 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCART: Context-Aware Terrain Adaptation using Temporal Sequence Selection for Legged Robots
Apr 15, 2026Animals in nature combine multiple modalities, such as sight and feel, to perceive terrain and develop an understanding of how to walk on uneven terrain in a stable manner. Similarly, legged robots need to develop their ability to stably walk on complex terrains by developing an understanding of the relationship between vision and proprioception. Most current terrain adaptation methods are susceptible to failure on complex, off-road terrain as they rely on prior experience, particularly observations from a vision sensor. This experience-based learning often creates a Visual-Texture Paradox between what has been seen and how it actually feels. In this work, we introduce CART, a high-level controller built on a context-aware terrain adaptation approach that integrates proprioception and exteroception from onboard sensing to achieve a robust understanding of terrain. We evaluate our method on multiple terrains using an ANYmal-C robot on the IsaacSim simulator and a Boston Dynamics SPOT robot for our real-world experiments. To evaluate the learned contextual terrain properties, we adapt vibrational stability on the base of the robot as a metric. We compare CART with various state-of-the-art baselines equipped with multimodal sensing in both simulation and the real world. CART achieves an average success rate improvement of 5% over all baselines in simulation and improves the overall stability up to 45% and 24% in the real world without increasing the time taken by the robot to accomplish locomotion tasks.
PANOS: Payload-Aware Navigation in Offroad Scenarios
Sep 25, 2024



Nature has evolved humans to walk on different terrains by developing a detailed understanding of their physical characteristics. Similarly, legged robots need to develop their capability to walk on complex terrains with a variety of task-dependent payloads to achieve their goals. However, conventional terrain adaptation methods are susceptible to failure with varying payloads. In this work, we introduce PANOS, a weakly supervised approach that integrates proprioception and exteroception from onboard sensing to achieve a stable gait while walking by a legged robot over various terrains. Our work also provides evidence of its adaptability over varying payloads. We evaluate our method on multiple terrains and payloads using a legged robot. PANOS improves the stability up to 44% without any payload and 53% with 15 lbs payload. We also notice a reduction in the vibration cost of 20% with the payload for various terrain types when compared to state-of-the-art methods.
l-dyno: framework to learn consistent visual features using robot's motion
Oct 10, 2023



