 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitNet: Bit-Regularized Deep Neural Networks
Jun 26, 2018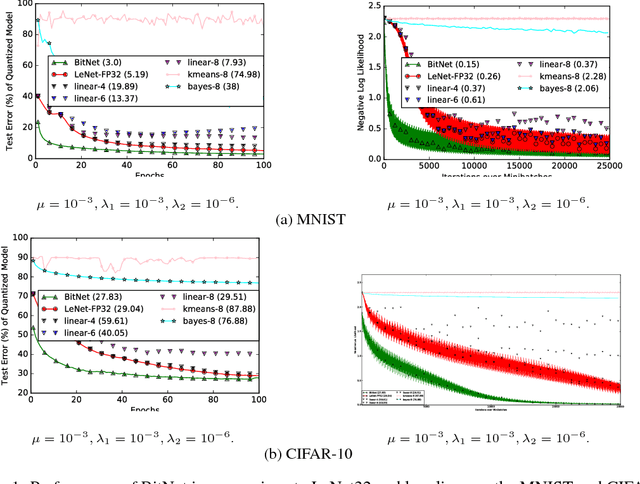
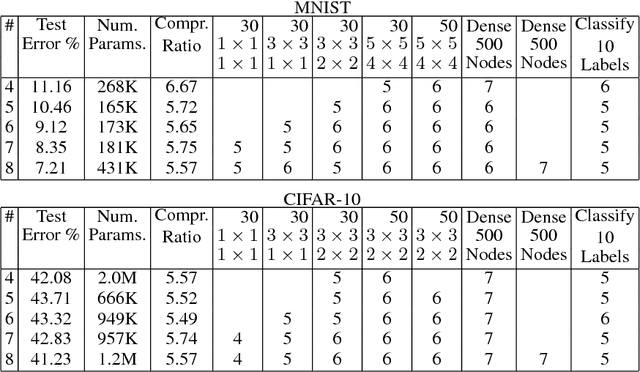
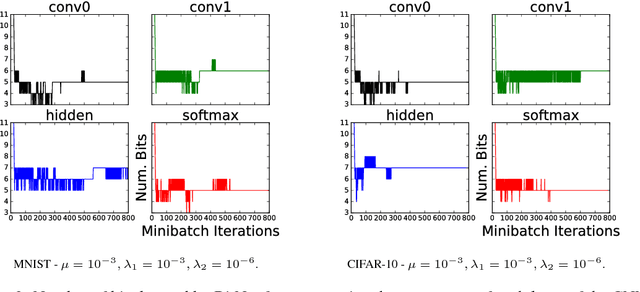
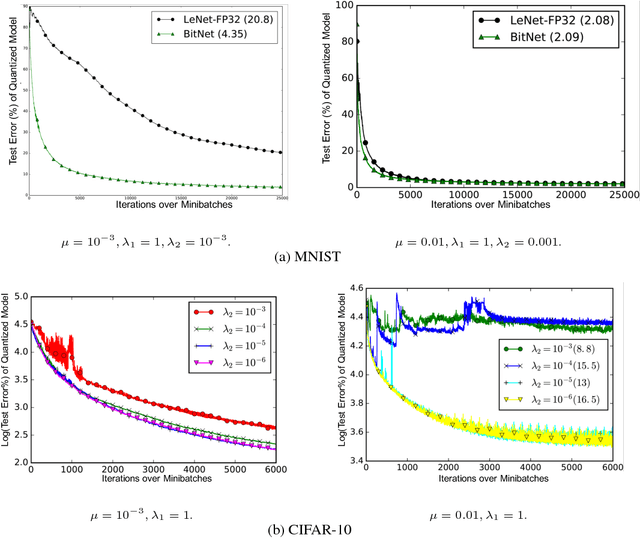
We present a novel optimization strategy for training neural networks which we call "BitNet". The parameters of neural networks are usually unconstrained and have a dynamic range dispersed over all real values. Our key idea is to limit the expressive power of the network by dynamically controlling the range and set of values that the parameters can take. We formulate this idea using a novel end-to-end approach that circumvents the discrete parameter space by optimizing a relaxed continuous and differentiable upper bound of the typical classification loss function. The approach can be interpreted as a regularization inspired by the Minimum Description Length (MDL) principle. For each layer of the network, our approach optimizes real-valued translation and scaling factors and arbitrary precision integer-valued parameters (weights). We empirically compare BitNet to an equivalent unregularized model on the MNIST and CIFAR-10 datasets. We show that BitNet converges faster to a superior quality solution. Additionally, the resulting model has significant savings in memory due to the use of integer-valued parameters.
