 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Tolerant Coreset-Based Class Incremental Continual Learning
Apr 23, 2025
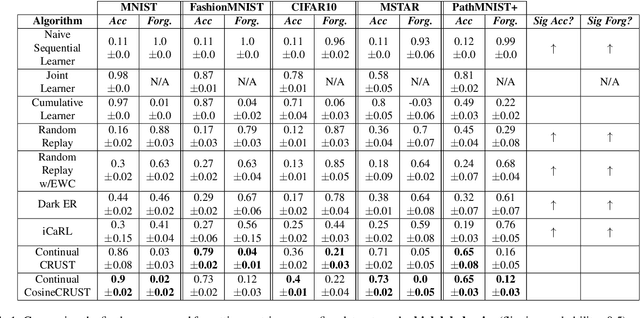
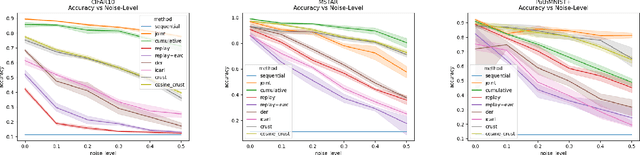
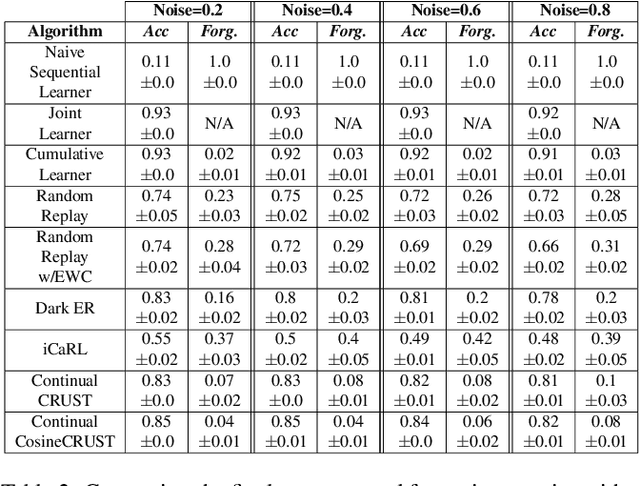
Many applications of computer vision require the ability to adapt to novel data distributions after deployment. Adaptation requires algorithms capable of continual learning (CL). Continual learners must be plastic to adapt to novel tasks while minimizing forgetting of previous tasks.However, CL opens up avenues for noise to enter the training pipeline and disrupt the CL. This work focuses on label noise and instance noise in the context of class-incremental learning (CIL), where new classes are added to a classifier over time, and there is no access to external data from past classes. We aim to understand the sensitivity of CL methods that work by replaying items from a memory constructed using the idea of Coresets. We derive a new bound for the robustness of such a method to uncorrelated instance noise under a general additive noise threat model, revealing several insights. Putting the theory into practice, we create two continual learning algorithms to construct noise-tolerant replay buffers. We empirically compare the effectiveness of prior memory-based continual learners and the proposed algorithms under label and uncorrelated instance noise on five diverse datasets. We show that existing memory-based CL are not robust whereas the proposed methods exhibit significant improvements in maximizing classification accuracy and minimizing forgetting in the noisy CIL setting.
Data-Driven Distributed Common Operational Picture from Heterogeneous Platforms using Multi-Agent Reinforcement Learning
Nov 08, 2024



