 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Image Capture for Computer Vision-Powered Taxonomic Identification and Trait Recognition of Biodiversity Specimens
May 22, 2025Biological collections house millions of specimens documenting Earth's biodiversity, with digital images increasingly available through open-access platforms. Most imaging protocols were developed for human visual interpretation without considering computational analysis requirements. This paper aims to bridge the gap between current imaging practices and the potential for automated analysis by presenting key considerations for creating biological specimen images optimized for computer vision applications. We provide conceptual computer vision topics for context, addressing fundamental concerns including model generalization, data leakage, and comprehensive metadata documentation, and outline practical guidance on specimen imagine, and data storage. These recommendations were synthesized through interdisciplinary collaboration between taxonomists, collection managers, ecologists, and computer scientists. Through this synthesis, we have identified ten interconnected considerations that form a framework for successfully integrating biological specimen images into computer vision pipelines. The key elements include: (1) comprehensive metadata documentation, (2) standardized specimen positioning, (3) consistent size and color calibration, (4) protocols for handling multiple specimens in one image, (5) uniform background selection, (6) controlled lighting, (7) appropriate resolution and magnification, (8) optimal file formats, (9) robust data archiving strategies, and (10) accessible data sharing practices. By implementing these recommendations, collection managers, taxonomists, and biodiversity informaticians can generate images that support automated trait extraction, species identification, and novel ecological and evolutionary analyses at unprecedented scales. Successful implementation lies in thorough documentation of methodological choices.
LAST SToP For Modeling Asynchronous Time Series
Feb 04, 2025



We present a novel prompt design for Large Language Models (LLMs) tailored to Asynchronous Time Series. Unlike regular time series, which assume values at evenly spaced time points, asynchronous time series consist of timestamped events occurring at irregular intervals, each described in natural language. Our approach effectively utilizes the rich natural language of event descriptions, allowing LLMs to benefit from their broad world knowledge for reasoning across different domains and tasks. This allows us to extend the scope of asynchronous time series analysis beyond forecasting to include tasks like anomaly detection and data imputation. We further introduce Stochastic Soft Prompting, a novel prompt-tuning mechanism that significantly improves model performance, outperforming existing fine-tuning methods such as QLoRA. Through extensive experiments on real world datasets, we demonstrate that our approach achieves state-of-the-art performance across different tasks and datasets.
Towards Stable Preferences for Stakeholder-aligned Machine Learning
Feb 02, 2024

In response to the pressing challenge of kidney allocation, characterized by growing demands for organs, this research sets out to develop a data-driven solution to this problem, which also incorporates stakeholder values. The primary objective of this study is to create a method for learning both individual and group-level preferences pertaining to kidney allocations. Drawing upon data from the 'Pairwise Kidney Patient Online Survey.' Leveraging two distinct datasets and evaluating across three levels - Individual, Group and Stability - we employ machine learning classifiers assessed through several metrics. The Individual level model predicts individual participant preferences, the Group level model aggregates preferences across participants, and the Stability level model, an extension of the Group level, evaluates the stability of these preferences over time. By incorporating stakeholder preferences into the kidney allocation process, we aspire to advance the ethical dimensions of organ transplantation, contributing to more transparent and equitable practices while promoting the integration of moral values into algorithmic decision-making.
