 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheano-MPI: a Theano-based Distributed Training Framework
May 26, 2016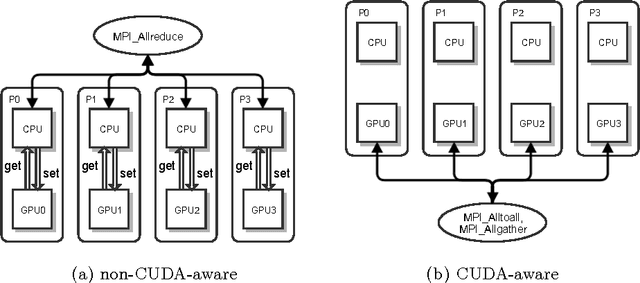
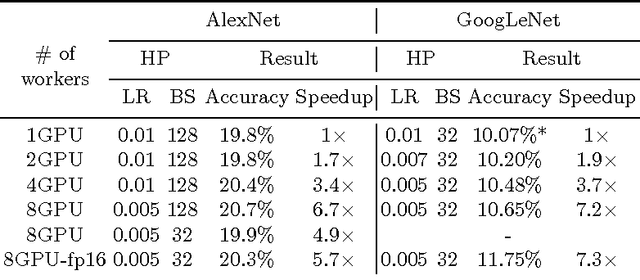
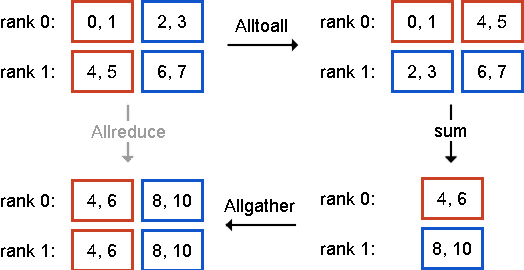
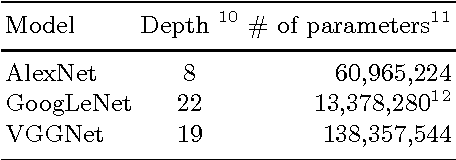
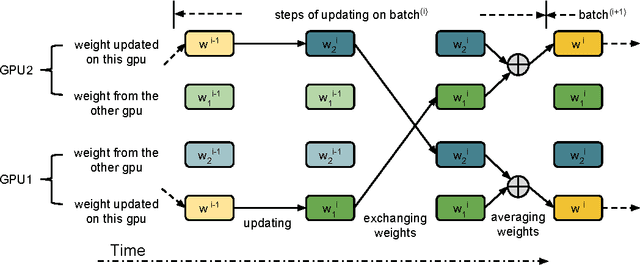
We develop a scalable and extendable training framework that can utilize GPUs across nodes in a cluster and accelerate the training of deep learning models based on data parallelism. Both synchronous and asynchronous training are implemented in our framework, where parameter exchange among GPUs is based on CUDA-aware MPI. In this report, we analyze the convergence and capability of the framework to reduce training time when scaling the synchronous training of AlexNet and GoogLeNet from 2 GPUs to 8 GPUs. In addition, we explore novel ways to reduce the communication overhead caused by exchanging parameters. Finally, we release the framework as open-source for further research on distributed deep learning
Theano-based Large-Scale Visual Recognition with Multiple GPUs
Apr 06, 2015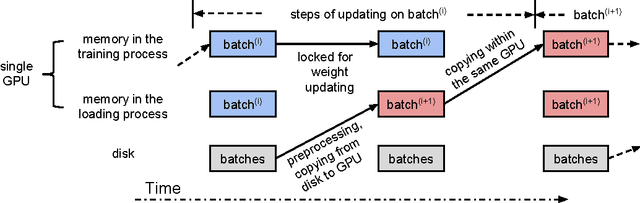

In this report, we describe a Theano-based AlexNet (Krizhevsky et al., 2012) implementation and its naive data parallelism on multiple GPUs. Our performance on 2 GPUs is comparable with the state-of-art Caffe library (Jia et al., 2014) run on 1 GPU. To the best of our knowledge, this is the first open-source Python-based AlexNet implementation to-date.