 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Shot Coordination for Sparse Reward Tasks with Diverse Reward Shapings
Apr 28, 2026Many Multi-Agent Reinforcement Learning (MARL) agents fail to adapt properly to cooperating with agents trained with the same objectives but different seeds, algorithms, or other training differences. This is the problem of Zero-Shot Coordination (ZSC), which focuses on training agents to cooperate well with unknown agents. ZSC has been studied for a variety of tabular cases and simple games such as Hanabi, achieving excellent results. However, existing solutions to ZSC only consider identical rewards for your trained agents and all future partners. This is not realistic for the trained agents, as they do not consider the problem of cooperating with agents that have identical sparse objectives but shape the rewards for those objectives in different manner. To address this issue, we show how to train an ensemble of methods using randomized reward shapings chosen using 4 selection algorithms. Experiments done on the Overcooked environment demonstrate consistent improvements of 62.2%-119.2% in sparse reward over baseline ZSC algorithms when playing with agents that have identical sparse rewards but different reward shapings.
VARP: Reinforcement Learning from Vision-Language Model Feedback with Agent Regularized Preferences
Mar 18, 2025Designing reward functions for continuous-control robotics often leads to subtle misalignments or reward hacking, especially in complex tasks. Preference-based RL mitigates some of these pitfalls by learning rewards from comparative feedback rather than hand-crafted signals, yet scaling human annotations remains challenging. Recent work uses Vision-Language Models (VLMs) to automate preference labeling, but a single final-state image generally fails to capture the agent's full motion. In this paper, we present a two-part solution that both improves feedback accuracy and better aligns reward learning with the agent's policy. First, we overlay trajectory sketches on final observations to reveal the path taken, allowing VLMs to provide more reliable preferences-improving preference accuracy by approximately 15-20% in