The integration of unmanned platforms equipped with advanced sensors promises to enhance situational awareness and mitigate the "fog of war" in military operations. However, managing the vast influx of data from these platforms poses a significant challenge for Command and Control (C2) systems. This study presents a novel multi-agent learning framework to address this challenge. Our method enables autonomous and secure communication between agents and humans, which in turn enables real-time formation of an interpretable Common Operational Picture (COP). Each agent encodes its perceptions and actions into compact vectors, which are then transmitted, received and decoded to form a COP encompassing the current state of all agents (friendly and enemy) on the battlefield. Using Deep Reinforcement Learning (DRL), we jointly train COP models and agent's action selection policies. We demonstrate resilience to degraded conditions such as denied GPS and disrupted communications. Experimental validation is performed in the Starcraft-2 simulation environment to evaluate the precision of the COPs and robustness of policies. We report less than 5% error in COPs and policies resilient to various adversarial conditions. In summary, our contributions include a method for autonomous COP formation, increased resilience through distributed prediction, and joint training of COP models and multi-agent RL policies. This research advances adaptive and resilient C2, facilitating effective control of heterogeneous unmanned platforms.
Data-Driven Pixel Control: Challenges and Prospects
Aug 08, 2024
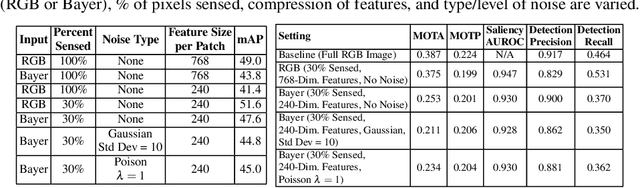
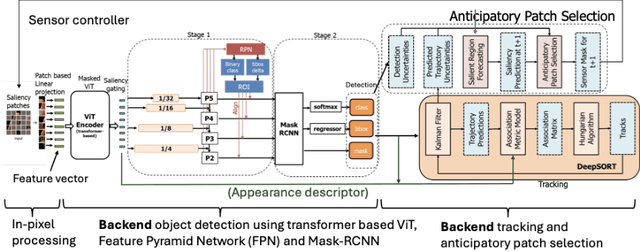

Recent advancements in sensors have led to high resolution and high data throughput at the pixel level. Simultaneously, the adoption of increasingly large (deep) neural networks (NNs) has lead to significant progress in computer vision. Currently, visual intelligence comes at increasingly high computational complexity, energy, and latency. We study a data-driven system that combines dynamic sensing at the pixel level with computer vision analytics at the video level and propose a feedback control loop to minimize data movement between the sensor front-end and computational back-end without compromising detection and tracking precision. Our contributions are threefold: (1) We introduce anticipatory attention and show that it leads to high precision prediction with sparse activation of pixels; (2) Leveraging the feedback control, we show that the dimensionality of learned feature vectors can be significantly reduced with increased sparsity; and (3) We emulate analog design choices (such as varying RGB or Bayer pixel format and analog noise) and study their impact on the key metrics of the data-driven system. Comparative analysis with traditional pixel and deep learning models shows significant performance enhancements. Our system achieves a 10X reduction in bandwidth and a 15-30X improvement in Energy-Delay Product (EDP) when activating only 30% of pixels, with a minor reduction in object detection and tracking precision. Based on analog emulation, our system can achieve a throughput of 205 megapixels/sec (MP/s) with a power consumption of only 110 mW per MP, i.e., a theoretical improvement of ~30X in EDP.
Improving the Robustness of Quantized Deep Neural Networks to White-Box Attacks using Stochastic Quantization and Information-Theoretic Ensemble Training
Nov 30, 2023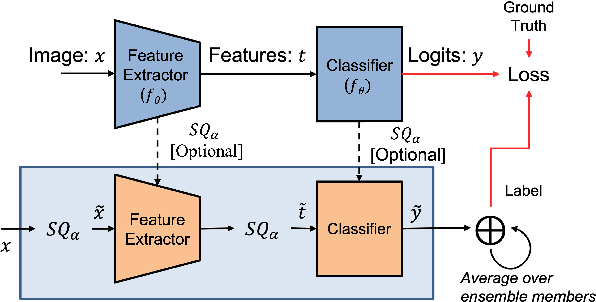



