimizing the RAG generator from multiple preference perspectives while maintaining its end-to-end LLM form remains a challenge. To bridge this gap, we propose Multiple Perspective Preference Alignment for Retrieval-Augmented Generation (PA-RAG), a method for optimizing the generator of RAG systems to align with RAG requirements comprehensively. Specifically, we construct high-quality instruction fine-tuning data and multi-perspective preference data by sampling varied quality responses from the generator across different prompt documents quality scenarios. Subsequently, we optimize the generator using SFT and Direct Preference Optimization (DPO). Extensive experiments conducted on four question-answer datasets across three LLMs demonstrate that PA-RAG can significantly enhance the performance of RAG generators. Our code and datasets are available at https://github.com/wujwyi/PA-RAG.
Cross-model Control: Improving Multiple Large Language Models in One-time Training
Oct 23, 2024



The number of large language models (LLMs) with varying parameter scales and vocabularies is increasing. While they deliver powerful performance, they also face a set of common optimization needs to meet specific requirements or standards, such as instruction following or avoiding the output of sensitive information from the real world. However, how to reuse the fine-tuning outcomes of one model to other models to reduce training costs remains a challenge. To bridge this gap, we introduce Cross-model Control (CMC), a method that improves multiple LLMs in one-time training with a portable tiny language model. Specifically, we have observed that the logit shift before and after fine-tuning is remarkably similar across different models. Based on this insight, we incorporate a tiny language model with a minimal number of parameters. By training alongside a frozen template LLM, the tiny model gains the capability to alter the logits output by the LLMs. To make this tiny language model applicable to models with different vocabularies, we propose a novel token mapping strategy named PM-MinED. We have conducted extensive experiments on instruction tuning and unlearning tasks, demonstrating the effectiveness of CMC. Our code is available at https://github.com/wujwyi/CMC.
A Time Series is Worth Five Experts: Heterogeneous Mixture of Experts for Traffic Flow Prediction
Sep 26, 2024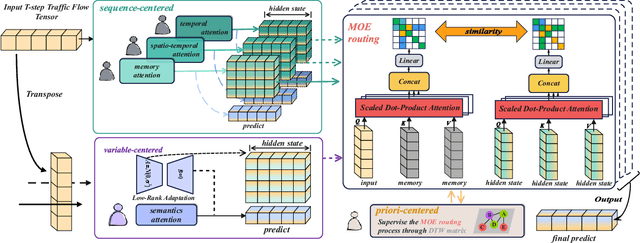
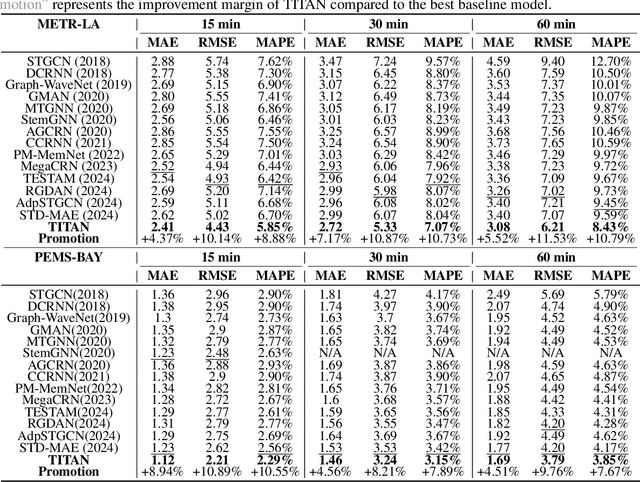
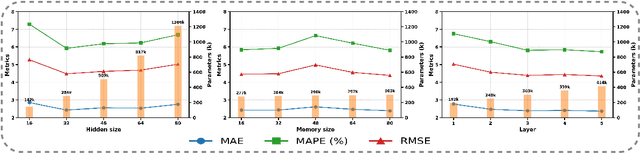
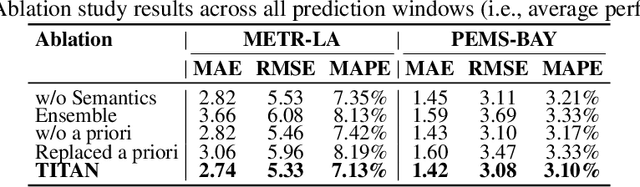
Accurate traffic prediction faces significant challenges, necessitating a deep understanding of both temporal and spatial cues and their complex interactions across multiple variables. Recent advancements in traffic prediction systems are primarily due to the development of complex sequence-centric models. However, existing approaches often embed multiple variables and spatial relationships at each time step, which may hinder effective variable-centric learning, ultimately leading to performance degradation in traditional traffic prediction tasks. To overcome these limitations, we introduce variable-centric and prior knowledge-centric modeling techniques. Specifically, we propose a Heterogeneous Mixture of Experts (TITAN) model for traffic flow prediction. TITAN initially consists of three experts focused on sequence-centric modeling. Then, designed a low-rank adaptive method, TITAN simultaneously enables variable-centric modeling. Furthermore, we supervise the gating process using a prior knowledge-centric modeling strategy to ensure accurate routing. Experiments on two public traffic network datasets, METR-LA and PEMS-BAY, demonstrate that TITAN effectively captures variable-centric dependencies while ensuring accurate routing. Consequently, it achieves improvements in all evaluation metrics, ranging from approximately 4.37\% to 11.53\%, compared to previous state-of-the-art (SOTA) models. The code is open at \href{https://github.com/sqlcow/TITAN}{https://github.com/sqlcow/TITAN}.