metaworld tasks. Second, we regularize reward learning by incorporating the agent's performance, ensuring that the reward model is optimized based on data generated by the current policy; this addition boosts episode returns by 20-30% in locomotion tasks. Empirical studies on metaworld demonstrate that our method achieves, for instance, around 70-80% success rate in all tasks, compared to below 50% for standard approaches. These results underscore the efficacy of combining richer visual representations with agent-aware reward regularization.
Sketch-to-Skill: Bootstrapping Robot Learning with Human Drawn Trajectory Sketches
Mar 14, 2025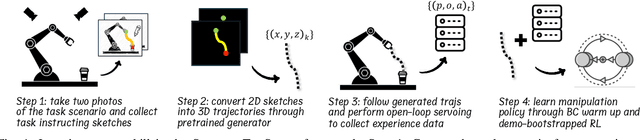
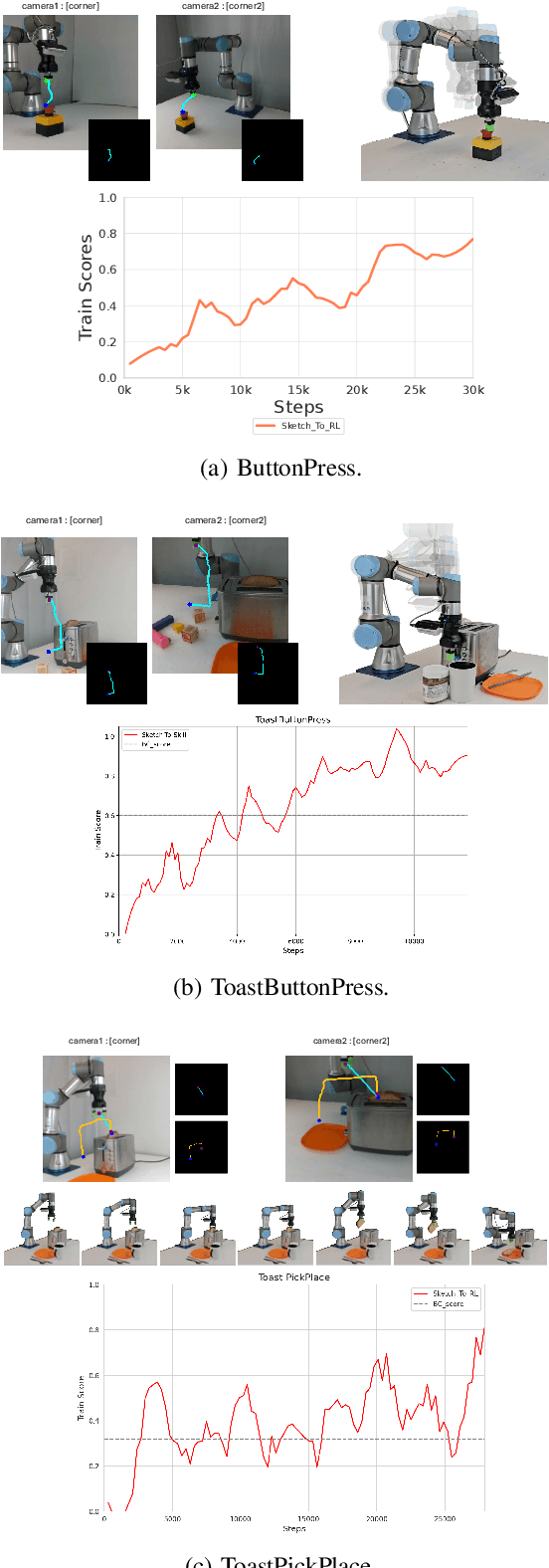
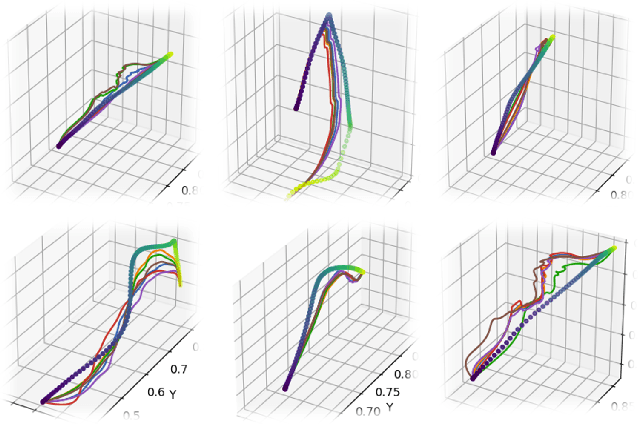
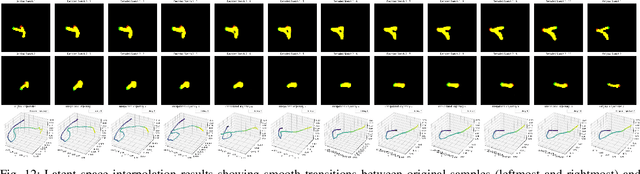
Training robotic manipulation policies traditionally requires numerous demonstrations and/or environmental rollouts. While recent Imitation Learning (IL) and Reinforcement Learning (RL) methods have reduced the number of required demonstrations, they still rely on expert knowledge to collect high-quality data, limiting scalability and accessibility. We propose Sketch-to-Skill, a novel framework that leverages human-drawn 2D sketch trajectories to bootstrap and guide RL for robotic manipulation. Our approach extends beyond previous sketch-based methods, which were primarily focused on imitation learning or policy conditioning, limited to specific trained tasks. Sketch-to-Skill employs a Sketch-to-3D Trajectory Generator that translates 2D sketches into 3D trajectories, which are then used to autonomously collect initial demonstrations. We utilize these sketch-generated demonstrations in two ways: to pre-train an initial policy through behavior cloning and to refine this policy through RL with guided exploration. Experimental results demonstrate that Sketch-to-Skill achieves ~96% of the performance of the baseline model that leverages teleoperated demonstration data, while exceeding the performance of a pure reinforcement learning policy by ~170%, only from sketch inputs. This makes robotic manipulation learning more accessible and potentially broadens its applications across various domains.
