 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFFORD2ACT: Affordance-Guided Automatic Keypoint Selection for Generalizable and Lightweight Robotic Manipulation
Oct 01, 2025Vision-based robot learning often relies on dense image or point-cloud inputs, which are computationally heavy and entangle irrelevant background features. Existing keypoint-based approaches can focus on manipulation-centric features and be lightweight, but either depend on manual heuristics or task-coupled selection, limiting scalability and semantic understanding. To address this, we propose AFFORD2ACT, an affordance-guided framework that distills a minimal set of semantic 2D keypoints from a text prompt and a single image. AFFORD2ACT follows a three-stage pipeline: affordance filtering, category-level keypoint construction, and transformer-based policy learning with embedded gating to reason about the most relevant keypoints, yielding a compact 38-dimensional state policy that can be trained in 15 minutes, which performs well in real-time without proprioception or dense representations. Across diverse real-world manipulation tasks, AFFORD2ACT consistently improves data efficiency, achieving an 82% success rate on unseen objects, novel categories, backgrounds, and distractors.
VARP: Reinforcement Learning from Vision-Language Model Feedback with Agent Regularized Preferences
Mar 18, 2025Designing reward functions for continuous-control robotics often leads to subtle misalignments or reward hacking, especially in complex tasks. Preference-based RL mitigates some of these pitfalls by learning rewards from comparative feedback rather than hand-crafted signals, yet scaling human annotations remains challenging. Recent work uses Vision-Language Models (VLMs) to automate preference labeling, but a single final-state image generally fails to capture the agent's full motion. In this paper, we present a two-part solution that both improves feedback accuracy and better aligns reward learning with the agent's policy. First, we overlay trajectory sketches on final observations to reveal the path taken, allowing VLMs to provide more reliable preferences-improving preference accuracy by approximately 15-20% in metaworld tasks. Second, we regularize reward learning by incorporating the agent's performance, ensuring that the reward model is optimized based on data generated by the current policy; this addition boosts episode returns by 20-30% in locomotion tasks. Empirical studies on metaworld demonstrate that our method achieves, for instance, around 70-80% success rate in all tasks, compared to below 50% for standard approaches. These results underscore the efficacy of combining richer visual representations with agent-aware reward regularization.
Sketch-to-Skill: Bootstrapping Robot Learning with Human Drawn Trajectory Sketches
Mar 14, 2025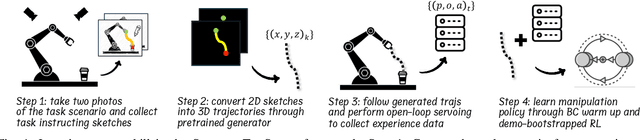