Learning Permutation Invariant Representations using Memory Networks
Nov 18, 2019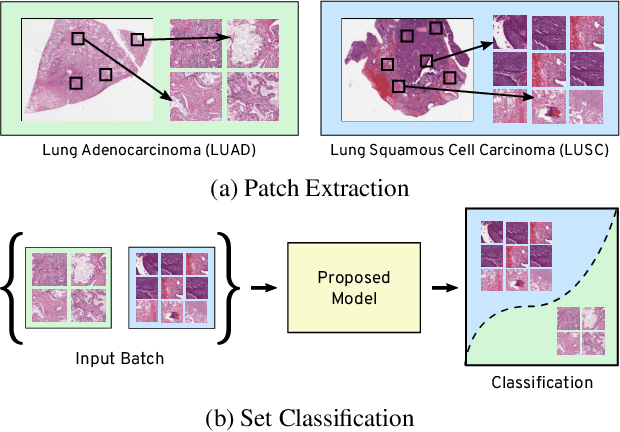
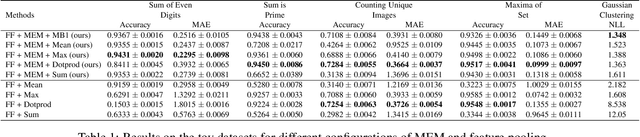
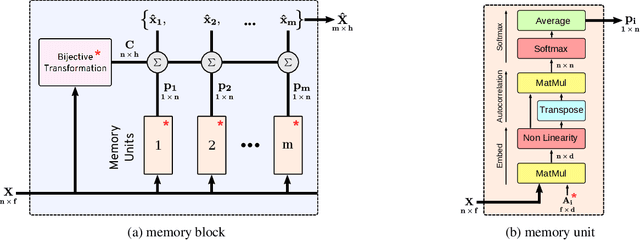

Many real world tasks such as 3D object detection and high-resolution image classification involve learning from a set of instances. In these cases, only a group of instances, a set, collectively contains meaningful information and therefore only the sets have labels, and not individual data instances. In this work, we present a permutation invariant neural network called a \textbf{Memory-based Exchangeable Model (MEM)} for learning set functions. The model consists of memory units that embed an input sequence to high-level features (memories) enabling the model to learn inter-dependencies among instances of the set in the form of attention vectors. To demonstrate its learning ability, we evaluated our model on test datasets created using MNIST, point cloud classification, and population estimation. We also tested the model for classifying histopathology whole slide images to discriminate between two subtypes of Lung cancer---Lung Adenocarcinoma, and Lung Squamous Cell Carcinoma. We systematically extracted patches from lung cancer images from The Cancer Genome Atlas~(TCGA) dataset, the largest public repository of histopathology images. The proposed method achieved a competitive classification accuracy of 84.84\%. The results on other datasets are promising and demonstrate the efficacy of our model.
BitNet: Bit-Regularized Deep Neural Networks
Jun 26, 2018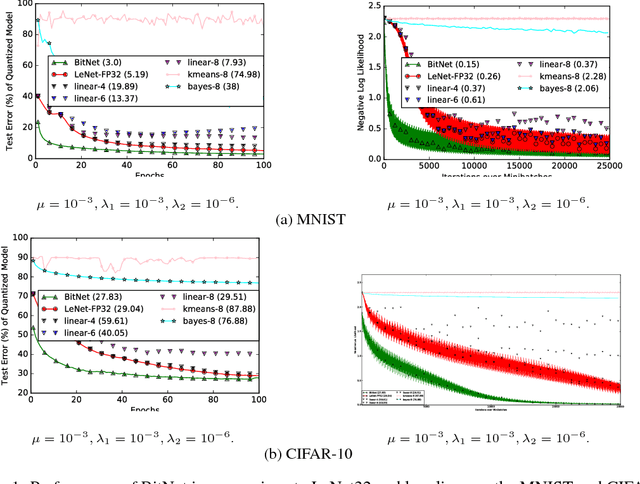
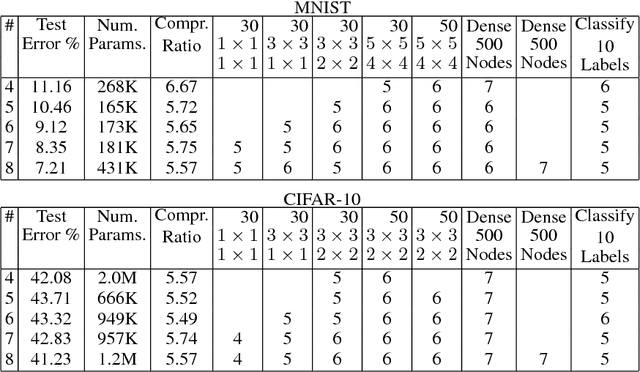
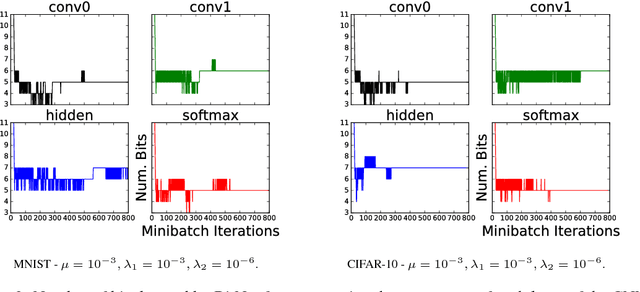
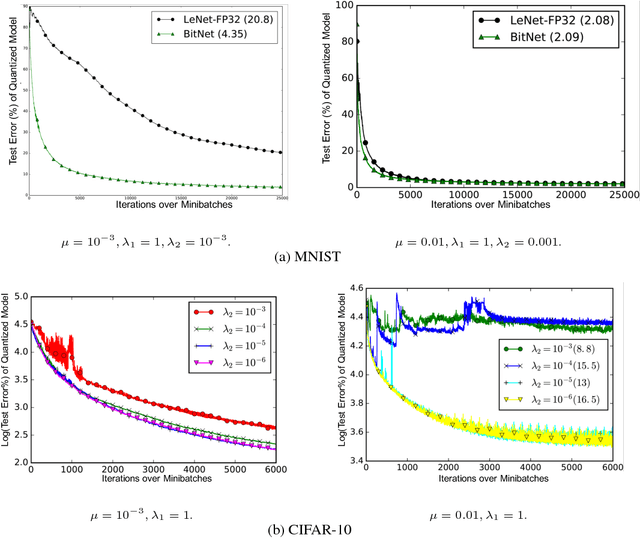
