 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
User Feedback Alignment for LLM-powered Exploration in Large-scale Recommendation Systems
Apr 07, 2025Exploration, the act of broadening user experiences beyond their established preferences, is challenging in large-scale recommendation systems due to feedback loops and limited signals on user exploration patterns. Large Language Models (LLMs) offer potential by leveraging their world knowledge to recommend novel content outside these loops. A key challenge is aligning LLMs with user preferences while preserving their knowledge and reasoning. While using LLMs to plan for the next novel user interest, this paper introduces a novel approach combining hierarchical planning with LLM inference-time scaling to improve recommendation relevancy without compromising novelty. We decouple novelty and user-alignment, training separate LLMs for each objective. We then scale up the novelty-focused LLM's inference and select the best-of-n predictions using the user-aligned LLM. Live experiments demonstrate efficacy, showing significant gains in both user satisfaction (measured by watch activity and active user counts) and exploration diversity.
LLMs for User Interest Exploration: A Hybrid Approach
May 25, 2024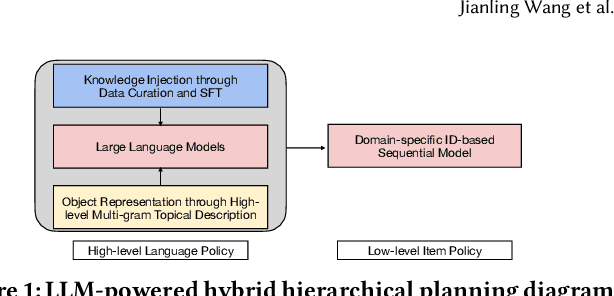

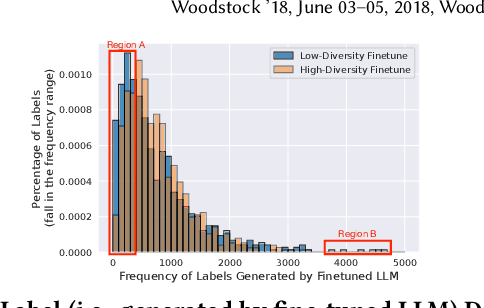
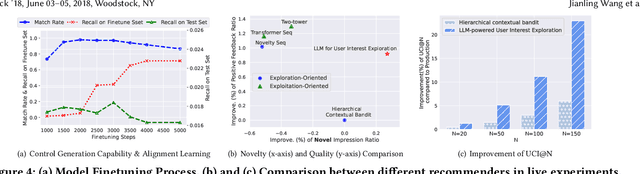
Traditional recommendation systems are subject to a strong feedback loop by learning from and reinforcing past user-item interactions, which in turn limits the discovery of novel user interests. To address this, we introduce a hybrid hierarchical framework combining Large Language Models (LLMs) and classic recommendation models for user interest exploration. The framework controls the interfacing between the LLMs and the classic recommendation models through "interest clusters", the granularity of which can be explicitly determined by algorithm designers. It recommends the next novel interests by first representing "interest clusters" using language, and employs a fine-tuned LLM to generate novel interest descriptions that are strictly within these predefined clusters. At the low level, it grounds these generated interests to an item-level policy by restricting classic recommendation models, in this case a transformer-based sequence recommender to return items that fall within the novel clusters generated at the high level. We showcase the efficacy of this approach on an industrial-scale commercial platform serving billions of users. Live experiments show a significant increase in both exploration of novel interests and overall user enjoyment of the platform.