Expert-level vision-language foundation model for real-world radiology and comprehensive evaluation
Sep 24, 2024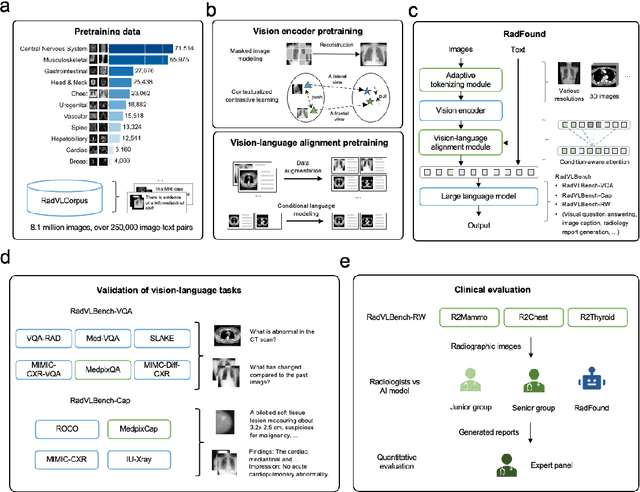
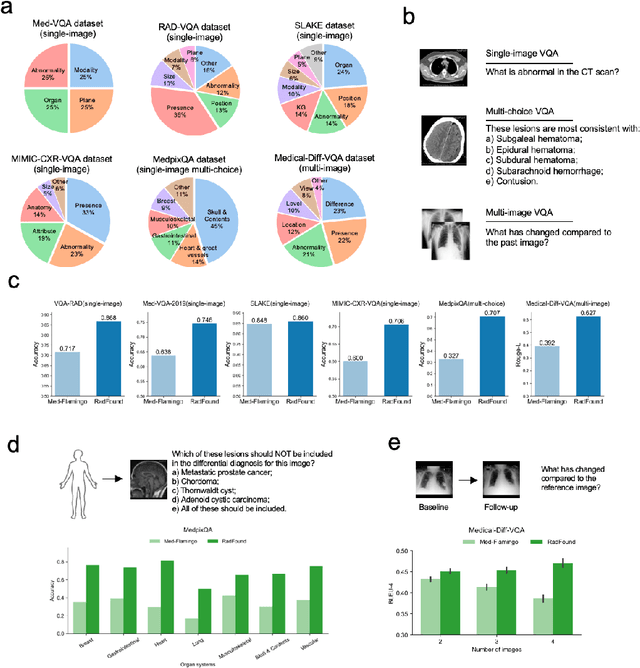
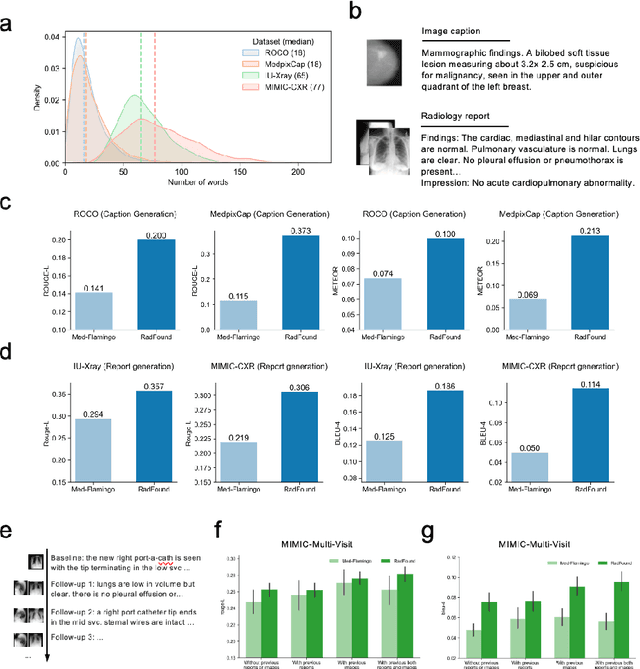
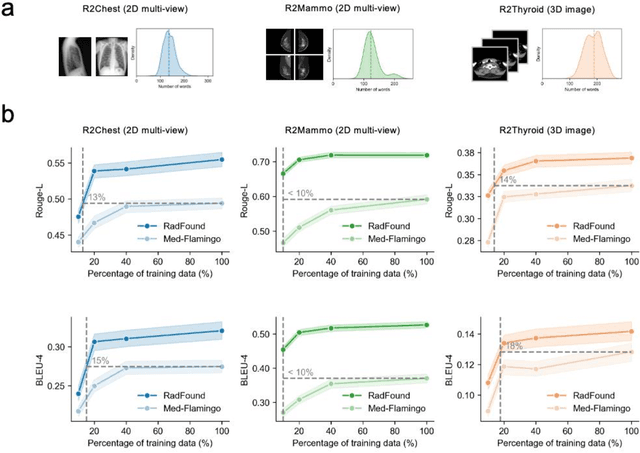
Radiology is a vital and complex component of modern clinical workflow and covers many tasks. Recently, vision-language (VL) foundation models in medicine have shown potential in processing multimodal information, offering a unified solution for various radiology tasks. However, existing studies either pre-trained VL models on natural data or did not fully integrate vision-language architecture and pretraining, often neglecting the unique multimodal complexity in radiology images and their textual contexts. Additionally, their practical applicability in real-world scenarios remains underexplored. Here, we present RadFound, a large and open-source vision-language foundation model tailored for radiology, that is trained on the most extensive dataset of over 8.1 million images and 250,000 image-text pairs, covering 19 major organ systems and 10 imaging modalities. To establish expert-level multimodal perception and generation capabilities, RadFound introduces an enhanced vision encoder to capture intra-image local features and inter-image contextual information, and a unified cross-modal learning design tailored to radiology. To fully assess the models' capability, we construct a benchmark, RadVLBench, including radiology interpretation tasks like medical vision-language question-answering, as well as text generation tasks ranging from captioning to report generation. We also propose a human evaluation framework. When evaluated on the real-world benchmark involving three representative modalities, 2D images (chest X-rays), multi-view images (mammograms), and 3D images (thyroid CT scans), RadFound significantly outperforms other VL foundation models on both quantitative metrics and human evaluation. In summary, the development of RadFound represents an advancement in radiology generalists, demonstrating broad applicability potential for integration into clinical workflows.
DFDG: Data-Free Dual-Generator Adversarial Distillation for One-Shot Federated Learning
Sep 12, 2024