On the Sample Complexity of a Policy Gradient Algorithm with Occupancy Approximation for General Utility Reinforcement Learning
Oct 05, 2024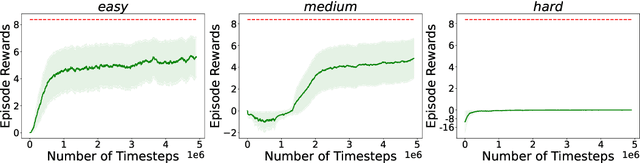
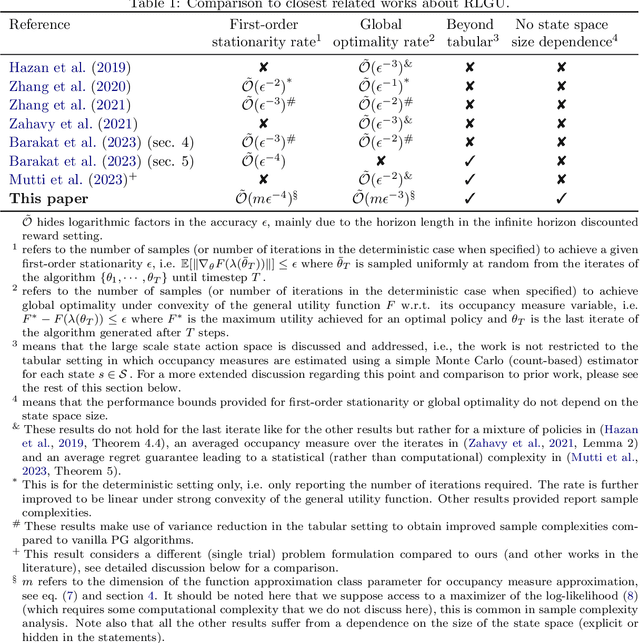
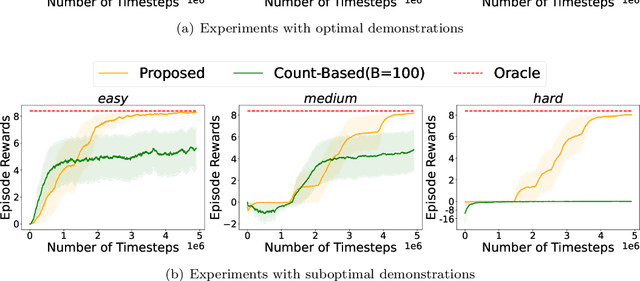
Reinforcement learning with general utilities has recently gained attention thanks to its ability to unify several problems, including imitation learning, pure exploration, and safe RL. However, prior work for solving this general problem in a unified way has mainly focused on the tabular setting. This is restrictive when considering larger state-action spaces because of the need to estimate occupancy measures during policy optimization. In this work, we address this issue and propose to approximate occupancy measures within a function approximation class using maximum likelihood estimation (MLE). We propose a simple policy gradient algorithm (PG-OMA) where an actor updates the policy parameters to maximize the general utility objective whereas a critic approximates the occupancy measure using MLE. We provide a sample complexity analysis of PG-OMA showing that our occupancy measure estimation error only scales with the dimension of our function approximation class rather than the size of the state action space. Under suitable assumptions, we establish first order stationarity and global optimality performance bounds for the proposed PG-OMA algorithm for nonconcave and concave general utilities respectively. We complement our methodological and theoretical findings with promising empirical results showing the scalability potential of our approach compared to existing tabular count-based approaches.
Beyond Joint Demonstrations: Personalized Expert Guidance for Efficient Multi-Agent Reinforcement Learning
Mar 13, 2024



Multi-Agent Reinforcement Learning (MARL) algorithms face the challenge of efficient exploration due to the exponential increase in the size of the joint state-action space. While demonstration-guided learning has proven beneficial in single-agent settings, its direct applicability to MARL is hindered by the practical difficulty of obtaining joint expert demonstrations. In this work, we introduce a novel concept of personalized expert demonstrations, tailored for each individual agent or, more broadly, each individual type of agent within a heterogeneous team. These demonstrations solely pertain to single-agent behaviors and how each agent can achieve personal goals without encompassing any cooperative elements, thus naively imitating them will not achieve cooperation due to potential conflicts. To this end, we propose an approach that selectively utilizes personalized expert demonstrations as guidance and allows agents to learn to cooperate, namely personalized expert-guided MARL (PegMARL). This algorithm utilizes two discriminators: the first provides incentives based on the alignment of policy behavior with demonstrations, and the second regulates incentives based on whether the behavior leads to the desired objective. We evaluate PegMARL using personalized demonstrations in both discrete and continuous environments. The results demonstrate that PegMARL learns near-optimal policies even when provided with suboptimal demonstrations, and outperforms state-of-the-art MARL algorithms in solving coordinated tasks. We also showcase PegMARL's capability to leverage joint demonstrations in the StarCraft scenario and converge effectively even with demonstrations from non-co-trained policies.