We present a novel optimization strategy for training neural networks which we call "BitNet". The parameters of neural networks are usually unconstrained and have a dynamic range dispersed over all real values. Our key idea is to limit the expressive power of the network by dynamically controlling the range and set of values that the parameters can take. We formulate this idea using a novel end-to-end approach that circumvents the discrete parameter space by optimizing a relaxed continuous and differentiable upper bound of the typical classification loss function. The approach can be interpreted as a regularization inspired by the Minimum Description Length (MDL) principle. For each layer of the network, our approach optimizes real-valued translation and scaling factors and arbitrary precision integer-valued parameters (weights). We empirically compare BitNet to an equivalent unregularized model on the MNIST and CIFAR-10 datasets. We show that BitNet converges faster to a superior quality solution. Additionally, the resulting model has significant savings in memory due to the use of integer-valued parameters.
Quantitatively Evaluating GANs With Divergences Proposed for Training
Apr 28, 2018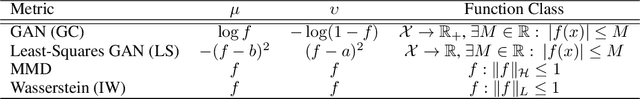
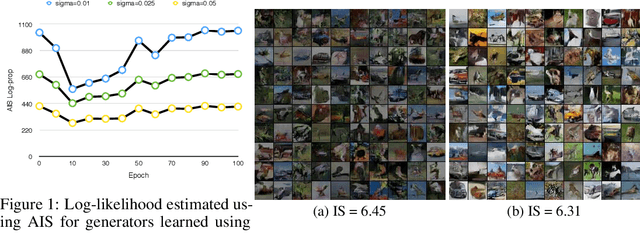
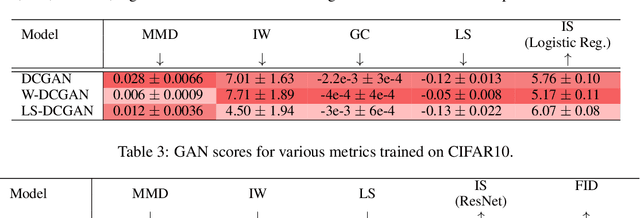

Generative adversarial networks (GANs) have been extremely effective in approximating complex distributions of high-dimensional, input data samples, and substantial progress has been made in understanding and improving GAN performance in terms of both theory and application. However, we currently lack quantitative methods for model assessment. Because of this, while many GAN variants are being proposed, we have relatively little understanding of their relative abilities. In this paper, we evaluate the performance of various types of GANs using divergence and distance functions typically used only for training. We observe consistency across the various proposed metrics and, interestingly, the test-time metrics do not favour networks that use the same training-time criterion. We also compare the proposed metrics to human perceptual scores.