Most real-world applications that employ deep neural networks (DNNs) quantize them to low precision to reduce the compute needs. We present a method to improve the robustness of quantized DNNs to white-box adversarial attacks. We first tackle the limitation of deterministic quantization to fixed ``bins'' by introducing a differentiable Stochastic Quantizer (SQ). We explore the hypothesis that different quantizations may collectively be more robust than each quantized DNN. We formulate a training objective to encourage different quantized DNNs to learn different representations of the input image. The training objective captures diversity and accuracy via mutual information between ensemble members. Through experimentation, we demonstrate substantial improvement in robustness against $L_\infty$ attacks even if the attacker is allowed to backpropagate through SQ (e.g., > 50\% accuracy to PGD(5/255) on CIFAR10 without adversarial training), compared to vanilla DNNs as well as existing ensembles of quantized DNNs. We extend the method to detect attacks and generate robustness profiles in the adversarial information plane (AIP), towards a unified analysis of different threat models by correlating the MI and accuracy.
Enhancing Multi-Agent Coordination through Common Operating Picture Integration
Nov 08, 2023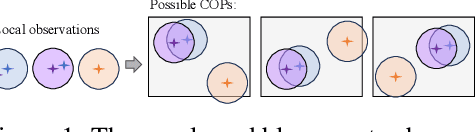
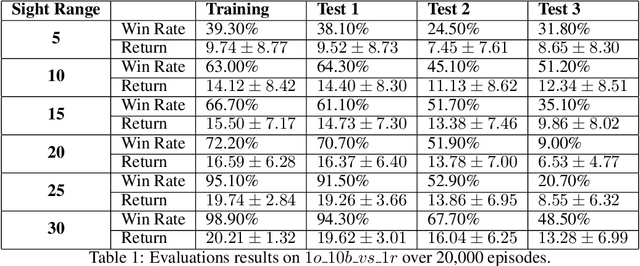
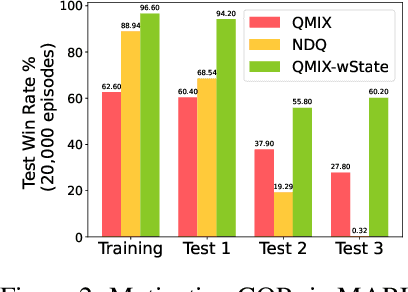

In multi-agent systems, agents possess only local observations of the environment. Communication between teammates becomes crucial for enhancing coordination. Past research has primarily focused on encoding local information into embedding messages which are unintelligible to humans. We find that using these messages in agent's policy learning leads to brittle policies when tested on out-of-distribution initial states. We present an approach to multi-agent coordination, where each agent is equipped with the capability to integrate its (history of) observations, actions and messages received into a Common Operating Picture (COP) and disseminate the COP. This process takes into account the dynamic nature of the environment and the shared mission. We conducted experiments in the StarCraft2 environment to validate our approach. Our results demonstrate the efficacy of COP integration, and show that COP-based training leads to robust policies compared to state-of-the-art Multi-Agent Reinforcement Learning (MARL) methods when faced with out-of-distribution initial states.
Efficient Model Adaptation for Continual Learning at the Edge
Aug 03, 2023



Most machine learning (ML) systems assume stationary and matching data distributions during training and deployment. This is often a false assumption. When ML models are deployed on real devices, data distributions often shift over time due to changes in environmental factors, sensor characteristics, and task-of-interest. While it is possible to have a human-in-the-loop to monitor for distribution shifts and engineer new architectures in response to these shifts, such a setup is not cost-effective. Instead, non-stationary automated ML (AutoML) models are needed. This paper presents the Encoder-Adaptor-Reconfigurator (EAR) framework for efficient continual learning under domain shifts. The EAR framework uses a fixed deep neural network (DNN) feature encoder and trains shallow networks on top of the encoder to handle novel data. The EAR framework is capable of 1) detecting when new data is out-of-distribution (OOD) by combining DNNs with hyperdimensional computing (HDC), 2) identifying low-parameter neural adaptors to adapt the model to the OOD data using zero-shot neural architecture search (ZS-NAS), and 3) minimizing catastrophic forgetting on previous tasks by progressively growing the neural architecture as needed and dynamically routing data through the appropriate adaptors and reconfigurators for handling domain-incremental and class-incremental continual learning. We systematically evaluate our approach on several benchmark datasets for domain adaptation and demonstrate strong performance compared to state-of-the-art algorithms for OOD detection and few-/zero-shot NAS.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023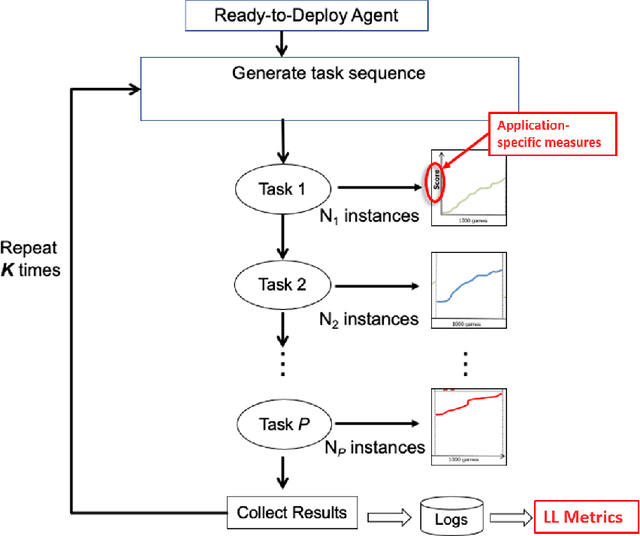
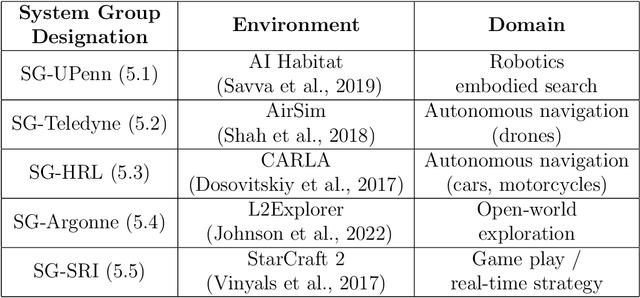