Enhancing Multi-Agent Coordination through Common Operating Picture Integration
Nov 08, 2023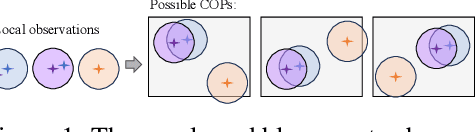
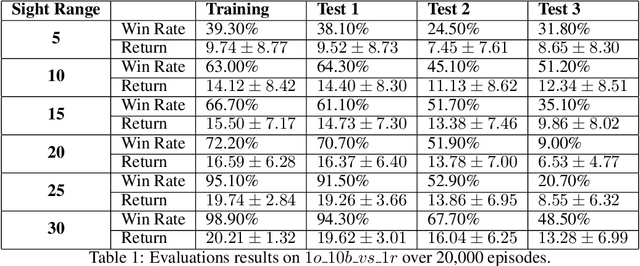
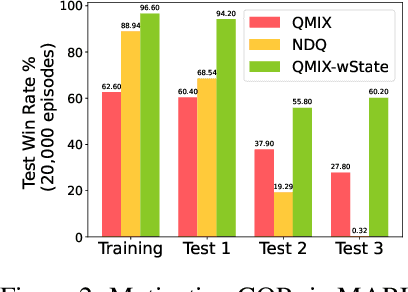

In multi-agent systems, agents possess only local observations of the environment. Communication between teammates becomes crucial for enhancing coordination. Past research has primarily focused on encoding local information into embedding messages which are unintelligible to humans. We find that using these messages in agent's policy learning leads to brittle policies when tested on out-of-distribution initial states. We present an approach to multi-agent coordination, where each agent is equipped with the capability to integrate its (history of) observations, actions and messages received into a Common Operating Picture (COP) and disseminate the COP. This process takes into account the dynamic nature of the environment and the shared mission. We conducted experiments in the StarCraft2 environment to validate our approach. Our results demonstrate the efficacy of COP integration, and show that COP-based training leads to robust policies compared to state-of-the-art Multi-Agent Reinforcement Learning (MARL) methods when faced with out-of-distribution initial states.
Insta-RS: Instance-wise Randomized Smoothing for Improved Robustness and Accuracy
Mar 21, 2021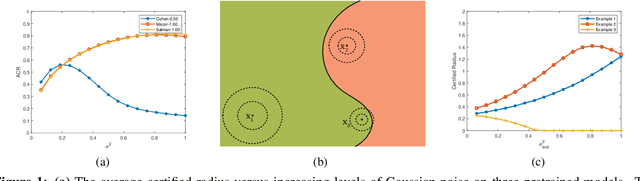


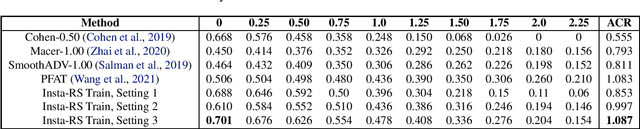
Randomized smoothing (RS) is an effective and scalable technique for constructing neural network classifiers that are certifiably robust to adversarial perturbations. Most RS works focus on training a good base model that boosts the certified robustness of the smoothed model. However, existing RS techniques treat every data point the same, i.e., the variance of the Gaussian noise used to form the smoothed model is preset and universal for all training and test data. This preset and universal Gaussian noise variance is suboptimal since different data points have different margins and the local properties of the base model vary across the input examples. In this paper, we examine the impact of customized handling of examples and propose Instance-wise Randomized Smoothing (Insta-RS) -- a multiple-start search algorithm that assigns customized Gaussian variances to test examples. We also design Insta-RS Train -- a novel two-stage training algorithm that adaptively adjusts and customizes the noise level of each training example for training a base model that boosts the certified robustness of the instance-wise Gaussian smoothed model. Through extensive experiments on CIFAR-10 and ImageNet, we show that our method significantly enhances the average certified radius (ACR) as well as the clean data accuracy compared to existing state-of-the-art provably robust classifiers.