Convolutional Neural Networks Regularized by Correlated Noise
Apr 03, 2018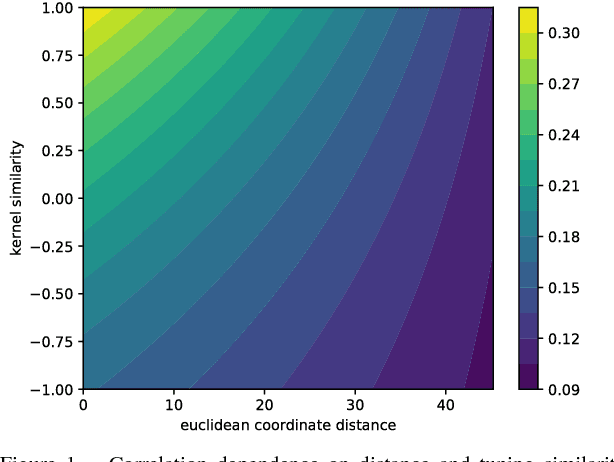
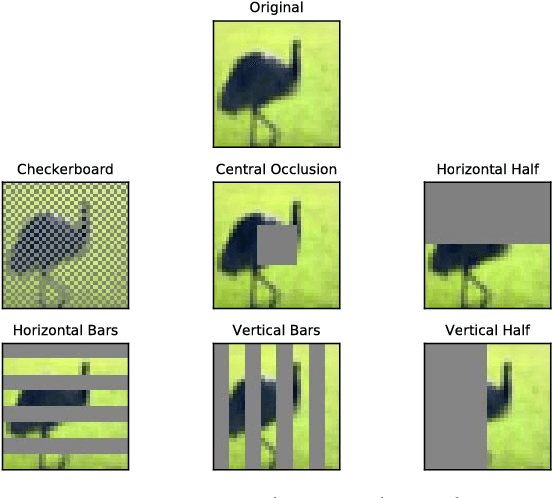

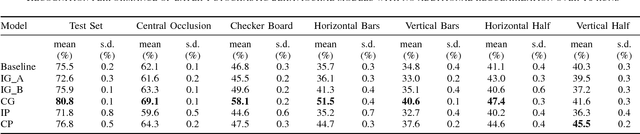
Neurons in the visual cortex are correlated in their variability. The presence of correlation impacts cortical processing because noise cannot be averaged out over many neurons. In an effort to understand the functional purpose of correlated variability, we implement and evaluate correlated noise models in deep convolutional neural networks. Inspired by the cortex, correlation is defined as a function of the distance between neurons and their selectivity. We show how to sample from high-dimensional correlated distributions while keeping the procedure differentiable, so that back-propagation can proceed as usual. The impact of correlated variability is evaluated on the classification of occluded and non-occluded images with and without the presence of other regularization techniques, such as dropout. More work is needed to understand the effects of correlations in various conditions, however in 10/12 of the cases we studied, the best performance on occluded images was obtained from a model with correlated noise.