Weakly supervised alignment and registration of MR-CT for cervical cancer radiotherapy
May 21, 2024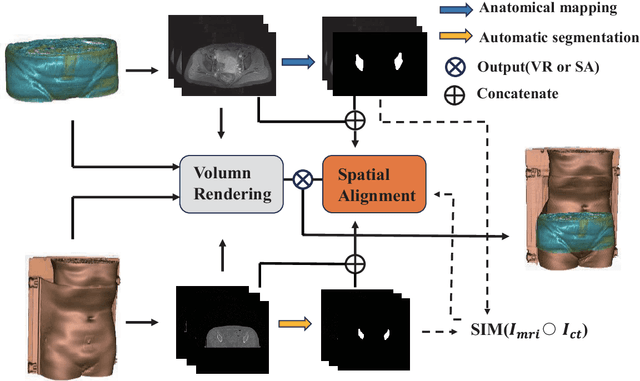
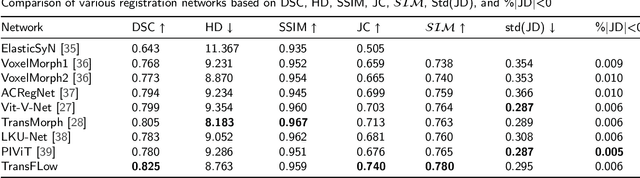
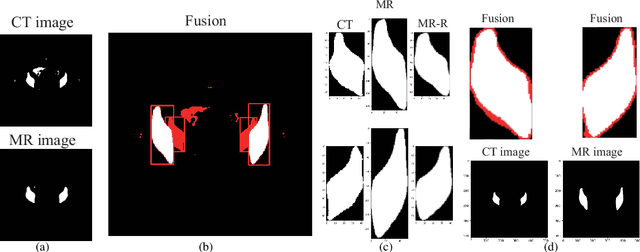
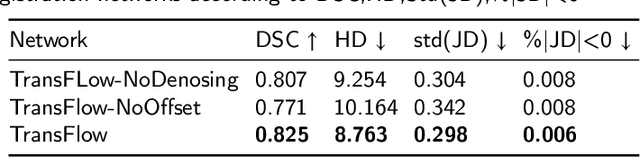
Cervical cancer is one of the leading causes of death in women, and brachytherapy is currently the primary treatment method. However, it is important to precisely define the extent of paracervical tissue invasion to improve cancer diagnosis and treatment options. The fusion of the information characteristics of both computed tomography (CT) and magnetic resonance imaging(MRI) modalities may be useful in achieving a precise outline of the extent of paracervical tissue invasion. Registration is the initial step in information fusion. However, when aligning multimodal images with varying depths, manual alignment is prone to large errors and is time-consuming. Furthermore, the variations in the size of the Region of Interest (ROI) and the shape of multimodal images pose a significant challenge for achieving accurate registration.In this paper, we propose a preliminary spatial alignment algorithm and a weakly supervised multimodal registration network. The spatial position alignment algorithm efficiently utilizes the limited annotation information in the two modal images provided by the doctor to automatically align multimodal images with varying depths. By utilizing aligned multimodal images for weakly supervised registration and incorporating pyramidal features and cost volume to estimate the optical flow, the results indicate that the proposed method outperforms traditional volume rendering alignment methods and registration networks in various evaluation metrics. This demonstrates the effectiveness of our model in multimodal image registration.
Evolving symbolic density functionals
Mar 25, 2022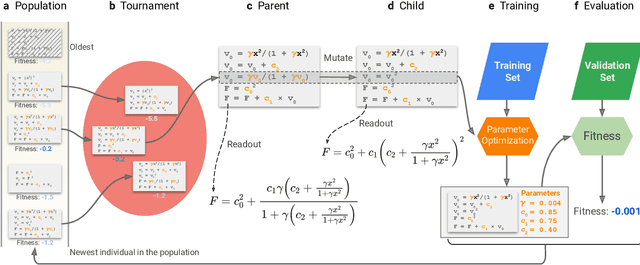
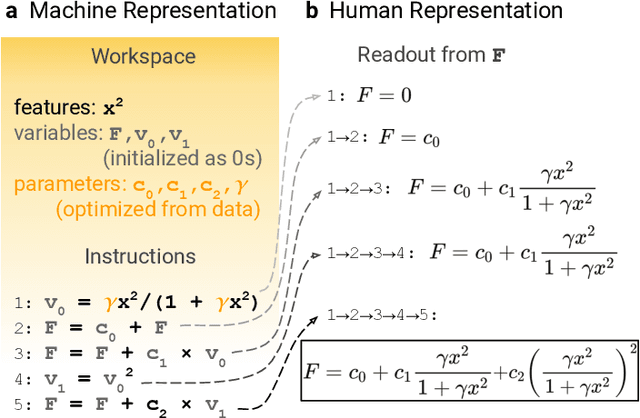
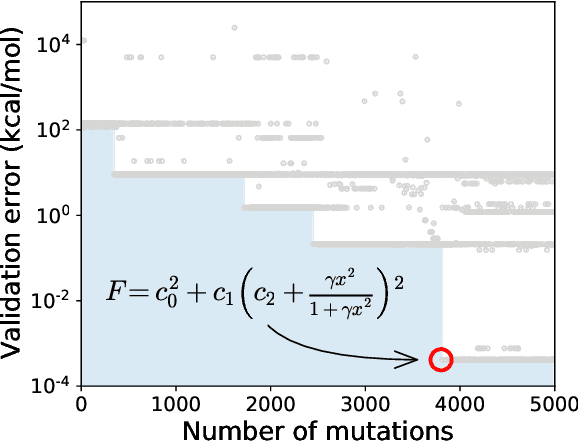
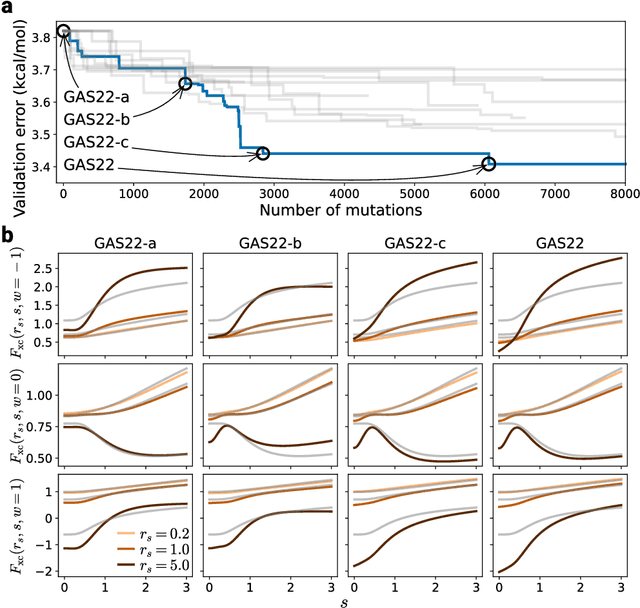