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
System Design for an Integrated Lifelong Reinforcement Learning Agent for Real-Time Strategy Games
Dec 08, 2022

As Artificial and Robotic Systems are increasingly deployed and relied upon for real-world applications, it is important that they exhibit the ability to continually learn and adapt in dynamically-changing environments, becoming Lifelong Learning Machines. Continual/lifelong learning (LL) involves minimizing catastrophic forgetting of old tasks while maximizing a model's capability to learn new tasks. This paper addresses the challenging lifelong reinforcement learning (L2RL) setting. Pushing the state-of-the-art forward in L2RL and making L2RL useful for practical applications requires more than developing individual L2RL algorithms; it requires making progress at the systems-level, especially research into the non-trivial problem of how to integrate multiple L2RL algorithms into a common framework. In this paper, we introduce the Lifelong Reinforcement Learning Components Framework (L2RLCF), which standardizes L2RL systems and assimilates different continual learning components (each addressing different aspects of the lifelong learning problem) into a unified system. As an instantiation of L2RLCF, we develop a standard API allowing easy integration of novel lifelong learning components. We describe a case study that demonstrates how multiple independently-developed LL components can be integrated into a single realized system. We also introduce an evaluation environment in order to measure the effect of combining various system components. Our evaluation environment employs different LL scenarios (sequences of tasks) consisting of Starcraft-2 minigames and allows for the fair, comprehensive, and quantitative comparison of different combinations of components within a challenging common evaluation environment.
Model-Free Generative Replay for Lifelong Reinforcement Learning: Application to Starcraft-2
Aug 16, 2022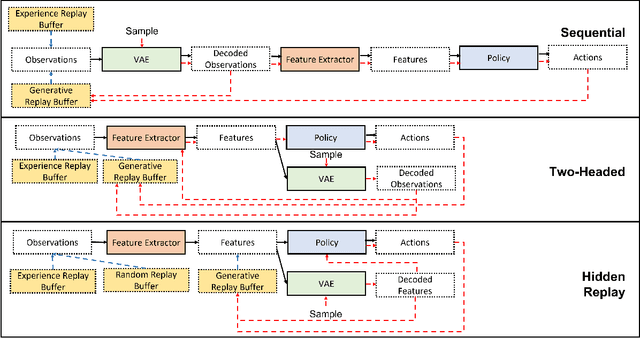