Hand Pose Estimation through Semi-Supervised and Weakly-Supervised Learning
Sep 15, 2017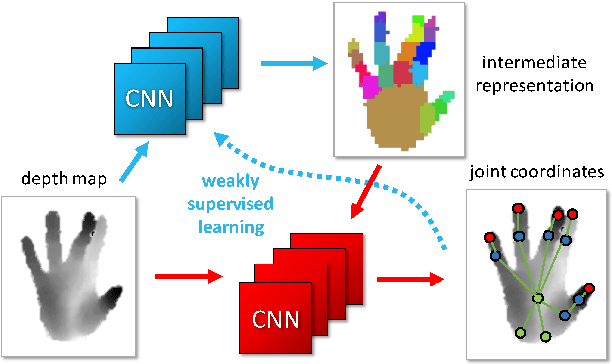
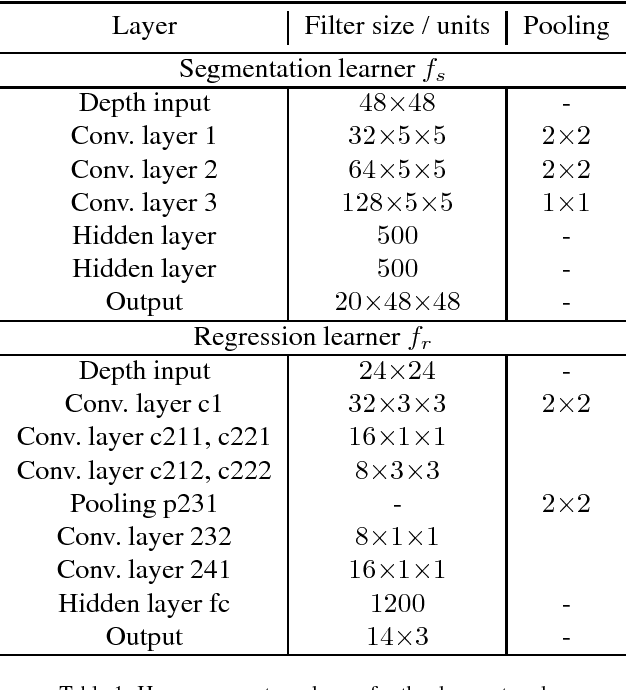
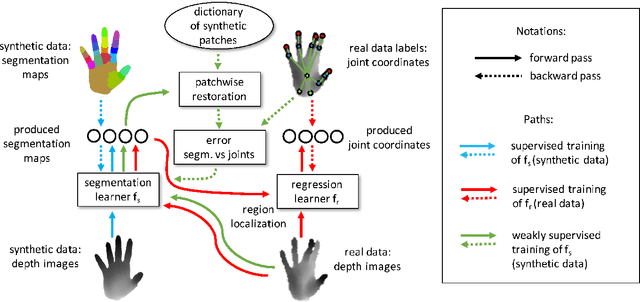

We propose a method for hand pose estimation based on a deep regressor trained on two different kinds of input. Raw depth data is fused with an intermediate representation in the form of a segmentation of the hand into parts. This intermediate representation contains important topological information and provides useful cues for reasoning about joint locations. The mapping from raw depth to segmentation maps is learned in a semi/weakly-supervised way from two different datasets: (i) a synthetic dataset created through a rendering pipeline including densely labeled ground truth (pixelwise segmentations); and (ii) a dataset with real images for which ground truth joint positions are available, but not dense segmentations. Loss for training on real images is generated from a patch-wise restoration process, which aligns tentative segmentation maps with a large dictionary of synthetic poses. The underlying premise is that the domain shift between synthetic and real data is smaller in the intermediate representation, where labels carry geometric and topological meaning, than in the raw input domain. Experiments on the NYU dataset show that the proposed training method decreases error on joints over direct regression of joints from depth data by 15.7%.