Systematic development of accurate density functionals has been a decades-long challenge for scientists. Despite the emerging application of machine learning (ML) in approximating functionals, the resulting ML functionals usually contain more than tens of thousands parameters, which makes a huge gap in the formulation with the conventional human-designed symbolic functionals. We propose a new framework, Symbolic Functional Evolutionary Search (SyFES), that automatically constructs accurate functionals in the symbolic form, which is more explainable to humans, cheaper to evaluate, and easier to integrate to existing density functional theory codes than other ML functionals. We first show that without prior knowledge, SyFES reconstructed a known functional from scratch. We then demonstrate that evolving from an existing functional $\omega$B97M-V, SyFES found a new functional, GAS22 (Google Accelerated Science 22), that performs better on main-group chemistry. Our framework opens a new direction in leveraging computing power for the systematic development of symbolic density functionals.
Breast Cancer Classification with Ultrasound Images Based on SLIC
Apr 25, 2019

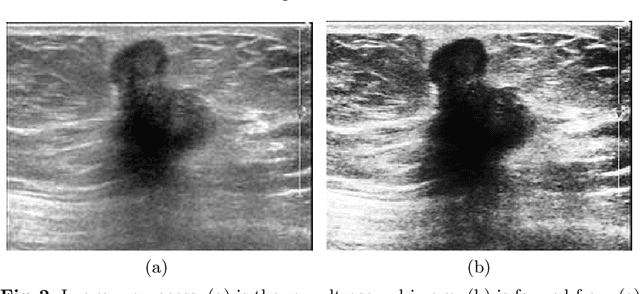

Ultrasound image diagnosis of breast tumors has been widely used in recent years. However, there are some problems of it, for instance, poor quality, intense noise and uneven echo distribution, which has created a huge obstacle to diagnosis. To overcome these problems, we propose a novel method, a breast cancer classification with ultrasound images based on SLIC (BCCUI). We first utilize the Region of Interest (ROI) extraction based on Simple Linear Iterative Clustering (SLIC) algorithm and region growing algorithm to extract the ROI at the super-pixel level. Next, the features of ROI are extracted. Furthermore, the Support Vector Machine (SVM) classifier is applied. The calculation states that the accuracy of this segment algorithm is up to 88.00% and the sensitivity of the algorithm is up to 92.05%, which proves that the classifier presents in this paper has certain research meaning and applied worthiness.