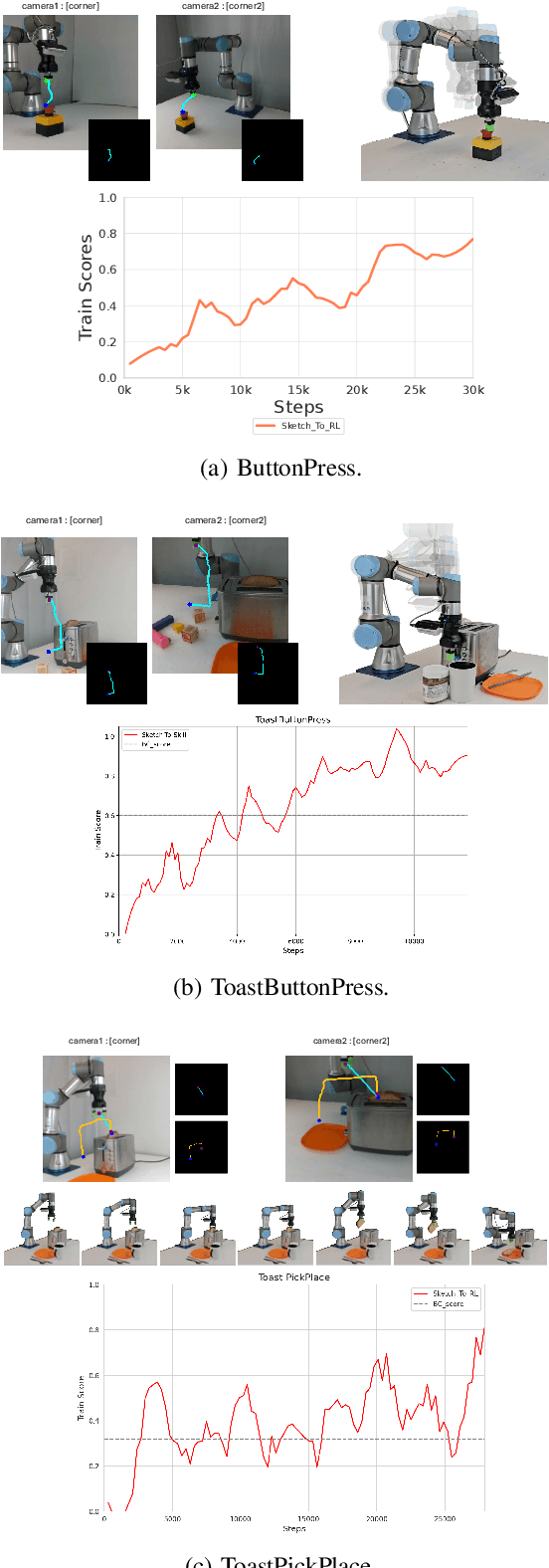
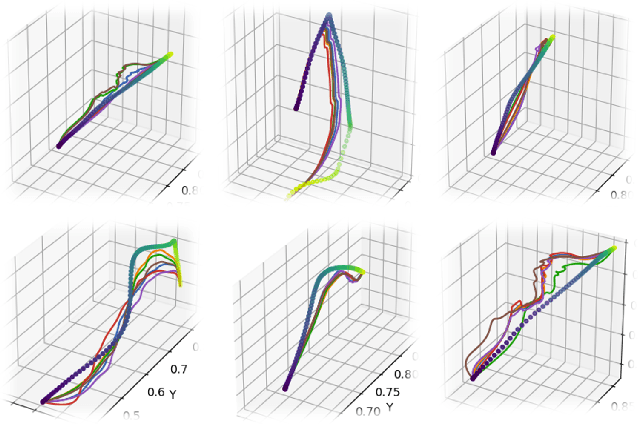
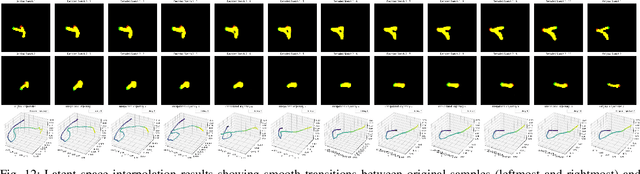
Training robotic manipulation policies traditionally requires numerous demonstrations and/or environmental rollouts. While recent Imitation Learning (IL) and Reinforcement Learning (RL) methods have reduced the number of required demonstrations, they still rely on expert knowledge to collect high-quality data, limiting scalability and accessibility. We propose Sketch-to-Skill, a novel framework that leverages human-drawn 2D sketch trajectories to bootstrap and guide RL for robotic manipulation. Our approach extends beyond previous sketch-based methods, which were primarily focused on imitation learning or policy conditioning, limited to specific trained tasks. Sketch-to-Skill employs a Sketch-to-3D Trajectory Generator that translates 2D sketches into 3D trajectories, which are then used to autonomously collect initial demonstrations. We utilize these sketch-generated demonstrations in two ways: to pre-train an initial policy through behavior cloning and to refine this policy through RL with guided exploration. Experimental results demonstrate that Sketch-to-Skill achieves ~96% of the performance of the baseline model that leverages teleoperated demonstration data, while exceeding the performance of a pure reinforcement learning policy by ~170%, only from sketch inputs. This makes robotic manipulation learning more accessible and potentially broadens its applications across various domains.
REBEL: A Regularization-Based Solution for Reward Overoptimization in Reinforcement Learning from Human Feedback
Dec 22, 2023



In this work, we propose REBEL, an algorithm for sample efficient reward regularization based robotic reinforcement learning from human feedback (RRLHF). Reinforcement learning (RL) performance for continuous control robotics tasks is sensitive to the underlying reward function. In practice, the reward function often ends up misaligned with human intent, values, social norms, etc., leading to catastrophic failures in the real world. We leverage human preferences to learn regularized reward functions and eventually align the agents with the true intended behavior. We introduce a novel notion of reward regularization to the existing RRLHF framework, which is termed as agent preferences. So, we not only consider human feedback in terms of preferences, we also propose to take into account the preference of the underlying RL agent while learning the reward function. We show that this helps to improve the over-optimization associated with the design of reward functions in RL. We experimentally show that REBEL exhibits up to 70% improvement in sample efficiency to achieve a similar level of episodic reward returns as compared to the state-of-the-art methods such as PEBBLE and PEBBLE+SURF.