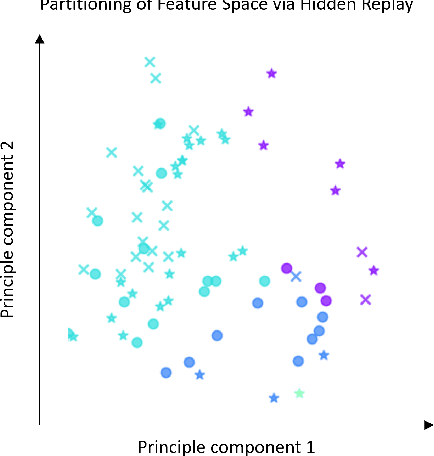

One approach to meet the challenges of deep lifelong reinforcement learning (LRL) is careful management of the agent's learning experiences, to learn (without forgetting) and build internal meta-models (of the tasks, environments, agents, and world). Generative replay (GR) is a biologically inspired replay mechanism that augments learning experiences with self-labelled examples drawn from an internal generative model that is updated over time. We present a version of GR for LRL that satisfies two desiderata: (a) Introspective density modelling of the latent representations of policies learned using deep RL, and (b) Model-free end-to-end learning. In this paper, we study three deep learning architectures for model-free GR, starting from a na\"ive GR and adding ingredients to achieve (a) and (b). We evaluate our proposed algorithms on three different scenarios comprising tasks from the Starcraft-2 and Minigrid domains. We report several key findings showing the impact of the design choices on quantitative metrics that include transfer learning, generalization to unseen tasks, fast adaptation after task change, performance wrt task expert, and catastrophic forgetting. We observe that our GR prevents drift in the features-to-action mapping from the latent vector space of a deep RL agent. We also show improvements in established lifelong learning metrics. We find that a small random replay buffer significantly increases the stability of training. Overall, we find that "hidden replay" (a well-known architecture for class-incremental classification) is the most promising approach that pushes the state-of-the-art in GR for LRL and observe that the architecture of the sleep model might be more important for improving performance than the types of replay used. Our experiments required only 6% of training samples to achieve 80-90% of expert performance in most Starcraft-2 scenarios.
Real-time Hyper-Dimensional Reconfiguration at the Edge using Hardware Accelerators
Jun 10, 2022
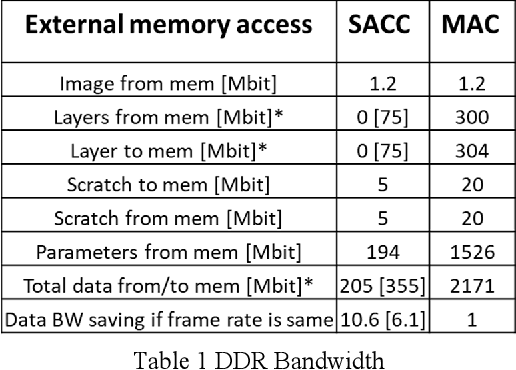
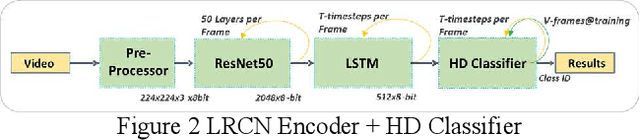
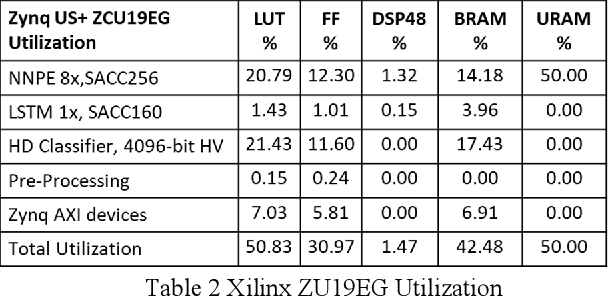
In this paper we present Hyper-Dimensional Reconfigurable Analytics at the Tactical Edge (HyDRATE) using low-SWaP embedded hardware that can perform real-time reconfiguration at the edge leveraging non-MAC (free of floating-point MultiplyACcumulate operations) deep neural nets (DNN) combined with hyperdimensional (HD) computing accelerators. We describe the algorithm, trained quantized model generation, and simulated performance of a feature extractor free of multiply-accumulates feeding a hyperdimensional logic-based classifier. Then we show how performance increases with the number of hyperdimensions. We describe the realized low-SWaP FPGA hardware and embedded software system compared to traditional DNNs and detail the implemented hardware accelerators. We discuss the measured system latency and power, noise robustness due to use of learnable quantization and HD computing, actual versus simulated system performance for a video activity classification task and demonstration of reconfiguration on this same dataset. We show that reconfigurability in the field is achieved by retraining only the feed-forward HD classifier without gradient descent backpropagation (gradient-free), using few-shot learning of new classes at the edge. Initial work performed used LRCN DNN and is currently extended to use Two-stream DNN with improved performance.