SeFM: A Sequential Feature Point Matching Algorithm for Object 3D Reconstruction
Dec 07, 2018
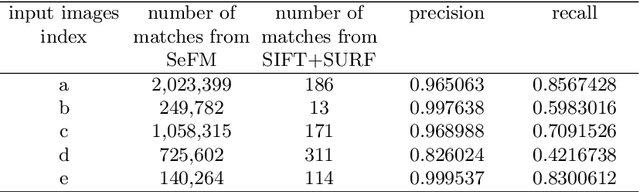
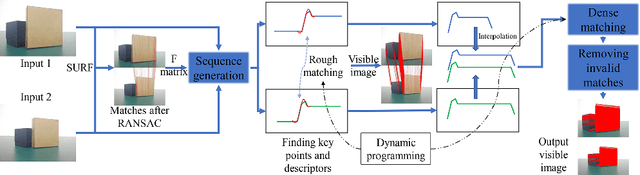

3D reconstruction is a fundamental issue in many applications and the feature point matching problem is a key step while reconstructing target objects. Conventional algorithms can only find a small number of feature points from two images which is quite insufficient for reconstruction. To overcome this problem, we propose SeFM a sequential feature point matching algorithm. We first utilize the epipolar geometry to find the epipole of each image. Rotating along the epipole, we generate a set of the epipolar lines and reserve those intersecting with the input image. Next, a rough matching phase, followed by a dense matching phase, is applied to find the matching dot-pairs using dynamic programming. Furthermore, we also remove wrong matching dot-pairs by calculating the validity. Experimental results illustrate that SeFM can achieve around 1,000 to 10,000 times matching dot-pairs, depending on individual image, compared to conventional algorithms and the object reconstruction with only two images is semantically visible. Moreover, it outperforms conventional algorithms, such as SIFT and SURF, regarding precision and recall.
Quantitatively Evaluating GANs With Divergences Proposed for Training
Apr 28, 2018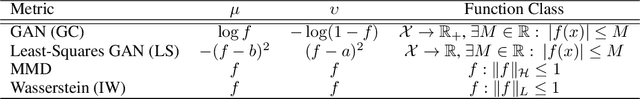
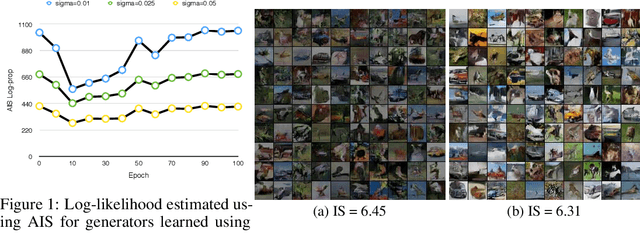
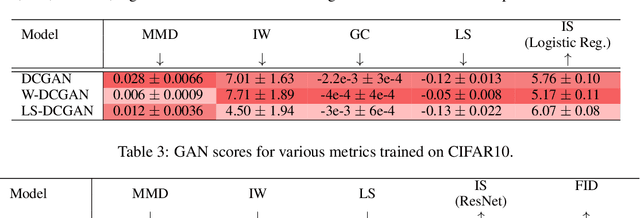

Generative adversarial networks (GANs) have been extremely effective in approximating complex distributions of high-dimensional, input data samples, and substantial progress has been made in understanding and improving GAN performance in terms of both theory and application. However, we currently lack quantitative methods for model assessment. Because of this, while many GAN variants are being proposed, we have relatively little understanding of their relative abilities. In this paper, we evaluate the performance of various types of GANs using divergence and distance functions typically used only for training. We observe consistency across the various proposed metrics and, interestingly, the test-time metrics do not favour networks that use the same training-time criterion. We also compare the proposed metrics to human perceptual scores.