Pre-Trained Masked Image Model for Mobile Robot Navigation
Oct 10, 20232D top-down maps are commonly used for the navigation and exploration of mobile robots through unknown areas. Typically, the robot builds the navigation maps incrementally from local observations using onboard sensors. Recent works have shown that predicting the structural patterns in the environment through learning-based approaches can greatly enhance task efficiency. While many such works build task-specific networks using limited datasets, we show that the existing foundational vision networks can accomplish the same without any fine-tuning. Specifically, we use Masked Autoencoders, pre-trained on street images, to present novel applications for field-of-view expansion, single-agent topological exploration, and multi-agent exploration for indoor mapping, across different input modalities. Our work motivates the use of foundational vision models for generalized structure prediction-driven applications, especially in the dearth of training data. For more qualitative results see https://raaslab.org/projects/MIM4Robots.
SeMask: Semantically Masked Transformers for Semantic Segmentation
Dec 23, 2021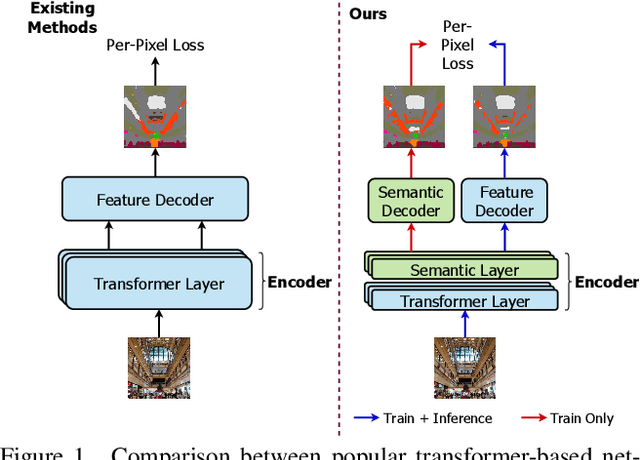
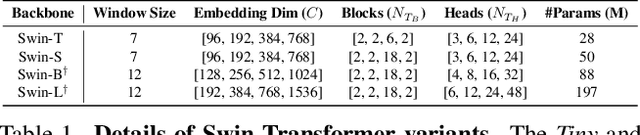
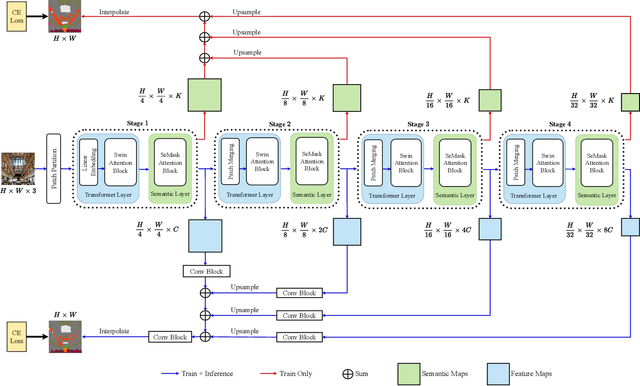
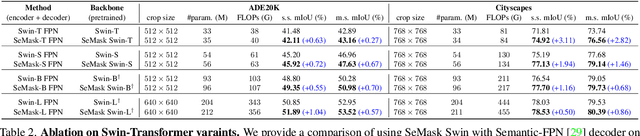
Finetuning a pretrained backbone in the encoder part of an image transformer network has been the traditional approach for the semantic segmentation task. However, such an approach leaves out the semantic context that an image provides during the encoding stage. This paper argues that incorporating semantic information of the image into pretrained hierarchical transformer-based backbones while finetuning improves the performance considerably. To achieve this, we propose SeMask, a simple and effective framework that incorporates semantic information into the encoder with the help of a semantic attention operation. In addition, we use a lightweight semantic decoder during training to provide supervision to the intermediate semantic prior maps at every stage. Our experiments demonstrate that incorporating semantic priors enhances the performance of the established hierarchical encoders with a slight increase in the number of FLOPs. We provide empirical proof by integrating SeMask into each variant of the Swin-Transformer as our encoder paired with different decoders. Our framework achieves a new state-of-the-art of 58.22% mIoU on the ADE20K dataset and improvements of over 3% in the mIoU metric on the Cityscapes dataset. The code and checkpoints are publicly available at https://github.com/Picsart-AI-Research/SeMask-Segmentation .