Historically, feature-based approaches have been used extensively for camera-based robot perception tasks such as localization, mapping, tracking, and others. Several of these approaches also combine other sensors (inertial sensing, for example) to perform combined state estimation. Our work rethinks this approach; we present a representation learning mechanism that identifies visual features that best correspond to robot motion as estimated by an external signal. Specifically, we utilize the robot's transformations through an external signal (inertial sensing, for example) and give attention to image space that is most consistent with the external signal. We use a pairwise consistency metric as a representation to keep the visual features consistent through a sequence with the robot's relative pose transformations. This approach enables us to incorporate information from the robot's perspective instead of solely relying on the image attributes. We evaluate our approach on real-world datasets such as KITTI & EuRoC and compare the refined features with existing feature descriptors. We also evaluate our method using our real robot experiment. We notice an average of 49% reduction in the image search space without compromising the trajectory estimation accuracy. Our method reduces the execution time of visual odometry by 4.3% and also reduces reprojection errors. We demonstrate the need to select only the most important features and show the competitiveness using various feature detection baselines.
OffRoadTranSeg: Semi-Supervised Segmentation using Transformers on OffRoad environments
Jun 26, 2021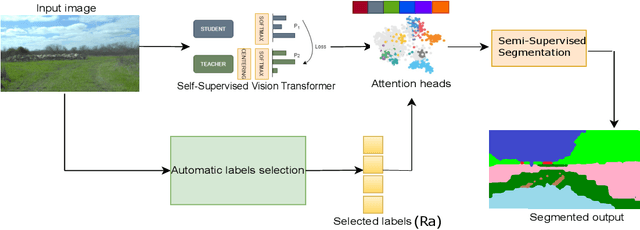
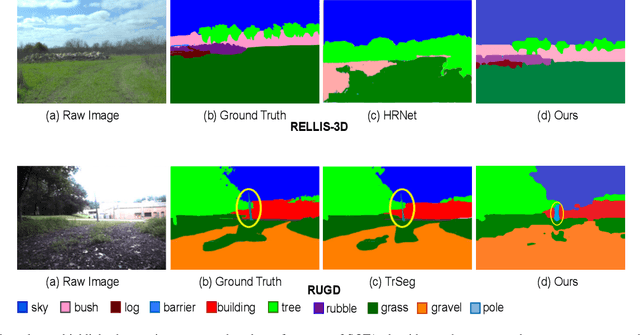
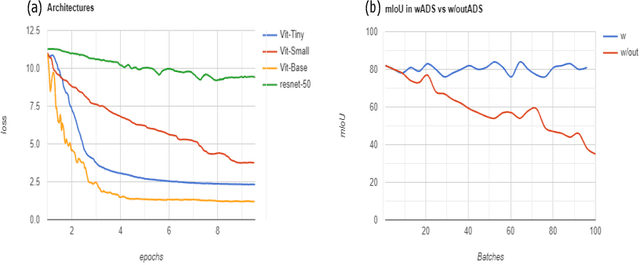
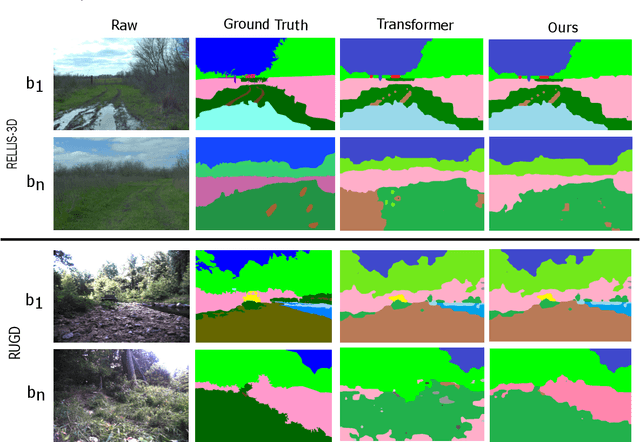
We present OffRoadTranSeg, the first end-to-end framework for semi-supervised segmentation in unstructured outdoor environment using transformers and automatic data selection for labelling. The offroad segmentation is a scene understanding approach that is widely used in autonomous driving. The popular offroad segmentation method is to use fully connected convolution layers and large labelled data, however, due to class imbalance, there will be several mismatches and also some classes may not be detected. Our approach is to do the task of offroad segmentation in a semi-supervised manner. The aim is to provide a model where self supervised vision transformer is used to fine-tune offroad datasets with self-supervised data collection for labelling using depth estimation. The proposed method is validated on RELLIS-3D and RUGD offroad datasets. The experiments show that OffRoadTranSeg outperformed other state of the art models, and also solves the RELLIS-3D class imbalance problem.
OFFSEG: A Semantic Segmentation Framework For Off-Road Driving
Mar 23, 2021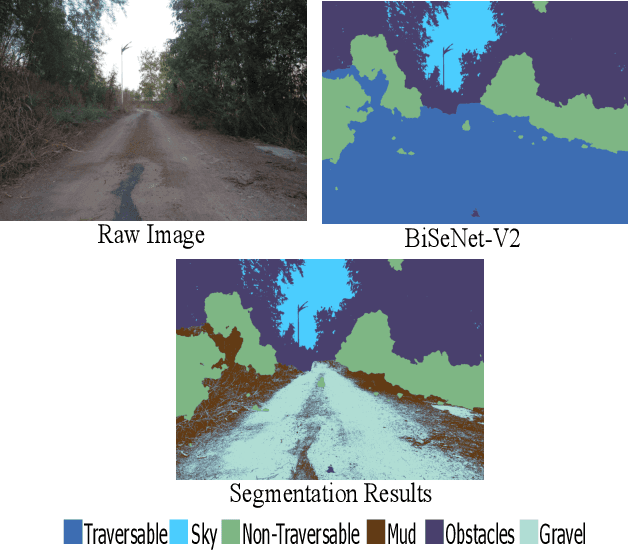
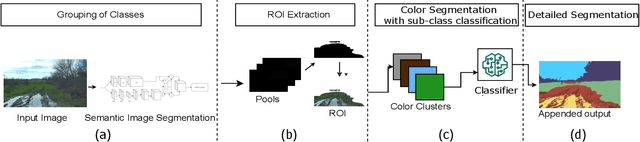


Off-road image semantic segmentation is challenging due to the presence of uneven terrains, unstructured class boundaries, irregular features and strong textures. These aspects affect the perception of the vehicle from which the information is used for path planning. Current off-road datasets exhibit difficulties like class imbalance and understanding of varying environmental topography. To overcome these issues we propose a framework for off-road semantic segmentation called as OFFSEG that involves (i) a pooled class semantic segmentation with four classes (sky, traversable region, non-traversable region and obstacle) using state-of-the-art deep learning architectures (ii) a colour segmentation methodology to segment out specific sub-classes (grass, puddle, dirt, gravel, etc.) from the traversable region for better scene understanding. The evaluation of the framework is carried out on two off-road driving datasets, namely, RELLIS-3D and RUGD. We have also tested proposed framework in IISERB campus frames. The results show that OFFSEG achieves good performance and also provides detailed information on the traversable region.