Generative Adversarial Parallelization
Dec 13, 2016


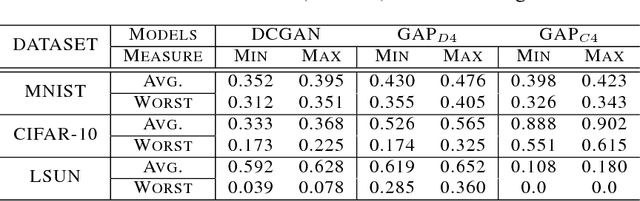
Generative Adversarial Networks have become one of the most studied frameworks for unsupervised learning due to their intuitive formulation. They have also been shown to be capable of generating convincing examples in limited domains, such as low-resolution images. However, they still prove difficult to train in practice and tend to ignore modes of the data generating distribution. Quantitatively capturing effects such as mode coverage and more generally the quality of the generative model still remain elusive. We propose Generative Adversarial Parallelization, a framework in which many GANs or their variants are trained simultaneously, exchanging their discriminators. This eliminates the tight coupling between a generator and discriminator, leading to improved convergence and improved coverage of modes. We also propose an improved variant of the recently proposed Generative Adversarial Metric and show how it can score individual GANs or their collections under the GAP model.
Theano-MPI: a Theano-based Distributed Training Framework
May 26, 2016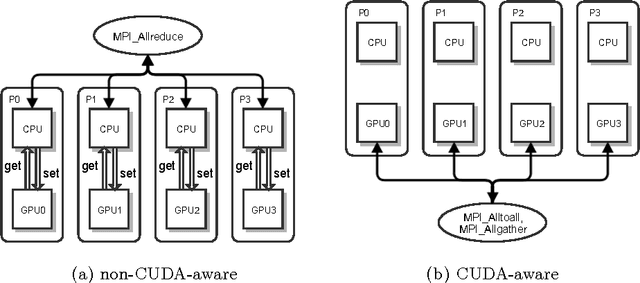
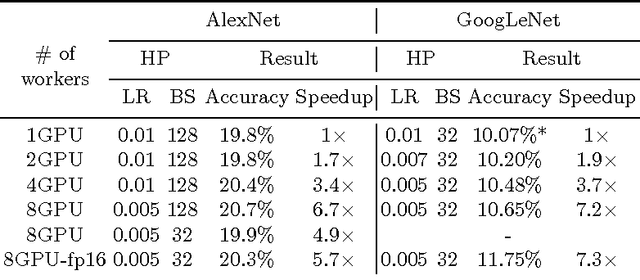
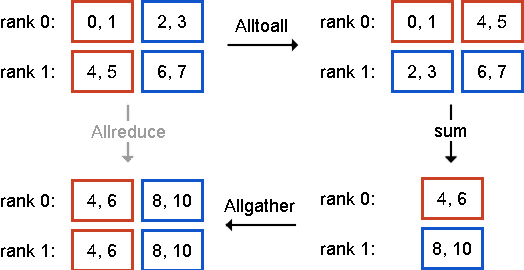
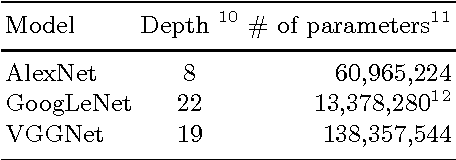
We develop a scalable and extendable training framework that can utilize GPUs across nodes in a cluster and accelerate the training of deep learning models based on data parallelism. Both synchronous and asynchronous training are implemented in our framework, where parameter exchange among GPUs is based on CUDA-aware MPI. In this report, we analyze the convergence and capability of the framework to reduce training time when scaling the synchronous training of AlexNet and GoogLeNet from 2 GPUs to 8 GPUs. In addition, we explore novel ways to reduce the communication overhead caused by exchanging parameters. Finally, we release the framework as open-source for further research on distributed deep learning