Generative Adversarial Parallelization
Dec 13, 2016


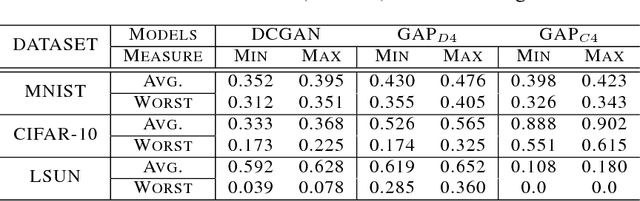
Generative Adversarial Networks have become one of the most studied frameworks for unsupervised learning due to their intuitive formulation. They have also been shown to be capable of generating convincing examples in limited domains, such as low-resolution images. However, they still prove difficult to train in practice and tend to ignore modes of the data generating distribution. Quantitatively capturing effects such as mode coverage and more generally the quality of the generative model still remain elusive. We propose Generative Adversarial Parallelization, a framework in which many GANs or their variants are trained simultaneously, exchanging their discriminators. This eliminates the tight coupling between a generator and discriminator, leading to improved convergence and improved coverage of modes. We also propose an improved variant of the recently proposed Generative Adversarial Metric and show how it can score individual GANs or their collections under the GAP model.
Caffeinated FPGAs: FPGA Framework For Convolutional Neural Networks
Sep 30, 2016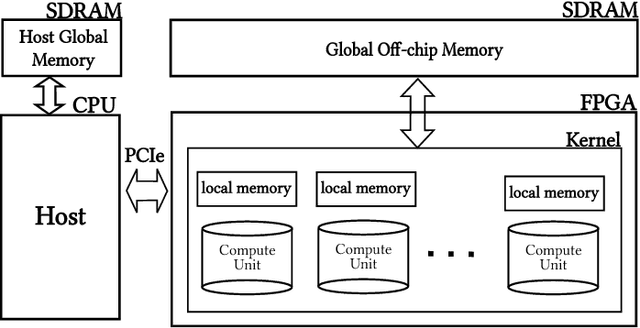
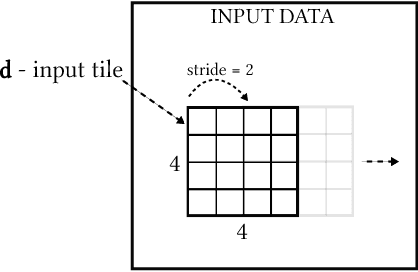

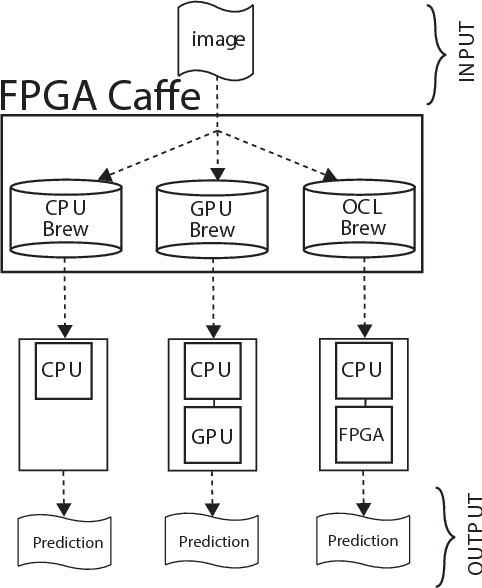
Convolutional Neural Networks (CNNs) have gained significant traction in the field of machine learning, particularly due to their high accuracy in visual recognition. Recent works have pushed the performance of GPU implementations of CNNs to significantly improve their classification and training times. With these improvements, many frameworks have become available for implementing CNNs on both CPUs and GPUs, with no support for FPGA implementations. In this work we present a modified version of the popular CNN framework Caffe, with FPGA support. This allows for classification using CNN models and specialized FPGA implementations with the flexibility of reprogramming the device when necessary, seamless memory transactions between host and device, simple-to-use test benches, and the ability to create pipelined layer implementations. To validate the framework, we use the Xilinx SDAccel environment to implement an FPGA-based Winograd convolution engine and show that the FPGA layer can be used alongside other layers running on a host processor to run several popular CNNs (AlexNet, GoogleNet, VGG A, Overfeat). The results show that our framework achieves 50 GFLOPS across 3x3 convolutions in the benchmarks. This is achieved within a practical framework, which will aid in future development of FPGA-based CNNs.