Federated Learning (FL) is a distributed machine learning scheme in which clients jointly participate in the collaborative training of a global model by sharing model information rather than their private datasets. In light of concerns associated with communication and privacy, one-shot FL with a single communication round has emerged as a de facto promising solution. However, existing one-shot FL methods either require public datasets, focus on model homogeneous settings, or distill limited knowledge from local models, making it difficult or even impractical to train a robust global model. To address these limitations, we propose a new data-free dual-generator adversarial distillation method (namely DFDG) for one-shot FL, which can explore a broader local models' training space via training dual generators. DFDG is executed in an adversarial manner and comprises two parts: dual-generator training and dual-model distillation. In dual-generator training, we delve into each generator concerning fidelity, transferability and diversity to ensure its utility, and additionally tailor the cross-divergence loss to lessen the overlap of dual generators' output spaces. In dual-model distillation, the trained dual generators work together to provide the training data for updates of the global model. At last, our extensive experiments on various image classification tasks show that DFDG achieves significant performance gains in accuracy compared to SOTA baselines.
Fast and Modular Autonomy Software for Autonomous Racing Vehicles
Aug 27, 2024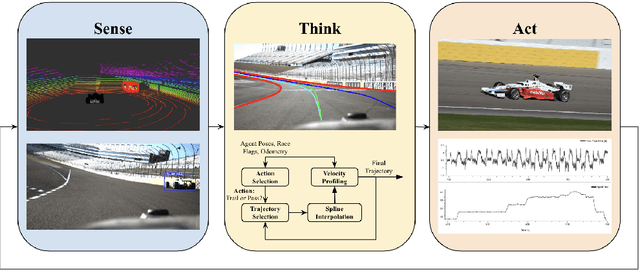



Autonomous motorsports aim to replicate the human racecar driver with software and sensors. As in traditional motorsports, Autonomous Racing Vehicles (ARVs) are pushed to their handling limits in multi-agent scenarios at extremely high ($\geq 150mph$) speeds. This Operational Design Domain (ODD) presents unique challenges across the autonomy stack. The Indy Autonomous Challenge (IAC) is an international competition aiming to advance autonomous vehicle development through ARV competitions. While far from challenging what a human racecar driver can do, the IAC is pushing the state of the art by facilitating full-sized ARV competitions. This paper details the MIT-Pitt-RW Team's approach to autonomous racing in the IAC. In this work, we present our modular and fast approach to agent detection, motion planning and controls to create an autonomy stack. We also provide analysis of the performance of the software stack in single and multi-agent scenarios for rapid deployment in a fast-paced competition environment. We also cover what did and did not work when deployed on a physical system the Dallara AV-21 platform and potential improvements to address these shortcomings. Finally, we convey lessons learned and discuss limitations and future directions for improvement.
* Published in Journal of Field Robotics