GPU Activity Prediction using Representation Learning
Mar 27, 2017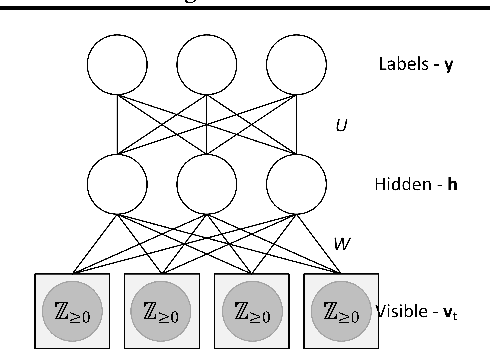
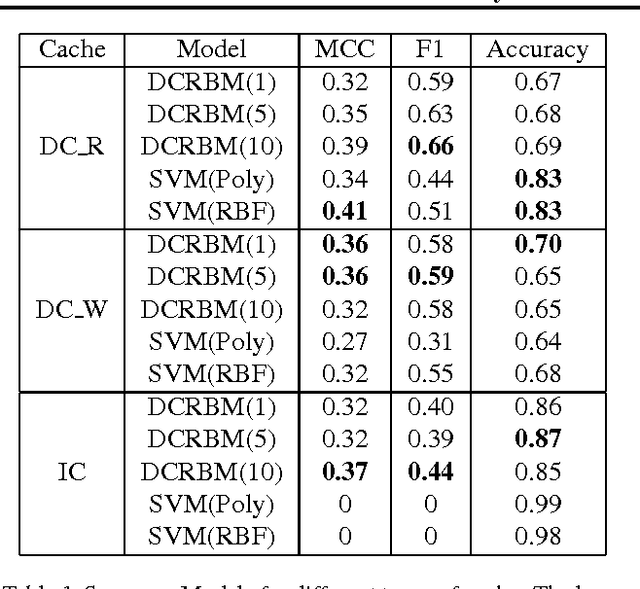

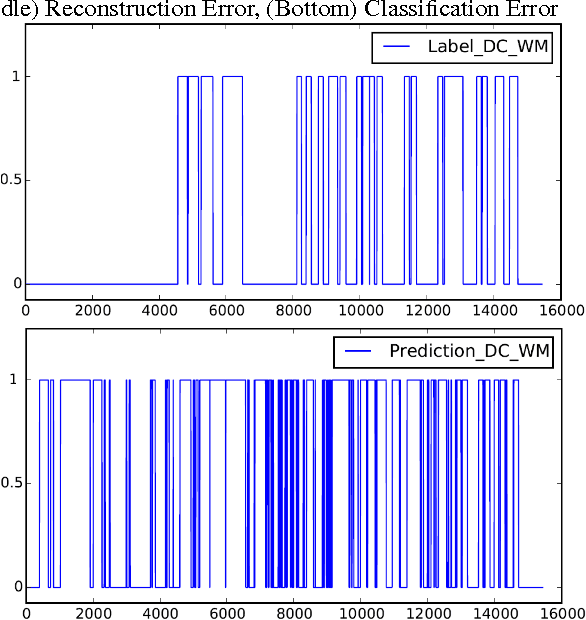
GPU activity prediction is an important and complex problem. This is due to the high level of contention among thousands of parallel threads. This problem was mostly addressed using heuristics. We propose a representation learning approach to address this problem. We model any performance metric as a temporal function of the executed instructions with the intuition that the flow of instructions can be identified as distinct activities of the code. Our experiments show high accuracy and non-trivial predictive power of representation learning on a benchmark.
Low Precision Neural Networks using Subband Decomposition
Mar 24, 2017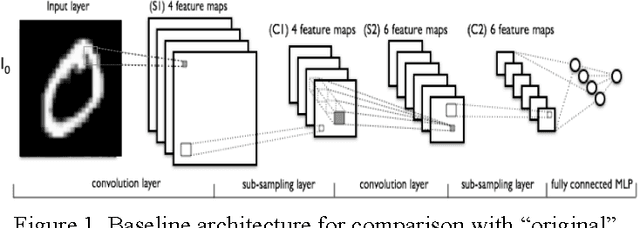
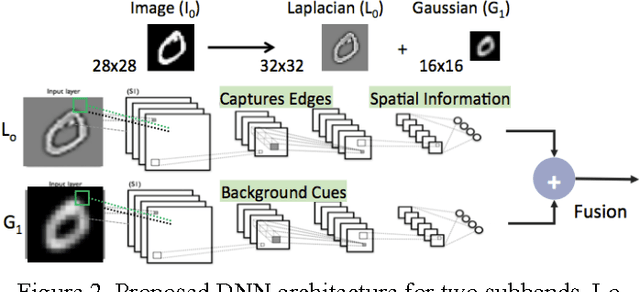
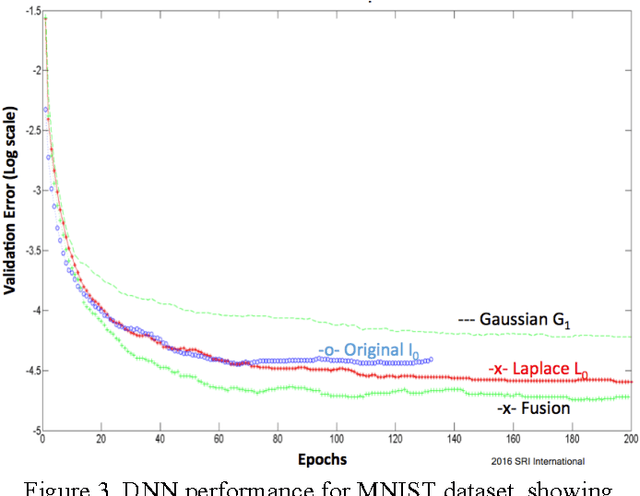
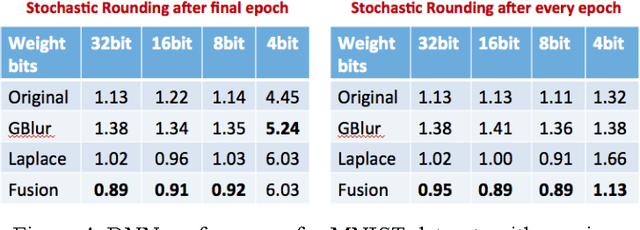
Large-scale deep neural networks (DNN) have been successfully used in a number of tasks from image recognition to natural language processing. They are trained using large training sets on large models, making them computationally and memory intensive. As such, there is much interest in research development for faster training and test time. In this paper, we present a unique approach using lower precision weights for more efficient and faster training phase. We separate imagery into different frequency bands (e.g. with different information content) such that the neural net can better learn using less bits. We present this approach as a complement existing methods such as pruning network connections and encoding learning weights. We show results where this approach supports more stable learning with 2-4X reduction in precision with 17X reduction in DNN parameters.