OffRoadTranSeg: Semi-Supervised Segmentation using Transformers on OffRoad environments
Jun 26, 2021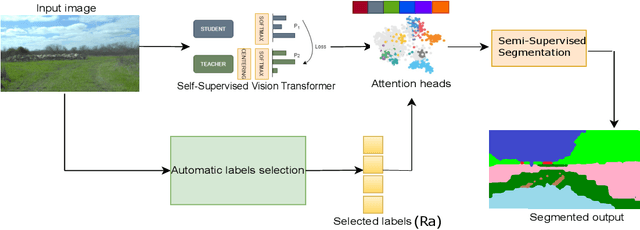
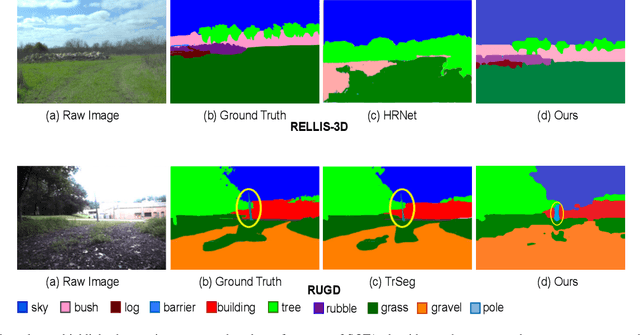
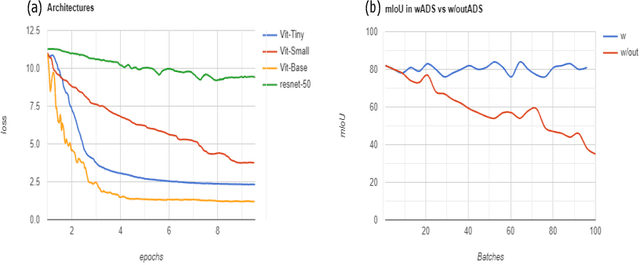
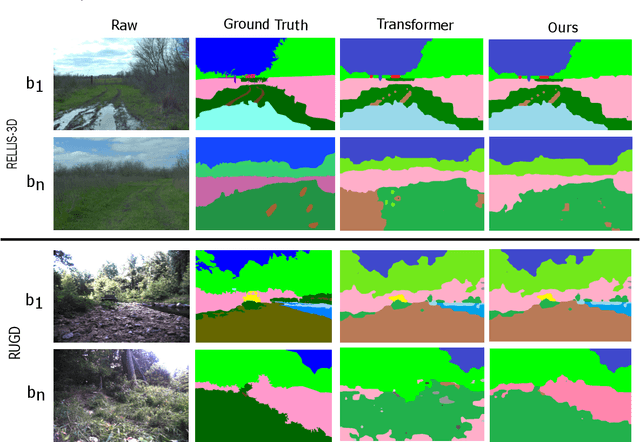
We present OffRoadTranSeg, the first end-to-end framework for semi-supervised segmentation in unstructured outdoor environment using transformers and automatic data selection for labelling. The offroad segmentation is a scene understanding approach that is widely used in autonomous driving. The popular offroad segmentation method is to use fully connected convolution layers and large labelled data, however, due to class imbalance, there will be several mismatches and also some classes may not be detected. Our approach is to do the task of offroad segmentation in a semi-supervised manner. The aim is to provide a model where self supervised vision transformer is used to fine-tune offroad datasets with self-supervised data collection for labelling using depth estimation. The proposed method is validated on RELLIS-3D and RUGD offroad datasets. The experiments show that OffRoadTranSeg outperformed other state of the art models, and also solves the RELLIS-3D class imbalance problem.